目录:
大数据解决四大核心问题:
-
数据的存储(Big Data Storage),海量数据需要处理和分析,但前提是要进行有效的存储。Hadoop的诞生突破了传统数据文件系统的单机模式。HDFS使得数据可以跨越不同的机器与设备,并且用一个路径去管理不同平台上的数据。
-
数据的计算(Data Calculation),在数据有效存储的基础上,对数据的统计和分析本质上就是数据的计算。在大数据领域常见的计算工具有MapReduce、Spark等。
-
数据的查询(Consensus Data),对大数据进行有效管理的核心指标是数据查询技术。其中NoSQL (Not Only SQL)应用较为广泛,能较有效解决数据的随机查询,其中就主要包括Hbase等。从本质而言,依旧是Hadoop模式下的数据查询。
-
数据的挖掘(Data mining),Hive数据仓库为数据的挖掘提供了基础,通过分类、预测、相关性分析来建立模型进行模式识别、机器学习从而构建专家系统。
Hadoop之父


大牛,他是Lucene、Nutch 、Hadoop等项目的发起人。是他,把高深莫测的搜索技术形成产品,贡献给普通大众;还是他,打造了在云计算和大数据领域里如日中天的Hadoop。他是某种意义上的盗火者(普罗米修斯盗火造福人类),他就是Doug Cutting。
Hadoop是项目的总称。主要是由HDFS和MapReduce组成。HDFS是Google File System(GFS)的开源实现。MapReduce是Google MapReduce的开源实现。
Hadoop的诞生突破了传统数据文件系统的单机模式。使得数据可以跨越不同的机器与设备,并且用一个路径去管理不同平台上的数据。
MapReduce的计算模型分为Map和Reduce两个过程。在日常经验里,我们统计数据需要分类,分类越细、参与统计的人数越多,计算的时间就越短,这就是Map的形象比喻,在大数据计算中,成百上千台机器同时读取目标文件的各个部分,然后对每个部分的统计量进行计算,Map就是负责这一工作的;而Reduce就是对分类计数之后的合计,是大数据计算的第二阶段。可见,数据的计算过程就是在HDFS基础上进行分类汇总。
HDFS把节点分成两类:NameNode和DataNode。NameNode是唯一的,程序与之通信,然后从DataNode上存取文件。这些操作是透明的,与普通的文件系统API没有区别。
MapReduce则是JobTracker节点为主,分配工作以及负责和用户程序通信。
HDFS和MapReduce实现是完全分离的,并不是没有HDFS就不能MapReduce运算。
Hadoop也跟其他云计算项目有共同点和目标:实现海量数据的计算。而进行海量计算需要一个稳定的,安全的数据容器,才有了Hadoop分布式文件系统(HDFS,Hadoop Distributed File System)。
HDFS通信部分使用org.apache.hadoop.ipc,可以很快使用RPC.Server.start()构造一个节点,具体业务功能还需自己实现。针对HDFS的业务则为数据流的读写,NameNode/DataNode的通信等。
MapReduce主要在org.apache.hadoop.mapred,实现提供的接口类,并完成节点通信(可以不是hadoop通信接口),就能进行MapReduce运算。
集群规划:
|
主机名 |
IP |
进程(jps) |
|
hadoop01 |
192.168.163.129 |
ZooKeeper(QuorumPeerMain) Hadoop HDFS Flume Hive |
|
hadoop02 |
192.168.163.130 |
ZooKeeper(QuorumPeerMain) |
|
hadoop03 |
192.168.163.131 |
ZooKeeper(QuorumPeerMain) |
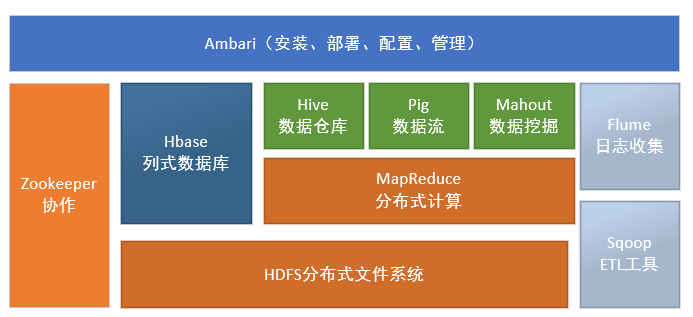

子项目
Hadoop Common: 在0.20及以前的版本中,包含HDFS、MapReduce和其他项目公共内容,从0.21开始HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
HDFS: Hadoop分布式文件系统(Distributed File System) - HDFS (Hadoop Distributed File System)
MapReduce:并行计算框架,0.20前使用 org.apache.hadoop.mapred 旧接口,0.20版本开始引入org.apache.hadoop.mapreduce的新API
HBase: 类似Google BigTable的分布式NoSQL列数据库。(HBase和Avro已经于2010年5月成为顶级 Apache 项目)
Hive:数据仓库工具,由Facebook贡献。
Zookeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献。
Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的序列化机制。
Pig: 大数据分析平台,为用户提供多种接口。
Ambari:Hadoop管理工具,可以快捷的监控、部署、管理集群。
Sqoop:于在HADOOP与传统的数据库间进行数据的传递。
配置虚拟机
HDFS由java编写,需要jdk支持
docker官方文档要求必须运行在Linux kernel 3.8以上,所以需要安装在Centos7或者Ubantu系统上。
yum install lrzsz #安装上传下载组件
uname –a #检查当前Linux内核版本
查询结果:Linux tdocker 3.10.0-327.el7.x86_64 #1 SMP Thu Nov 19 22:10:57 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
配置IP地址
修改配置文件
cd /etc/sysconfig/network-scripts #进入网络配置目录
dir ifcfg* #找到网卡配置文件
ifcfg-eno16777736 ifcfg-lo
vi ifcfg-eno16777736
配置文件内容
TYPE=Ethernet
BOOTPROTO=static #改成static,针对NAT
NAME=eno16777736
UUID=4cc9c89b-cf9e-4847-b9ea-ac713baf4cc8
DEVICE=eno16777736
ONBOOT=yes #开机启动此网卡
IPADDR=192.168.163.30 #固定IP地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.163.2 #网关和NAT自动配置的相同,不同则无法登录
DNS1=192.168.163.2 #和网关相同
测试
centos7 命令发生巨大变化
ip addr #查看IP地址 ip add
service network restart #重启网络
systemctl restart network.service #重启网络centos7
vi /etc/hosts #127.0.0.1 dredis
hostname dreids #注意必须修改机器名hostname
ping www.baidu.com #如果出现baidu的ip地址则表示网络连通
配置域名解析
1、windows配置
C:WindowsSystem32driversetchosts
192.168.163.129 hadoop01
192.168.163.130 hadoop02
192.168.163.131 hadoop03
2、linux虚拟机配置hosts
vi /etc/hosts
192.168.163.129 hadoop01
192.168.163.130 hadoop02
192.168.163.131 hadoop03
hostname hadoop01 #修改每台服务器的机器名,必须
3、重启网络
/etc/init.d/network restart
或者
service network restart
4、ssh免登陆
在虚拟机中Terminal中执行下面语句
ssh-keygen #三次回车即可
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.163.130 #复制密钥
ssh 192.168.163.130
5、安装jdk配置环境变量


zk首先需要安装jdk环境。 mkdir /usr/local/src/java #按习惯用户自己安装的软件存放到/usr/local/src目录下 上传jdk tar包 #利用SSH工具软件上传文件 tar -xvf jdk-7u51-linux-x64.tar.gz #解压压缩包 配置环境变量 1)vi /etc/profile 2)在尾行添加 #set java environment JAVA_HOME=/usr/local/src/java/jdk1.7.0_51 JAVA_BIN=/usr/local/src/java/jdk1.7.0_51/bin PATH=$JAVA_HOME/bin:$PATH CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH 保存退出 3)source /etc/profile 使更改的配置立即生效 4)java -version 查看JDK版本信息。如显示1.7.0证明成功。
6、关闭防火墙
systemctl stop firewalld.service #关闭防火墙服务 systemctl disable firewalld.service #禁止防火墙开启启动 或者 systemctl restart iptables.service #重启防火墙使配置生效 systemctl enable iptables.service #设置防火墙开机启动 检查防火墙状态 [root@hadoop01 ~]# firewall-cmd --state #检查防火墙状态 not running #返回值,未运行
Zookeeper安装配置
在Zookeeper集群环境下只要一半以上的机器正常启动了,那么Zookeeper服务将是可用的。因此,集群上部署Zookeeper最好使用奇数台机器,这样如果有5台机器,只要3台正常工作则服务将正常使用。
ZooKeeper介绍
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
官网:http://www.apache.org/dist/zookeeper/ cd /usr/local/src #安装文件根目录 mkdir zk #安装路径 tar -xvf zookeeper-3.4.8.tar.gz #解压 cd zookeeper-3.4.8 #进入目录 mkdir log #创建日志文件路径 mkdir data #创建数据文件路径,默认/tmp/zookeeper下 cd data #进入数据目录 vi myid #创建myid文件,内容1对应zoo.cfg中配置的server.1范围:1~255之间的整数,在集群中必须唯一 cd .. #退到上级目录 cd conf #进入配置目录 cp zoo_sample.cfg zoo.cfg #复制模板文件
tickTime=2000 #tickTime心跳时间, clientPort=2181 #访问端口 dataDir=/usr/local/src/zk/zookeeper-3.4.8/data #设置日志路径 dataLogDir=/usr/local/src/zk/zookeeper-3.4.8/log #增加设置日志路径 server.1=hadoop01:2888:3888 #集群最少3个节点,可按机器名 server.2=hadoop02:2888:3888 #2888指follower连leader端口 server.3=hadoop03:2888:3888 #3888指定选举的端口
Centos6.5 /sbin/iptables -I INPUT -p tcp --dport 2181 -j ACCEPT #打开端口 /etc/rc.d/init.d/iptables save #修改生效 /etc/init.d/iptables status #查看配置 Centos7 firewall-cmd --zone=public --add-port=2181/tcp --permanent #开端口 firewall-cmd --zone=public --add-port=2888/tcp --permanent #开端口 firewall-cmd --zone=public --add-port=3888/tcp --permanent #开端口 firewall-cmd --reload #执行 firewall-cmd --zone=public --list-ports #查看打开端口 注:关闭防火墙更彻底,要打开端口则所有的远程访问端口都类似上面必须打开
sh bin/zkServer.sh start #启动ZK服务 sh bin/zkServer.sh stop #停止ZK服务 sh bin/zkServer.sh restart #重启ZK服务
[root@localhost conf]# jps 5863 Jps 2416 QuorumPeerMain #QuorumPeerMain是zookeeper进程,启动正常
sh bin/zkServer.sh status #查看ZK状态 查看结果:集群中只有一个leader,其他都是follower [root@localhost bin]# ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/src/zk/zookeeper-3.4.8/bin/../conf/zoo.cfg Mode: leader [root@localhost bin]# ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/src/zk/zookeeper-3.4.8/bin/../conf/zoo.cfg Mode: follower 常见错误: Error contacting service. It is probably not running. 如果出现上面提示,请检查配置文件或者防火墙是否放行2181/2888/3888端口 [root@localhost bin]# ./zkServer.sh stop [root@localhost bin]# ./zkServer.sh start-foreground 日志启动方式 注意,如果启动时拒绝访问,检查是否防火墙端口都打开,如果打开则都先启动,再看。某个节点没启动,当然访问是被拒绝。
[root@localhost bin]# ./zkCli.sh -server hadoop01:2181
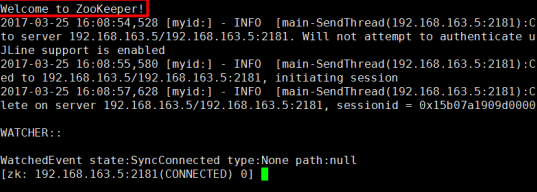
[zk: localhost:2181(CONNECTED) 1] ls / [dubbo, zookeeper]
安装HDFS
cd /usr/local/src #进入目录 mkdir hadoop #创建目录 tar -xvf hadoop-2.7.1.tar.gz #上传文件
vi etc/hadoop/hadoop-env.sh #JDK安装目录,虽然系统配置了JAVA_HOME,但有时无法正确识别,最后进行配置 export JAVA_HOME=/usr/local/src/java/jdk1.7.0_51/ #指定hadoop的配置文件目录,不运行hadoop可以不指定 export HADOOP_CONF_DIR=/usr/local/src/hadoop/hadoop-2.7.1/etc/hadoop
vi etc/hadoop/core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.163.129:9000</value> </property> <!--注意:用来指定临时存放目录,否则默认的系统的临时目录当重启hadoop时会被删除,影响HDFS下的文件 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/src/hadoop/hadoop-2.7.1/tmp</value> </property> <!--执行zookeeper地址--> <property> <name>ha.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> </configuration>
vi etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.namenode.rpc-address</name> <value>hadoop01:9000</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
vi etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.namenode.rpc-address</name> <value>hadoop01:9000</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
将mapred-site.xml.template复制一份并将名称修改为mapred-site.xml cp mapred-site.xml.template mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
vi slaves
hadoop01 #将localhost改为hostname名
配置hadoop的环境变量:
#set hadoop env
HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.7.1/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
bin/hdfs namenode –format

看到上面的successfully格式化成功,文件在/tmp/hadoop-root/dfs/name下
注意:可能失败,jps检查不到namenode,再次格式化,如果还不行检查配置文件。
sbin/start-dfs.sh
#停止服务stop-dfs.sh

也可以执行sbin/start-all.sh启动hadoop,其中就包括hdfs。它会多启动两个服务:nodeManager和ResourceManager。执行jps就应该显示6个服务,就代表启动成功。
检查服务是否正常:
1、可以通过浏览器直接访问:http://192.168.163.129:50070/
2、如下图
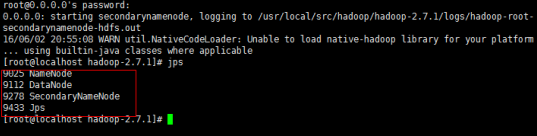
1、可以用jps查看后台java进程,确保hdfs的进程都正常启动 由于重新格式化系统可能出现某些进程不能启动,解决方法是先停止服务,删除rm -fr /tmp/hadoop-root 下name,data等节点数据,重新启动服务 2、localhost: ssh: Could not resolve hostname localhost: Name or service not …… 在/etc/profile中进行配置 #set hadoop env HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.7.1/ export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 3、namenode address dfs.namenode.servicerpc-address or dfs.namenode.rpc-address is not configured. [root@hadoop01 hadoop-2.7.1]# vim etc/hadoop/hdfs-site.xml <property> <name>dfs.namenode.rpc-address</name> <value>192.168.163.129:9000</value> </property> 3、put: Cannot create file/test/letter.txt._COPYING_. Name node is in safe mode. 执行下面的命令 bin/hadoop dfsadmin -safemode leave
http://192.168.163.129:50070/
执行命令很慢,执行时稍等片刻
bin/hdfs dfs -mkdir /user #创建user目录
bin/hdfs dfs -put /root/install.log /use r #上传文件
bin/hdfs dfs –ls / #查看根目录
bin/hdfs dfs -ls /user #列目录
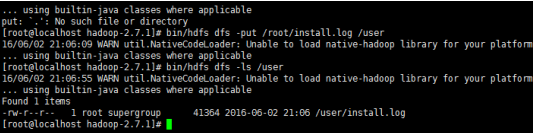
http://192.168.163.129:50070/
注意:端口50070或者要关闭防火墙