一、Redis Hash操作
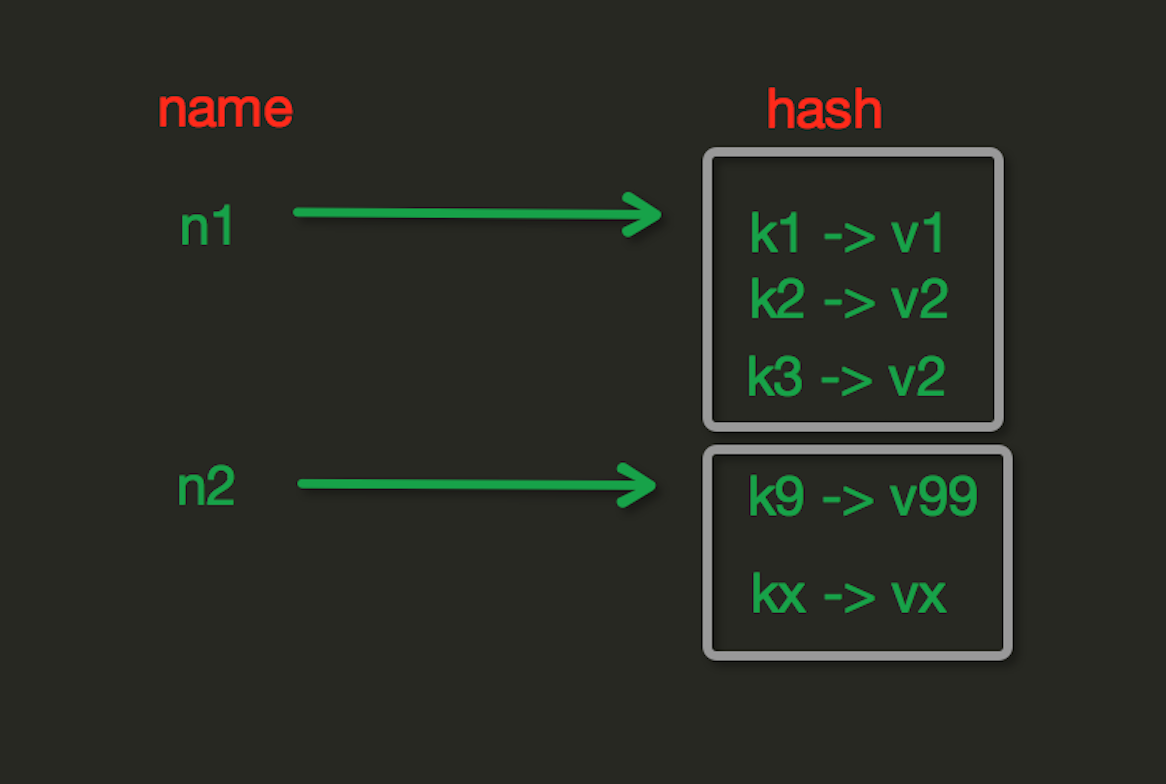
Redis 数据库hash数据类型是一个string类型的key和value的映射表,适用于存储对象。Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。 hash表现形式上有些像pyhton中的dict,可以存储一组关联性较强的数据 , redis中Hash在内存中的存储格式如下图:
二、Hash命令
|
1
2
3
4
5
6
7
8
9
10
|
# 连接redisimport redishost = '172.16.200.49'port = 6379pool = redis.ConnectionPool(host=host, port=port)r = redis.Redis(connection_pool=pool) |
2.1 hset(name, key, value)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数: # name,redis的name # key,name对应的hash中的key # value,name对应的hash中的value # 注: # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)r.hset('p_info', 'name', 'bigberg')r.hset('p_info', 'age', '22')r.hset('p_info', 'gender', 'M')# 设置了姓名、年龄和性别 |
2.2 hmset(name, mapping)
|
1
2
3
4
5
6
7
8
9
10
11
|
# 在name对应的hash中批量设置键值对 # 参数: # name,redis的name # mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如: # r.hmset('xx', {'k1':'v1', 'k2': 'v2'})r.hmset('info_2', {'name': 'Jerry', 'species': 'mouse'}) |
2.3 hget(name, key)
|
1
2
3
4
5
6
7
|
# 在name对应的hash中获取根据key获取value# 获取的bytes 类型print(r.hget('p_info', 'name').decode())# 输出bigberg |
2.3 hmget(name, key, *args)
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# 在name对应的hash中获取多个key的值 # 参数: # name,reids对应的name # keys,要获取key集合,如:['k1', 'k2', 'k3'] # *args,要获取的key,如:k1,k2,k3 # 如:print(r.hmget('p_info', ['name', 'age', 'gender']))# 输出是一个列表[b'bigberg', b'22', b'M'] |
2.4 hgetall(name)
|
1
2
3
4
5
6
7
|
获取name对应hash的所有键值print(r.hgetall('p_info'))#输出是一个字典{b'name': b'bigberg', b'gender': b'M', b'age': b'22'} |
2.5 hlen(name)
|
1
2
3
4
5
6
|
# 获取name对应的hash中键值对的个数print(r.hlen('p_info'))#输出3 |
2.6 hkeys(name)
|
1
2
3
4
5
6
|
# 获取name对应的hash中所有的key的值print(r.hkeys('p_info'))#输出[b'name', b'age', b'gender'] |
2.7 hvals(name)
|
1
2
3
4
5
6
|
# 获取name对应的hash中所有的value的值print(r.hvals('p_info'))#输出 [b'bigberg', b'22', b'M'] |
2.8 hexists(name, key)
|
1
2
3
4
5
6
7
8
|
# 检查name对应的hash是否存在当前传入的keyprint(r.hexists('p_info', 'name'))print(r.hexists('p_info', 'job'))#输出TrueFalse |
2.9 hdel(name,*keys)
|
1
2
3
4
5
6
7
8
|
# 将name对应的hash中指定key的键值对删除r.hdel('p_info', 'gender')print(r.hgetall('p_info'))# 删除了性别#输出{b'name': b'bigberg', b'age': b'22' |
2.10 hincrby(name, key, amount=1)
|
1
2
3
4
5
6
7
8
9
10
11
|
# 自增name对应的hash中的指定key的值,不存在则创建key=amount# 参数: # name,redis中的name # key, hash对应的key # amount,自增数(整数)r.hincrby('p_info', 'age', 1)print(r.hget('p_info', 'age'))#输出,年龄增加1b'23' |
2.11 hincrbyfloat(name, key, amount=1.0)
|
1
2
3
4
5
6
7
8
|
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(浮点数) # 自增name对应的hash中的指定key的值,不存在则创建key=amount |
2.12 hscan(name, cursor=0, match=None, count=None)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数: # name,redis的name # cursor,游标(基于游标分批取获取数据) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数print(r.hscan('p_info', cursor=0))print(r.hscan('p_info', cursor=0, match='n*'))#输出(0, {b'age': b'23', b'address': b'hz', b'name': b'bigberg'})(0, {b'name': b'bigberg'}) |
http://redisdoc.com/key/scan.html#scan
2.13 hscan_iter(name, match=None, count=None)
|
1
2
3
4
5
6
7
8
9
|
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数: # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # for item in r.hscan_iter('xx'): # print(item) |