参考:https://blog.csdn.net/xbinworld/article/details/45619685
参考:https://blog.csdn.net/fate_fjh/article/details/53446630(FCN模型)
参考:https://blog.csdn.net/zyqdragon/article/details/72353420
LeNet模型(包括输入层在内共有8层):

模型结构如下:
第一层:输入层是32x32大小的图像
第二层:C1层是一个卷积层,6个feature map,5x5大小的卷积核,每个feature map共有(32-5+1)*(32-5+1)即28x28个神经元,每个神经元都与输入层的5x5大小的区域相连,即C1层有(5x5+1)x6=156个训练参数(5为卷积核权重,1为bias偏置项权重,共6个feature map),两层间的连接数为156x(28x28)=122304个,通过卷积运算来强化特征,减少噪音。
第三层:S2是池化层,共6个14x14的feature map,对应的池化大小为2x2,(按照书上的解释)这里的池化层的计算过程和普通的池化层有点差异,这里采用对上一层卷积层的2x2大小的数值求和得到xi,再经wxi+b计算后进行激活函数处理得到结果,这里的连接数为(4+1)x(14x14)x6=5880。
第四层:C3层是一个卷积层,采用5x5的卷积核,这里的feature map的神经元个数为(14-5+1)x(14-5+1)=10x10,这里有16个feature map,每个feature map由上一层的feature map之间进行不同组合。(现在大部分的卷积层都是和所有的上一层所有的feature map相连接,表现为每个feature map和卷积核内积后求和并加偏置项,得到输出的单个feature map中对应的数值)
第五层:S4是一个池化层,由16个5x5的feature map组成
第六层:C5是一个卷积层,同样使用5x5的卷积核,该层有120个feature map
第七层:F6全连接层有84个feature map,每个feature map只有一个神经元与C5全相连,该层计算输入向量和权重向量间的点积和偏置,然后传递给sigmoid函数计算。
第八层:输出层也是全连接层,共10个节点,分别代表数字0-9
AlexNet模型:
该模型总共有8层,前五层是卷积层,后三层是全连接层,最后一个全连接层的输出具有1000个输出的softmax。
第一个卷积层conv1中,Alexnet采用96个11x11x3的kernel(对应下图中的num_output),在stride为4的情况下对224x224x3的图像进行滤波,即通过11x11的卷积模板在3个通道上,间隔为4个像素的采样频率对图像进行卷积操作。
对于每个feature map来说,间隔为4,因此map核大小为(224/4-1)55x55。在得到基本的卷积数据后,通过relu、norm变换、池化操作作为输出传递到下一层。经过池化之后的feature map大小转化为(55/2)27x27,本层feature map的个数为96个。

第二个卷积通过256个5x5的卷积模板卷积得到(pad表示周边的0填充)。过程和第一层的conv1类似,(按照他人博客的意思)这里的group的目的在于将前面的feature map分开,卷积部分分成2部分来做,每组针对27x27x48的像素进行卷积运算。步长为1。其中,池化运算的尺度为3x3,运算步长为2,因而得到池化之后的feature map大小为13x13。 过程作图表示如下:
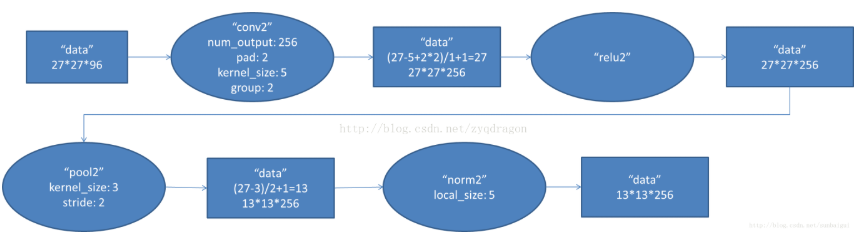
第三个卷积层的过程和第二个卷积层类似。这里采用384个卷积模板来进行操作,每个像素层都通过上下左右pad=1来进行填充,这里的2组像素层被送到2个不同的GPU中进行运算,每个GPU有192个卷积核,每个卷积核的尺寸为3x3x128。因此,每个GPU中的
卷积核都可以2组13x13x128的像素层的所有数据进行卷积运算。经计算后,得到2组GPU中总计13x13x384个卷积后的像素层。

第四层的输入为上一层的输出(即2组GPU的总计13x13x384的像素层),每个GPU中各有192个卷积核,每个卷积核的尺寸为13x13x192,其余部分同上。

第五层的输入为第四层输出的2组13x13x192的像素层,同上,这里也分为2个group,每组的卷积核的个数为128,卷积核的尺寸大小为13x13x192,经卷积计算后的卷积核尺寸大小为13x13x128,2组GPU总计13x13x256的卷积核。
经过核大小为3,步长为2的池化层处理后尺寸大小为(13-3)/2+1=6,即得到2组6x6x128的像素层,合计为6x6x256的像素层。

第六层为全连接层,这里的输入数据的尺寸大小为6x6x256,通过6x6x256尺寸的滤波器对输入数据进行卷积运算,每个6x6x256尺寸的滤波器对第六层的输入数据进行运算得到1个结果;共有4096个6x6x256尺寸的滤波器对输入数据进行卷积运算,
通过4096个神经元输出运算结果。再经relu激活函数得到4096个值,后通过dropout层输出4096个本层的输出结果。由于这一层的滤波器尺寸6x6x256和待处理的feature map的6x6x256的尺寸相同,也就是说滤波器的每个系数只和feature map中的一个
系数相乘,因此该层也称为全连接层。
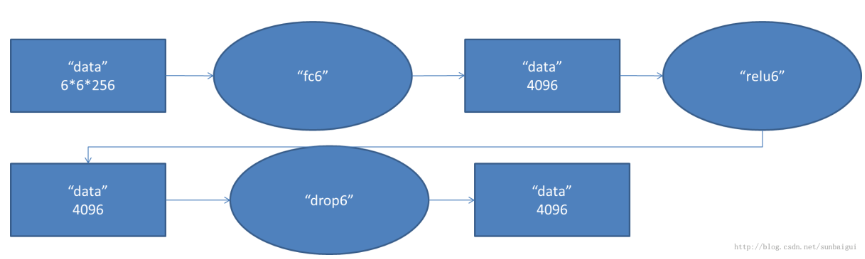
第七层也为全连接层。第六层的输出的4096个数据和第七层的4096个神经元进行全连接,后经relu处理、dropout处理,输出4096个数据。

第七层的4096个数据和第八层的1000个神经元进行全连接,经过训练后输出被训练的数值。

其中,Alexnet模型的各层发挥的作用如下表所示:
多GPU训练:提高训练速度
非线性激活函数:使用Relu非线性函数收敛更快,用Relu替代Sigmoid是因为Relu的SGD收敛速度比Sigmoid/tanh快很多,主要原因是Relu是线性的、非饱和的,只需要一个阈值就可以得到激活值。
dropout:减少过拟合
LRN局部相应归一化:有助于模型的泛化
重叠池化:提高精度、减少过拟合