1. 前言
前面近一个月去写自己的mybatis框架了,对mybatis源码分析止步不前,此文继续前面的文章。开始分析mybatis一,二级缓存的实现。
附上自己的项目github地址:https://github.com/xbcrh/simple-ibatis
对mybatis感兴趣的同学可关注下,全手写的一个orm框架,实现了sql的基本功能和对象关系映射。
废话不说,开始解析mybatis缓存源码实现。
2. mybatis中缓存的实现方式
见mybatis源码包 org.apache.ibatis.cache
2.1 mybatis缓存实现接口类:cache
public interface Cache { // 获取缓存的ID String getId(); // 放入缓存 void putObject(Object key, Object value); // 从缓存中获取 Object getObject(Object key); // 移除缓存 Object removeObject(Object key); // 清除缓存 void clear(); // 获取缓存大小 int getSize(); // 获取锁 ReadWriteLock getReadWriteLock(); }
mybatis自定义了缓存接口类,提供了基本的缓存增删改查的操作。在此基础上,提供了基础缓存实现类PerpetualCache。源码如下:
2.2 mybatis缓存基本实现类:PerpetualCache
public class PerpetualCache implements Cache { // 缓存的ID private String id; // 使用HashMap充当缓存(老套路,缓存底层实现基本都是map) private Map<Object, Object> cache = new HashMap<Object, Object>(); // 唯一构造方法(即缓存必须有ID) public PerpetualCache(String id) { this.id = id; } // 获取缓存的唯一ID public String getId() { return id; } // 获取缓存的大小,实际就是hashmap的大小 public int getSize() { return cache.size(); } // 放入缓存,实际就是放入hashmap public void putObject(Object key, Object value) { cache.put(key, value); } // 从缓存获取,实际就是从hashmap中获取 public Object getObject(Object key) { return cache.get(key); } // 从缓存移除 public Object removeObject(Object key) { return cache.remove(key); } // hashmap清除数据方法 public void clear() { cache.clear(); } // 暂时没有其实现 public ReadWriteLock getReadWriteLock() { return null; } // 缓存是否相同 public boolean equals(Object o) { if (getId() == null) throw new CacheException("Cache instances require an ID."); if (this == o) return true; // 缓存本身,肯定相同 if (!(o instanceof Cache)) return false; // 没有实现cache类,直接返回false Cache otherCache = (Cache) o; // 强制转换为cache return getId().equals(otherCache.getId()); // 直接比较ID是否相等 } // 获取hashCode public int hashCode() { if (getId() == null) throw new CacheException("Cache instances require an ID."); return getId().hashCode(); } }
PerpetualCache 类其实是对HashMap的封装,通过对map的put和get等操作实现缓存的存取等功能。mybatis中除了基本的缓存实现类外还提供了一系列的装饰类(此处是用到装饰者模式),此处拿较为重要的装饰类LruCache进行分析。
2.3 Lru淘汰策略实现分析
Lru是一种缓存淘汰策略,其核心思想是”如果数据最近被访问过,那么将来被访问的几率也更高“,LruCache 是基于LinkedHashMap实现,LinkedHashMap继承自HashMap,来分析下为什么LinkedHashMap可以当做Lru缓存实现。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
LinkedHashMap继承HashMap类,实际上就是对HashMap的一个封装。
// 内部维护了一个自定义的Entry,集成HashMap中的node类 static class Entry<K,V> extends HashMap.Node<K,V> { // linkedHashmap用来连接节点的字段,根据这两个字段可查找按顺序插入的节点 Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
构造方法见如下:
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { // 调用HashMap的构造方法 super(initialCapacity, loadFactor); // 访问顺序维护,默认false不开启 this.accessOrder = accessOrder; }
引入两种图来理解HashMap与LinkedHashMap
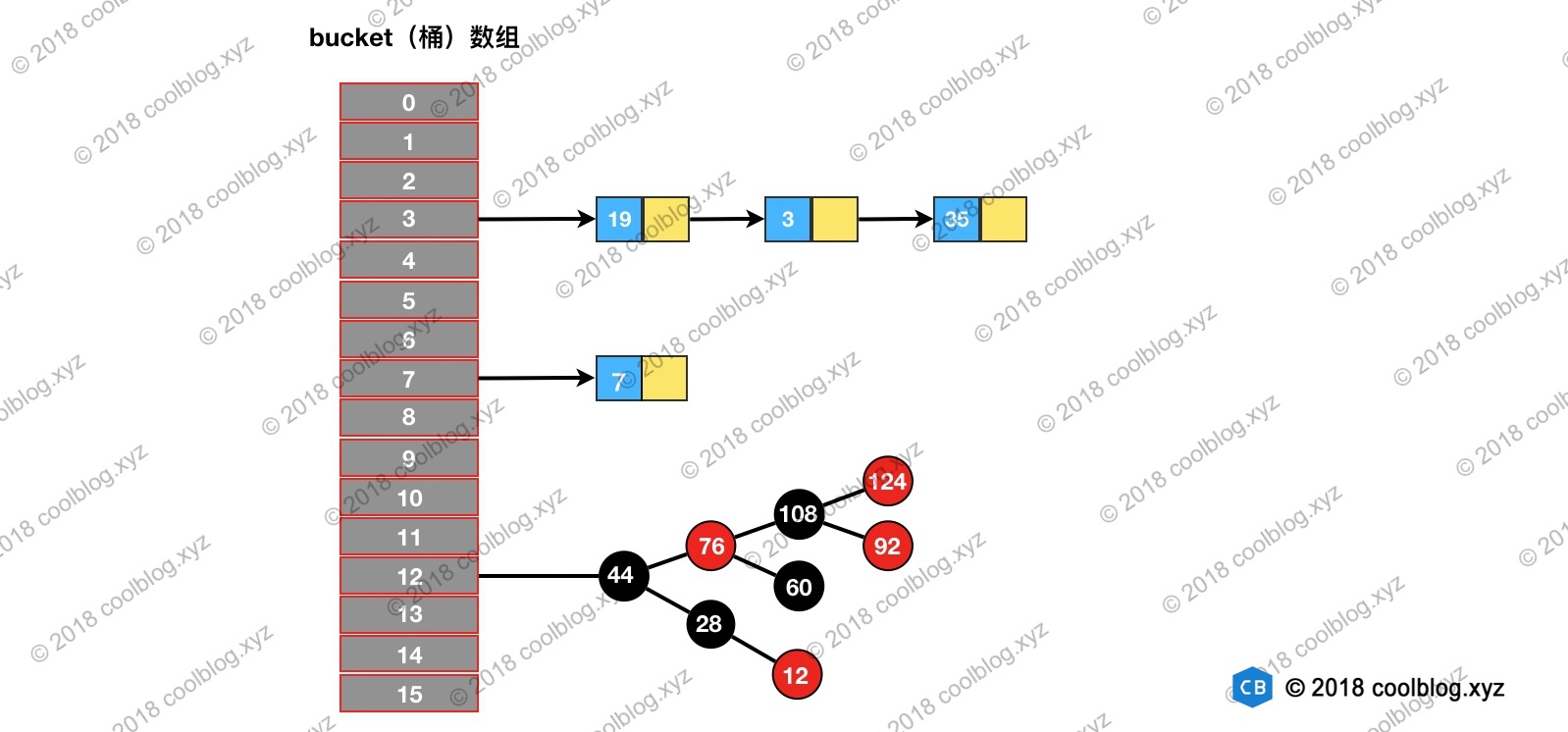
以上是HashMap的结构,采用拉链法解决冲突。LinkedHashMap在HashMap基础上增加了一个双向链表来表示节点插入顺序。

如上,节点上多出的红色和蓝色箭头代表了Entry中的before和after。在put元素时,会自动在尾节点后加上该元素,维持双向链表。了解LinkedHashMap结构后,在看看究竟什么是维护节点的访问顺序。先说结论,当开启accessOrder后,在对元素进行get操作时,会将该元素放在双向链表的队尾节点。源码如下:
public V get(Object key) { Node<K,V> e; // 调用HashMap的getNode方法,获取元素 if ((e = getNode(hash(key), key)) == null) return null; // 默认为false,如果开启维护链表访问顺序,执行如下方法 if (accessOrder) afterNodeAccess(e); return e.value; } // 方法实现(将e放入尾节点处) void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; // 当节点不是双向链表的尾节点时 if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; // 将待调整的e节点赋值给p p.after = null; if (b == null) // 说明e为头节点,将老e的下一节点值为头节点 head = a; else b.after = a;// 否则,e的上一节点直接指向e的下一节点 if (a != null) a.before = b; // e的下一节点的上节点为e的上一节点 else last = b; if (last == null) head = p; else { p.before = last; // last和p互相连接 last.after = p; } tail = p; // 将双向链表的尾节点指向p ++modCount; // 修改次数加以 } }
代码很简单,如上面的图,我访问了节点值为3的节点,那木经过get操作后,结构变成如下:
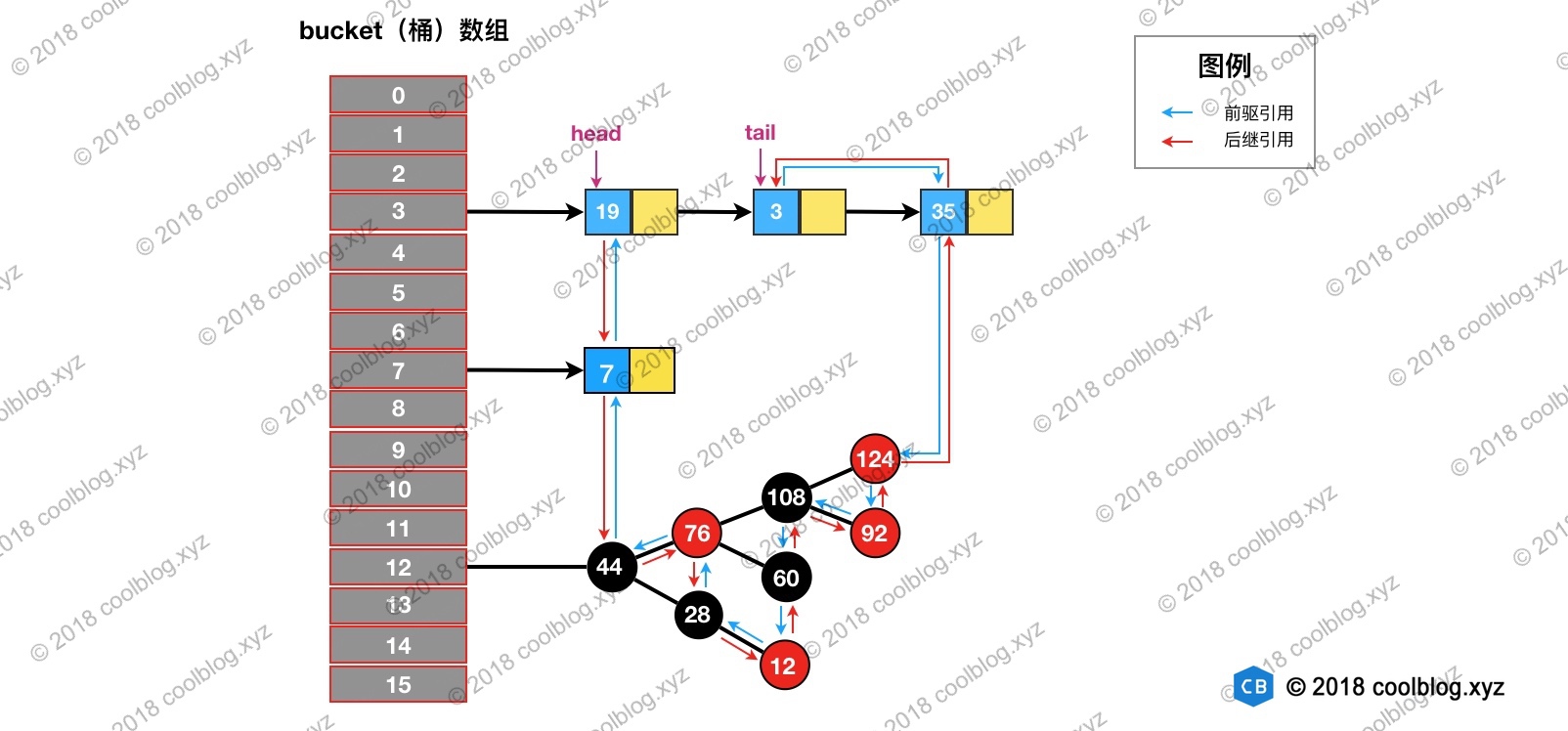
经过如上分析我们知道,如果限制双向链表的长度,每次删除头节点的值,就变为一个lru的淘汰策略了。举个例子,我想限制双向链表的长度为3,依次put 1 2 3,链表为 1 -> 2 -> 3,访问元素2,链表变为 1 -> 3-> 2,然后put 4 ,发现链表长度超过3了,淘汰1,链表变为3 -> 2 ->4;
那木linkedHashMap是怎样知道自定义的限制策略,看代码,因为LinkedHashMap中没有提供自己的put方法,是直接调用的HashMap的put方法,查看hashMap代码如下:
// hashMap final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); // 看这个方法 afterNodeInsertion(evict); return null; } // linkedHashMap重写了此方法 void afterNodeInsertion(boolean evict) { // possibly remove eldest LinkedHashMap.Entry<K,V> first; // removeEldestEntry默认返回fasle if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; // 移除双向链表中的头指针元素 removeNode(hash(key), key, null, false, true); } }
原来只需要重新实现removeEldestEntry就可以自定义实现lru功能了。了解基本的lru原理后,开始分析LruCache。
2.4 缓存包装类 - LruCache
public class LruCache implements Cache { // 被装饰的缓存类,即真实的缓存类,提供真正的缓存能力 private final Cache delegate; // 内部维护的一个linkedHashMap,用来实现LRU功能 private Map<Object, Object> keyMap; // 待淘汰的缓存元素 private Object eldestKey; // 唯一构造方法 public LruCache(Cache delegate) { this.delegate = delegate; // 被装饰的缓存类 setSize(1024); // 设置缓存大小 } .... }
经分析,LruCache还是个装饰类。内部除了维护真正的Cache外,还维护了一个LinkedHashMap,用来实现Lru功能,查看其构造方法。
// 唯一构造方法 public LruCache(Cache delegate) { this.delegate = delegate; // 被装饰的缓存类 setSize(1024); // 设置缓存大小 } // setSize()是构造方法中方法 public void setSize(final int size) { // 初始化keyMap keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) { private static final long serialVersionUID = 4267176411845948333L; // 什么时候自动删除缓存元素,此处是根据当缓存数量超过指定的数量,在LinkedHashMap内部删除元素 protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) { boolean tooBig = size() > size; if (tooBig) { // 将待删除元素赋值给eldestKey,后续会根据此值是否为空在真实缓存中删除 eldestKey = eldest.getKey(); } return tooBig; } }; }
和上文分析一样,重写了removeEldestEntry方法。此方法返回一个boolean值,当缓存的大小超过自定义大小,返回true,此时linkedHashMap中会自动删除eldest元素。在真实缓存cache中也将此元素删除。保持真实cache和linkedHashMap元素一致。其实就是用linkedHashMap的lru特性来保证cache也具有此lru特性。
分析put方法和get方法验证此结论.。
@Override public Object getObject(Object key) { keyMap.get(key); // 触发linkedHashMap中get方法,将key对应的元素放入队尾 return delegate.getObject(key); // 调用真实的缓存get方法 } // 放入缓存时,除了在真实缓存中放一份外,还会在LinkedHashMap中放一份 @Override public void putObject(Object key, Object value) { delegate.putObject(key, value); // 调用LinkedHashMap的方法 cycleKeyList(key); } private void cycleKeyList(Object key) { // linkedHashMap中put,会触发removeEldestEntry方法,如果缓存大小超过指定大小,则将双向链表对头值赋值给eldestKey keyMap.put(key, key); // 检查eldestKey是否为空。不为空,则代表此元素是淘汰的元素了,需要在真实缓存中删除。 if (eldestKey != null) { // 真实缓存中删除 delegate.removeObject(eldestKey); eldestKey = null; } }
介绍完Cache基本实现后,开始分析mybatis中一级缓存
3. mybatis一级缓存使用源码分析
此处是仅介绍mybatis的实现,没有涉及到与Spring整合,先介绍mybatis最基本的sql执行语法。默认大家掌握了SqlSessionFactoryBuilder,SqlSessionFactory,SqlSession用法。后面我会写一篇博客分析SQL在mybatis中执行的过程,会介绍到这些基础知识。
InputStream inputStream = Resources.getResourceAsStream("com/xiaobing/resource/mybatisConfig.xml"); // 构建字节流
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); // 构建SqlSessionFactoryBuilder
SqlSessionFactory factory = builder.build(inputStream); // 构建SqlSessionFactory
SqlSession sqlSession = factory.openSession(); // 生成SqlSession
List<SysUser> userList = sqlSession.selectList("com.xiaobing.mapper.SysUserMapper.getSysUser"); // 执行SysUserMapper类的getSysUser方法
前文构建SqlSession的内容大家感兴趣可自行查看,此处仅分析执行过程。查看selectList方法,mybatis中sqlSession的默认实现为DefaultSqlSession
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) { try { // 每个mapper文件会解析生成一个MappedStatement MappedStatement ms = configuration.getMappedStatement(statement); // 调用真实的查询方法,此处是调用executor的方法。executor采用了装饰者模式,若该mapper文件未启用二级缓存,则默认为BaseExecutor。 // 若该mapper文件启用了二级缓存,则使用的是CachingExecutor List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); return result; } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
因为此处使用的是装饰者模式,BaseExecutor是最基础的执行器,使用了一级缓存,CachingExecutor是对BaseExecutor进行一次封装,若打开二级缓存开关,在使用一级缓存前,先使用二级缓存。后文介绍二级缓存会分析这两个Executor生成地方。先分析BaseExecutor的一级缓存实现。
// BaseExecutor.java /** * 查询,并创建好CacheKey对象 * @param ms Mapper.xml文件的select,delete,update,insert这些DML标签的封装类 * @param parameter 参数对象 * @param rowBounds Mybatis的分页对象 * @param resultHandler 结果处理器对象 */ public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameter); // 获取boundSql对象 CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); // 生成缓存KEY return query(ms, parameter, rowBounds, resultHandler, key, boundSql); // 执行如下方法 } @SuppressWarnings("unchecked") public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) throw new ExecutorException("Executor was closed."); //如果将flushCacheRequired为true,则会在执行器执行之前就清空本地一级缓存 if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List<E> list; try { queryStack++; // 请求堆栈加一 // 如果此次查询的resultHandler为null(默认为null),则尝试从本地缓存中获取已经缓存的的结果 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { //如果查到localCache缓存,处理localOutputParameterCache,即对存储过程的sql进行特殊处理 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { // 从数据库中查询,并将结果放入到localCache list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { // 请求堆栈减一 queryStack--; } if (queryStack == 0) { // 加载延迟加载List for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } deferredLoads.clear(); // issue #601 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { clearLocalCache(); // issue #482 } } return list; } private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; localCache.putObject(key, EXECUTION_PLACEHOLDER); // 先放置一个占位符 try { list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); // 从数据库中查找 } finally { localCache.removeObject(key); // 移除占位符 } localCache.putObject(key, list); // 放入缓存 if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); // 若是存储过程,则放入存储过程缓存中 } return list; // 返回查询结果 }
mybatis一级缓存很好理解,对于同一个SqlSession对象(即同一个Executor),执行同一条语句时,BaseExecutor会先从自己的缓存中查找,是否存在此条语句的结果,若能找到,则直接返回(暂且忽略存储过程处理)。若没有找到,则查询数据库,将结果放入此缓存,供下次使用。mybatis默认打开一级缓存。
4. mybatis二级缓存使用源码分析
4.1 配置方式
在全局配置文件中mybatis-config.xml中加入如下设置
<settings> <setting name="cacheEnabled" value="true"/> </settings>
在具体mapper.xml中配置<cache/>标签或者<cache-ref/>标签
<cache></cache>或者<cache-ref/>
或者采用注解配置方式,在mapper.java文件上配置注解
@CacheNamespace 或者 @CacheNamespaceRef
4.1 mybatis解析二级缓存标签
还是采用上面sqlSession方式代码来debug
InputStream inputStream = Resources.getResourceAsStream("com/xiaobing/resource/mybatisConfig.xml"); // 构建字节流
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); // 构建SqlSessionFactoryBuilder
SqlSessionFactory factory = builder.build(inputStream); // 构建SqlSessionFactory
进入查看builder.build()方法
// SqlSessionFactoryBuilder.java /**根据流构建SqlSessionFactory*/ public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) { try { /**构建XML文件解析器*/ XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties); /**开始解析mybatis-config.xml文件并构建全局变量Configuration*/ return build(parser.parse()); } catch (Exception e) { throw ExceptionFactory.wrapException("Error building SqlSession.", e); } finally { ErrorContext.instance().reset(); try { inputStream.close(); } catch (IOException e) { // Intentionally ignore. Prefer previous error. } } }
进入parser.parse()方法,,进一步分析
public Configuration parse() { if (parsed) { throw new BuilderException("Each XMLConfigBuilder can only be used once."); } parsed = true; parseConfiguration(parser.evalNode("/configuration")); return configuration; } private void parseConfiguration(XNode root) { try { propertiesElement(root.evalNode("properties")); //issue #117 read properties first // 读取properties配置 typeAliasesElement(root.evalNode("typeAliases")); // 读取别名设置 pluginElement(root.evalNode("plugins")); // 读取插件设置 objectFactoryElement(root.evalNode("objectFactory")); // 读取对象工厂设置 objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); // 读取对象包装工厂设置 settingsElement(root.evalNode("settings")); // 读取setting设置 environmentsElement(root.evalNode("environments")); // read it after objectFactory and objectWrapperFactory issue #631 // 读取环境设置 databaseIdProviderElement(root.evalNode("databaseIdProvider")); // 读取数据库ID提供信息 typeHandlerElement(root.evalNode("typeHandlers")); // 读取类型转换处理器 mapperElement(root.evalNode("mappers")); // 解析mapper文件 } catch (Exception e) { throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e); } }
此处仅分析<cache/> 和 <cache-ref/>标签的解析,<cache/> 和 <cache-ref/>存在具体的mapper.xml文件中,分析mapperElement()方法。因为在mybatis-config.xml文件中关于<mapper>标签的值可配置package,resource,url,class等配置。如
<mappers>
<mapper class="com.xiaobing.mapper.SysUserMapper"/>
</mappers>
分析mapperElement()方法
/** * 映射文件支持四种配置,package,resource,url,class四种 * 如在mybatis-config.xml中配置 * <mappers> <mapper class="com.xiaobing.mapper.SysUserMapper"/> </mappers> * */ private void mapperElement(XNode parent) throws Exception { if (parent != null) { for (XNode child : parent.getChildren()) { if ("package".equals(child.getName())) { // 若配置的是package,在讲package下的所有mapper文件进行解析 String mapperPackage = child.getStringAttribute("name"); configuration.addMappers(mapperPackage); } else { String resource = child.getStringAttribute("resource"); String url = child.getStringAttribute("url"); String mapperClass = child.getStringAttribute("class"); if (resource != null && url == null && mapperClass == null) { // 若配置的是resource,在解析resource对应的mapper.xml ErrorContext.instance().resource(resource); InputStream inputStream = Resources.getResourceAsStream(resource); // 获取xml文件字节流 XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments()); // 构建xml文件构造器 mapperParser.parse(); // 解析xml文件 } else if (resource == null && url != null && mapperClass == null) { // 若配置的是url,在解析url对应的mapper.xml ErrorContext.instance().resource(url); InputStream inputStream = Resources.getUrlAsStream(url); XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments()); mapperParser.parse(); } else if (resource == null && url == null && mapperClass != null) { // 若配置的是class,在解析class对应的mapper文件 Class<?> mapperInterface = Resources.classForName(mapperClass); configuration.addMapper(mapperInterface); // 分析addMapper()方法 } else { throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one."); } } } } }
因为我采用的是class配置,所以分析configuration.addMapper()方法
// Configuration.java public <T> void addMapper(Class<T> type) { mapperRegistry.addMapper(type); }
继续进入mapperRegistry.addMapper进行分析
// MapperRegistry.java public <T> void addMapper(Class<T> type) { if (type.isInterface()) { // mapper接口 if (hasMapper(type)) { // 若mapper已被注册 throw new BindingException("Type " + type + " is already known to the MapperRegistry."); } boolean loadCompleted = false; try { knownMappers.put(type, new MapperProxyFactory<T>(type)); // 注册映射接口 // It's important that the type is added before the parser is run // otherwise the binding may automatically be attempted by the // mapper parser. If the type is already known, it won't try. MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type); // 生成注解构造器 parser.parse(); // 解析mapper上的注解 loadCompleted = true; } finally { if (!loadCompleted) { knownMappers.remove(type); } } } }
knownMappers.put(type, new MapperProxyFactory<T>(type));这里很重要,是注册mapper文件代理对象。此处只做缓存的解释,不做注册详解,后面在分析sql执行流程时单独去分析。
parser.parse()是对mapper文件进行解析的关键,继续分析
// MapperAnnotationBuilder.java // 解析配置文件 public void parse() { String resource = type.toString(); // 接口的全限定名 class com.test.userMapper if (!configuration.isResourceLoaded(resource)) { // 是否加载过 loadXmlResource(); // 在默认路径下(默认和mapper接口同个包下),加载xml文件 configuration.addLoadedResource(resource); // 设为该mapper配置文件已解析 assistant.setCurrentNamespace(type.getName()); // 设置构建助力器当前命名空间 com.test.userMapper parseCache(); // 解析CacheNamespace注解,构建一个Cache对象,并保存到Mybatis全局配置信息中 parseCacheRef(); //解析CacheNamespace注解,引用CacheRef对应的Cache对象。 // 由此可知,当引入了<cache/>和<cacheRef/>后,该命名空间的缓存对象变为了CacheRef引用的缓存对象 Method[] methods = type.getMethods(); // 获取方法 for (Method method : methods) { try { if (!method.isBridge()) { // issue #237 若该方法不是桥接方法 parseStatement(method); //构建MapperStatement对象,并添加到Mybatis全局配置信息中 } } catch (IncompleteElementException e) { //当出现未完成元素时,添加构建Method时抛出异常的MethodResolver实例,到下个Mapper的解析时再次尝试解析 configuration.addIncompleteMethod(new MethodResolver(this, method)); } } } parsePendingMethods(); // 解析未完成解析的Method }
通过上面的代码注释,可知,当解析mapper.java文件前,会先在同个文件夹下查看是否存在mapper.xml文件,若存在,则先解析mapper.xml文件。在解析mapper.xml文件时,若在mapper.xml中写了缓存<cache/>或<cache-ref>,也会生成二级缓存。若同时还在mapper.java文件里写了@CacheNamespace注解。则会进行报错,因为出现了两个缓存。此时我们根据注解配置去分析。去分析parseCache()和parseCacheRef(),看配置了注解@CacheNamespace和CacheNamespaceRef之后缓存具体怎样生成。
// MapperAnnotationBuilder.java private void parseCache() { // 获取是否有@CacheNamespace 注解 CacheNamespace cacheDomain = type.getAnnotation(CacheNamespace.class); if (cacheDomain != null) { /* * 构建一个缓存对象,具体分析 * */ assistant.useNewCache(cacheDomain.implementation(), cacheDomain.eviction(), cacheDomain.flushInterval(), cacheDomain.size(), cacheDomain.readWrite(), null); } }
// mapperBuilderAssistant.java public Cache useNewCache(Class<? extends Cache> typeClass, // 基本缓存类 Class<? extends Cache> evictionClass, // 缓存装饰类 Long flushInterval, // 缓存刷新间隔 Integer size, // 缓存大小 boolean readWrite, // 缓存可读写 Properties props) { typeClass = valueOrDefault(typeClass, PerpetualCache.class); // 没有设置则采用默认的PerpetualCache evictionClass = valueOrDefault(evictionClass, LruCache.class); // 没有设置则采用默认的LruCache Cache cache = new CacheBuilder(currentNamespace) // 命名空间作为缓存唯一ID .implementation(typeClass) .addDecorator(evictionClass) .clearInterval(flushInterval) .size(size) .readWrite(readWrite) .properties(props) .build(); configuration.addCache(cache); // 加入到全局缓存 currentCache = cache; // 当前缓存设为cache,由此可知,缓存是mapper级别 return cache; }
此处是生成了二级缓存的地方,并设置当前mapper文件的缓存为这个生成的二级缓存。若没有配置@CacheNamespaceRef,那木此mapper文件就使用了这个自己生成的二级缓存。那@CacheNamespaceRef是用来干嘛的?回到上面代码处进行分析。
// MapperAnnotationBuilder.java private void parseCacheRef() { // @CacheNamespaceRef 相当于<cacheRef/>标签 CacheNamespaceRef cacheDomainRef = type.getAnnotation(CacheNamespaceRef.class); if (cacheDomainRef != null) { assistant.useCacheRef(cacheDomainRef.value().getName()); // 构建缓存引用,进入分析 } }
public Cache useCacheRef(String namespace) { if (namespace == null) { throw new BuilderException("cache-ref element requires a namespace attribute."); } try { unresolvedCacheRef = true; Cache cache = configuration.getCache(namespace); // 获取被引用的缓存 if (cache == null) { //被引用的缓存是否存在 throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found."); } currentCache = cache; // 设置当前缓存对象为被引用的缓存对象 unresolvedCacheRef = false; // 标志设置为false,代表有缓存引用。 return cache; } catch (IllegalArgumentException e) { throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.", e); } }
由上文可知,当配置了@CacheNamespaceRef和@CacheNamespace后,该mapper文件对应的缓存以@CacheNamespaceRef引用的缓存为准。这样可是使得不同的mapper文件有相同的缓存。
4.2 缓存具体使用场景
上文说了,开启二级缓存后,sqlSession中的Executor是CachingExecutor,查看生成CachingExecutor具体位置。继续从那段测试代码分析
SqlSession sqlSession = factory.openSession(); // 生成SqlSession List<SysUser> userList = sqlSession.selectList("com.xiaobing.mapper.SysUserMapper.getSysUser"); // 执行SysUserMapper类的getSysUser方法
debug进入DefaultSqlSessionfactory.openSession()方法
// DefaultSqlSessionfactory.java public SqlSession openSession() { return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false); } ... private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Transaction tx = null; try { final Environment environment = configuration.getEnvironment(); // 获取当前配置设置的环境,有事务工厂,数据源 final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); // 创建事务工厂 tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit); // 事务类 final Executor executor = configuration.newExecutor(tx, execType); // 生成执行器 return new DefaultSqlSession(configuration, executor, autoCommit); } catch (Exception e) { closeTransaction(tx); // may have fetched a connection so lets call close() throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } } ....
分析Executor executor = configuration.newExecutor(tx, execType);此段代码
// Configuration.java public Executor newExecutor(Transaction transaction, ExecutorType executorType) { executorType = executorType == null ? defaultExecutorType : executorType; // 默认为SimpleExecutor executorType = executorType == null ? ExecutorType.SIMPLE : executorType; Executor executor; ....... if (cacheEnabled) { // 若开启二级缓存,则生成CachingExecutor executor = new CachingExecutor(executor); } ....... }
当执行查询语句时,会执行Executor的query()方法。分析CachingExecutor中query()方法究竟是怎样使用二级缓存。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // mapper.xml设置了<cache>或者mapper.java使用了二级缓存注解 Cache cache = ms.getCache(); if (cache != null) { // 若该mapper文件中执行的上一条语句是更新语句(增删改),则会清空该mapper文件对应的二级缓存 flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, parameterObject, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); // 从二级缓存中获取 if (list == null) { // 若二级缓存中不存在 list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); // 调用后续的Executor执行语句,后续的Executor会继续使用一级缓存。 tcm.putObject(cache, key, list); // issue #578. Query must be not synchronized to prevent deadlocks // 放入二级缓存中 } return list; } } return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); // 若没开启二级缓存,则调用后续的Executor执行语句。后续的Executor会继续使用一级缓存。 } // 此处的update包括增删改 public int update(MappedStatement ms, Object parameterObject) throws SQLException { // 清空二级缓存 flushCacheIfRequired(ms); return delegate.update(ms, parameterObject); }
通过上面分析可知,二级缓存的实现是mapper级别的。只要对这个mapper文件使用@CacheNamespace注解或对应的xml使用<cache/>等标签,那木该mapper在生成时就会注册一个mapper级别的缓存。在后续
对这一mapper文件任何查询语句进程操作的时候,都会使用到这个二级缓存。二级缓存就相当于在一级缓存上在加入一个缓存。二级缓存Cache的实现是在LruCache上在封装了一层TransactionCache,为了防止脏数据的产生。感兴趣的可以自行去查看。以上便是关于mybatis缓存的内容。
4. 总结验证
我们知道,二级缓存是mapper级别的,在mybatis初始化时便生成了。当此mapper文件中有更新语句时,才会刷新二级缓存。举个例子,有MapperA.java和MapperB.java两个文件,并都开启了二级缓存,cacheA和cacheB。MapperA.java中有一条查询语句select1,此查询语句关联了B的表。在第一次执行MapperA.java中select1时,会从库中取出数据,并放入在cacheA中。当mapperB.java中如果有一条更新语句update2,执行update2,会刷新二级缓存cacheB。但不会刷新cacheA,因为update2并不在MapperA.java中。那此时cacheA中存在的数据便是脏数据了。
其实也有解决办法,即在MapperA.java中使用@CacheNamespaceRef = "mapperB.java".让两个文件公用同一个二级缓存。这样就OK啦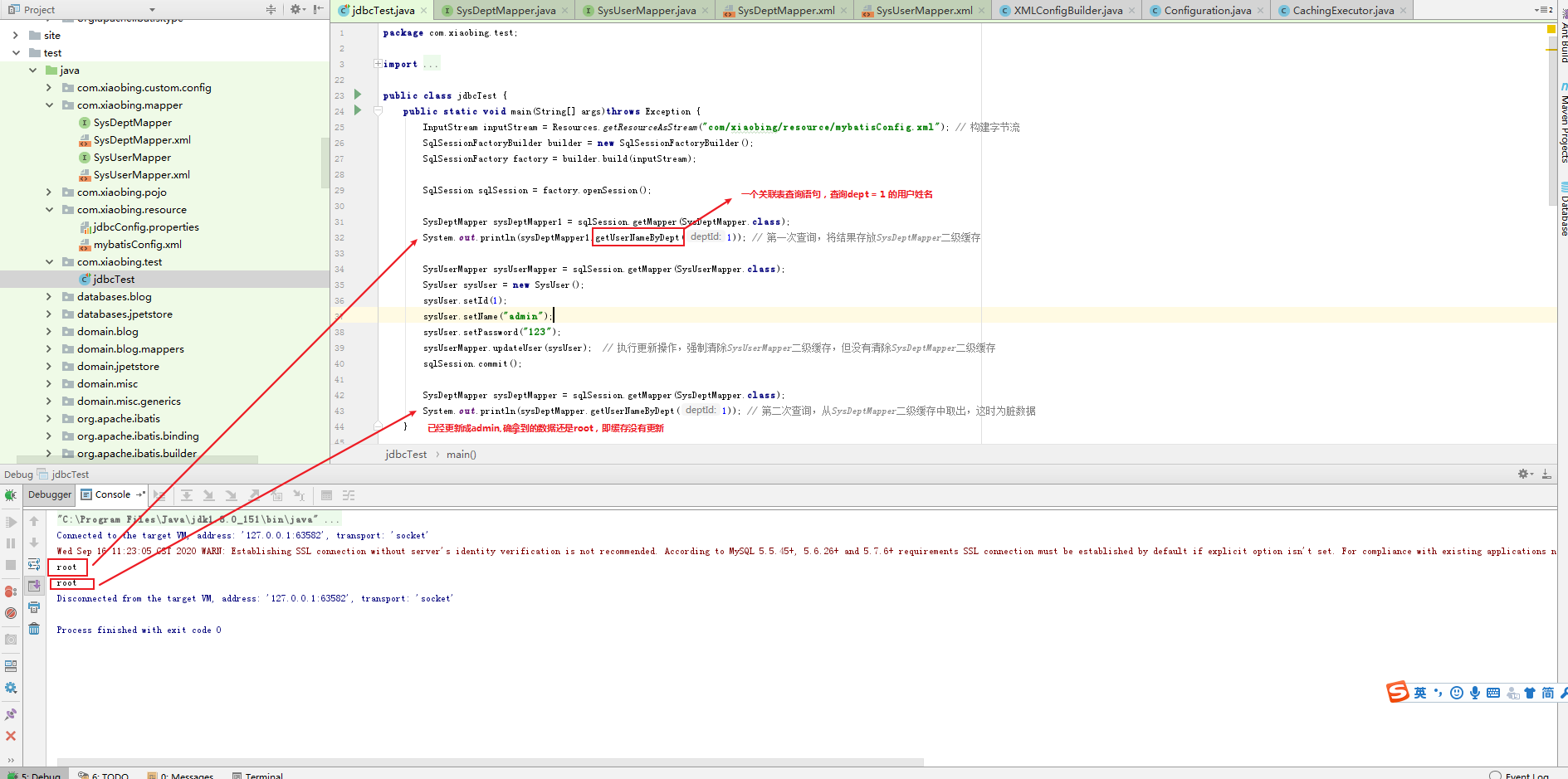
若对mybatis感兴趣的小伙伴,请移步我github项目,从零手写了一个ORM框架,希望你的star和交流:https://github.com/xbcrh/simple-ibatis