最近一直想面对大规模程序时,如何提高运算速度,100个怪物循环100次没有问题,但是处理的过程会特别庞大,所以考虑到使用多线程,unity的单线程,而unity自带的dots系统也不知道什么时候成熟,不想造轮子所以jobsystem真心不想用,在网上偶然间看到了一个关于鸟群算法对Computeshader的使用,查阅了很多资料后终于暂时入门:简单说就是在显卡上扣出一部分性能给游戏的数值做运算。
首先转载一张经典的图和某位原作者的话:
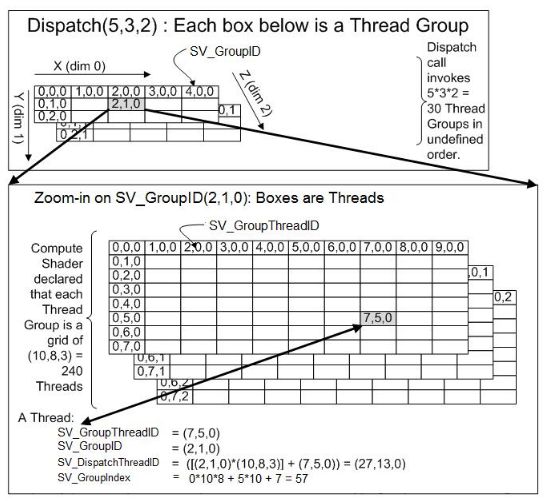
- SV_GroupThreadID 表示该线程在该组内的位置
- SV_GroupID 表示整个组所分配的位置
- SV_DispatchThreadID 表示该线程在所有组的线程中的位置
- SV_GroupIndex 表示该线程在该组内的索引
我自己的表述:
如果我们有一个长度为20的数组需要处理,为了同时处理者10000个数据,我们需要向显卡申请至少10000个线程,此时就可以申请10000个线程,但是呢这10000个线程太大了,所以呢,把这10000个线程的布局成一个2维数组,但是这个二位数组还是太大,所以呢就把这个二维数组再次切割成一个1维数组,这样整个表就切割成了一个3维数组;但是呢这个三维数组还是太大,以一个三维索引R范围为单元,再次按照上面的方法再切割成一个三维数组G,结果就是三维单元R就是numthreads(x,y,z),而三维数组G就是Dispatch(x,y,z)。这里也利于理解,因为显卡的处理单元过于庞大,已经超过了一个数组索引的范围,或者显卡的设计就是以层层阵列的方式制作的,因此这种超维度结构可以更好的索引到需要的资源,而它申请索引的时候完全是靠数字电路硬件获取(学过计算机电子的都知道)。另外这样分块的好处将在下面的例子中提到。
所以再次对上面的索引做出解释:
- SV_GroupThreadID 表示该线程在该组内的位置----------即这个三维单元内的单元数组空间中索引
- SV_GroupID 表示整个组所分配的位置----------即该线程所在的组在组空间中的索引
- SV_DispatchThreadID 表示该线程在所有组的线程中的位置----------即不将整个三维单元分组的情况下的三维索引
- SV_GroupIndex 表示该线程在该组内的索引----------即这个三维单元内的数组转换成一个一维数组时所在的索引
例子:
对一个结构体数组内的所有结构内的数乘以2:
C#代码:
using System.Collections; using System.Collections.Generic; using System.Diagnostics; using UnityEngine; public class MyFirstComputeShader : MonoBehaviour { public ComputeShader computeShader = null; data[] inputDatas = new data[3];//输入数组 data[] outputDatas = new data[3];//结果数组 struct data { public float a; public float b; public float c; } private void InitData() { inputDatas = new data[3]; outputDatas = new data[3]; UnityEngine.Debug.Log("---------------cpu输入------------------------"); for(int i = 0; i < inputDatas.Length; i++) { inputDatas[i].a = i * 3 + 1; inputDatas[i].b = i * 3 + 2; inputDatas[i].c = i * 3 + 3; UnityEngine.Debug.Log(inputDatas[i].a + "," + inputDatas[i].b + "," + inputDatas[i].c); } } private void ToComputeShader(ref data[] i,ref data[] o) { //data 数据里面float*3,而一个float的字节为4字节,所以3*4 ComputeBuffer inputBuffer = new ComputeBuffer(i.Length, 12); ComputeBuffer outputBuffer = new ComputeBuffer(o.Length, 12); //拿到核心 int k = computeShader.FindKernel("CSMain"); inputBuffer.SetData(i); //写入gpu computeShader.SetBuffer(k, "inputDatas", inputBuffer); computeShader.SetBuffer(k, "outputDatas", outputBuffer); //计算再输出到cpu computeShader.Dispatch(k, 1, 1, 1); outputBuffer.GetData(o); UnityEngine.Debug.Log("---------------gpu输出------------------------"); for(int j = 0; j < o.Length; j++) { UnityEngine.Debug.Log(o[j].a + "," + o[j].b + "," + o[j].c); } //释放内存 inputBuffer.Release(); outputBuffer.Release(); } private void Update() { if (!Input.GetKeyDown(KeyCode.Space)) return; Stopwatch sw = new Stopwatch(); sw.Start(); //计时器开始 InitData(); ToComputeShader(ref inputDatas,ref outputDatas); sw.Stop(); //计时器结束 UnityEngine.Debug.Log(sw.Elapsed); //开始到结束之间的时长 } }
computeShader代码:
// Each #kernel tells which function to compile; you can have many kernels #pragma kernel CSMain struct data { float a; float b; float c; }; //(cpu->gpu) StructuredBuffer<data> inputDatas; //(gpu->cpu) RWStructuredBuffer<data> outputDatas; //[numthreads(3,1,1)] //void CSMain (uint3 id : SV_DispatchThreadID) //{ // //if (id > 2)return; // //计算一下 // outputDatas[id.x].a = inputDatas[id.x].a * 2; // outputDatas[id.x].b = inputDatas[id.x].b * 2; // outputDatas[id.x].c = inputDatas[id.x].c * 2; //} [numthreads(3, 1, 1)] void CSMain(uint id : SV_GroupIndex) { //计算一下 outputDatas[id].a = inputDatas[id].a * 2; outputDatas[id].b = inputDatas[id].b * 2; outputDatas[id].c = inputDatas[id].c * 2; }
结果如下:

因为我的数组长度是3,而numthreads(3,1,1),因此Dispatch(1,1,1),即申请了一个组,并且这个组内有3个线程。这里可以改进为numthreads(1,1,1),而dispatch(n,1,1),这样n的大小就是总的线程数量。关于这个问题以及常常出现的误区和某位仁兄讨论过如下:

解决:

其实本质就是我们申请到的是整个组区域中的所有线程,因此我们应该处理一下线程id超出的情况(貌似是难免的,当数组的不整齐的时候,就会有多余的线程出现),但是不知道为什么,显卡处理程序的时候,索引值超过缓存的长度也不会报错。
当要处理一个图片的时候比如图片大小是1024*1024,那么可以(512*2,512*2,1),即numthreads(2,2,1);dispatch(512,512,1);