Mepreduce分区
分区概述
在 MapReduce 中, 通过我们指定分区, 会将同一个分区的数据发送到同一个 Reduce 当中进行处理
例如: 为了数据的统计, 可以把一批类似的数据发送到同一个 Reduce 当中, 在同一个 Reduce 当
中统计相同类型的数据, 就可以实现类似的数据分区和统计等
其实就是相同类型的数据, 有共性的数据, 送到一起去处理
Reduce 当中默认的分区只有一个
实战:
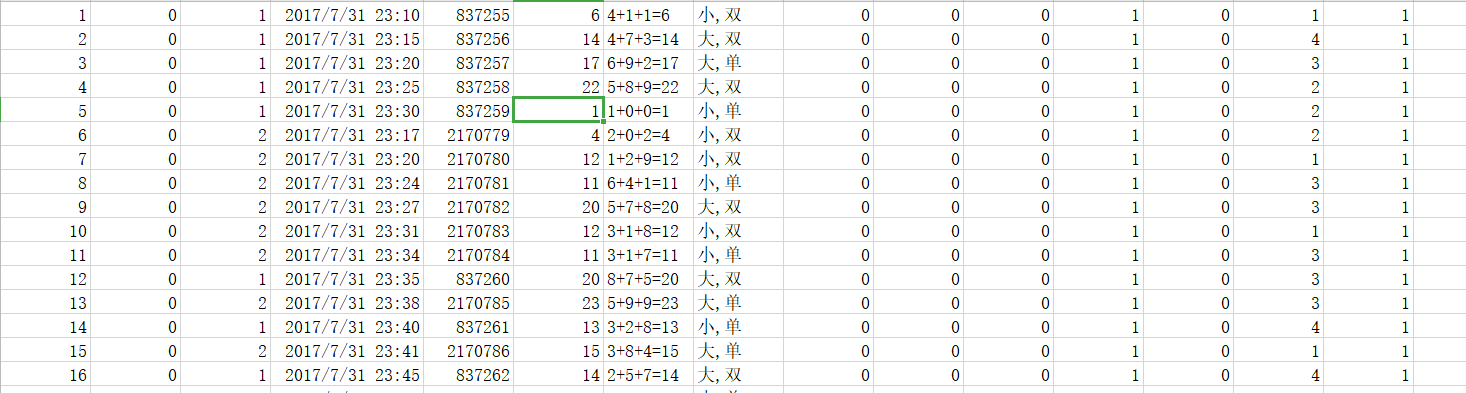
下面我们将一个csv文件进行分开成两个文件,根据他的第六个字段为开奖数进行区分
分区步骤:
Step 1. 定义 Mapper
这个 Mapper 程序不做任何逻辑, 也不对 Key-Value 做任何改变, 只是接收数据, 然后往下发送
package cn.itcast.partition;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
K1:行偏移量 LongWritable
V1:行文本数据 Text
K2:行文本数据 Text
V2:占位符 NUllWritable
*/
public class PartitionMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
//map方法将K1和V1转为K2和V2
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//方式1:自定义计数器
Counter counter = context.getCounter("MY_COUNTER", "partition_counter");
//每运行一次,计数器的变量加1
counter.increment(1L);
context.write(value,NullWritable.get());
}
}
Step 2. 自定义 Partitioner
主要的逻辑就在这里, 这也是这个案例的意义, 通过 Partitioner 将数据分发给不同的 Reducer
package cn.itcast.partition;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<Text, NullWritable> {
/*
1.定义分区规则
2.返回对应的分区编号
*/
@Override
public int getPartition(Text text, NullWritable nullWritable, int i) {
//1.拆分行文本数据(K2),获取中奖字段的值
String s = text.toString().split(" ")[5];
//2.判断中奖字段的值和15的关系,然后返回对应的分区编号
if(Integer.parseInt(s)>15)
return 1;
else
return 0;
}
}
Step 3. 定义 Reducer 逻辑
这个 Reducer 也不做任何处理, 将数据原封不动的输出即可
package cn.itcast.partition;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
K2: 一行的文本数据
V2: NullWritable
K3: Text
V3: NullWritable
*/
public class PartitionerReducer extends Reducer<Text, NullWritable,Text,NullWritable> {
public static enum Counter{
MY_INPUT_RECOREDS,MY_INPUT_BYTES
}
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.getCounter(Counter.MY_INPUT_RECOREDS).increment(1L);
context.write(key,NullWritable.get());
}
}
Step 4. 主类中设置分区类和ReduceTask个数
package cn.itcast.partition;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
//1.创建job任务对象
Job job = Job.getInstance(super.getConf(), "partition_mapreduce");
//job.setJarByClass(JobMain.class);
//2.对job任务进行配置(八个步骤)
//第一步:设置输入类和输入参数
job.setInputFormatClass(TextInputFormat.class);
//TextInputFormat.addInputPath(job,new Path("hdfs://hadoop101:8020/input"));
TextInputFormat.addInputPath(job,new Path("file:///E:\input"));
//第二部:设置mapper类和类型
job.setMapperClass(PartitionMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//第三:指定分区类
job.setPartitionerClass(MyPartitioner.class);
// 第四,五,六步
//第七步:指定Reducer类和数据类型
job.setReducerClass(PartitionerReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置ReduceTask的个数
job.setNumReduceTasks(2);
//第八步:指定输出类和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
//TextOutputFormat.setOutputPath(job,new Path("hdfs://hadoop101:8020/out/partition_out"));
TextOutputFormat.setOutputPath(job,new Path("file:///E:\out\partition_out3"));
//3.等待任务结束
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
//启动job任务
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
结果:会产生两个文件
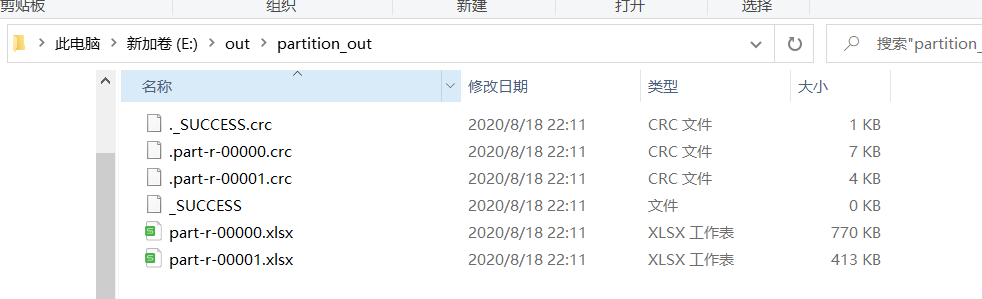
第一个文件里的开奖数都是小于等于15
第二个文件里的开奖数都是大于15的
MapReduce 中的计数器
计数器是收集作业统计信息的有效手段之一,用于质量控制或应用级统计。计数器还可辅助
诊断系统故障。如果需要将日志信息传输到 map 或 reduce 任务, 更好的方法通常是看能否
用一个计数器值来记录某一特定事件的发生。对于大型分布式作业而言,使用计数器更为方
便。除了因为获取计数器值比输出日志更方便,还有根据计数器值统计特定事件的发生次数
要比分析一堆日志文件容易得多。
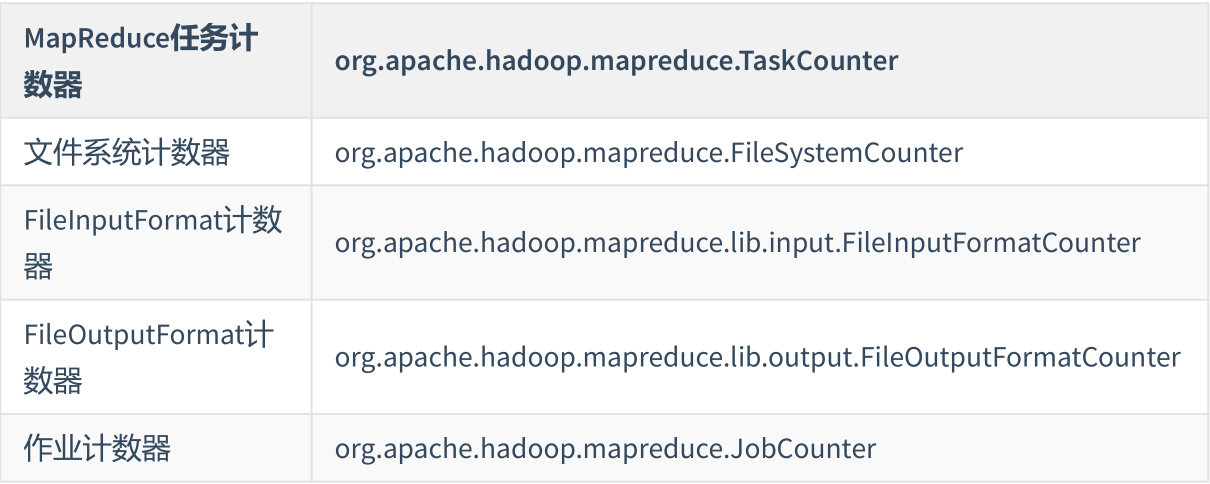
hadoop内置计数器列表
自定义计数器方法
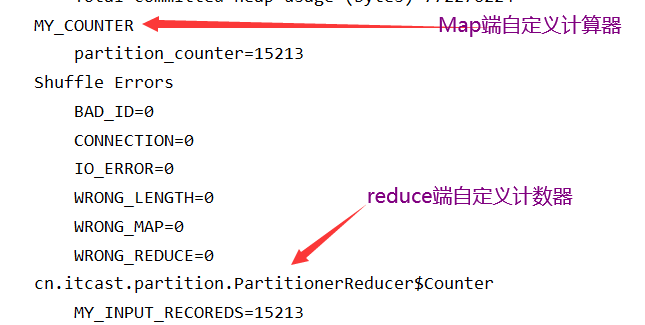
第一种方式定义计数器,通过context上下文对象可以获取我们的计数器,进行记录 通过
context上下文对象,在map端使用计数器进行统计
public class PartitionMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
//map方法将K1和V1转为K2和V2
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//方式1:自定义计数器
Counter counter = context.getCounter("MY_COUNTER", "partition_counter");
//每运行一次,计数器的变量加1
counter.increment(1L);
context.write(value,NullWritable.get());
}
}
第二种方式
通过enum枚举类型来定义计数器 统计reduce端数据的输入的key有多少个
public class PartitionerReducer extends Reducer<Text, NullWritable,Text,NullWritable> {
public static enum Counter{
MY_INPUT_RECOREDS,MY_INPUT_BYTES
}
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.getCounter(Counter.MY_INPUT_RECOREDS).increment(1L);
context.write(key,NullWritable.get());
}
}
输出显示: