SparkSQL简介
SparkSQL 的出现契机
SparkSQL-
- 解决的问题
-
-
Spark SQL使用Hive解析SQL生成AST语法树, 将其后的逻辑计划生成, 优化, 物理计划都自己完成, 而不依赖Hive -
执行计划和优化交给优化器
Catalyst -
内建了一套简单的
SQL解析器, 可以不使用HQL, 此外, 还引入和DataFrame这样的DSL API, 完全可以不依赖任何Hive的组件 -
Shark只能查询文件,Spark SQL可以直接降查询作用于RDD, 这一点是一个大进步
-
- 新的问题
-
对于初期版本的
SparkSQL, 依然有挺多问题, 例如只能支持SQL的使用, 不能很好的兼容命令式, 入口不够统一等
Dataset-
SparkSQL在 2.0 时代, 增加了一个新的API, 叫做Dataset,Dataset统一和结合了SQL的访问和命令式API的使用, 这是一个划时代的进步在
Dataset中可以轻易的做到使用SQL查询并且筛选数据, 然后使用命令式API进行探索式分析
|
重要性
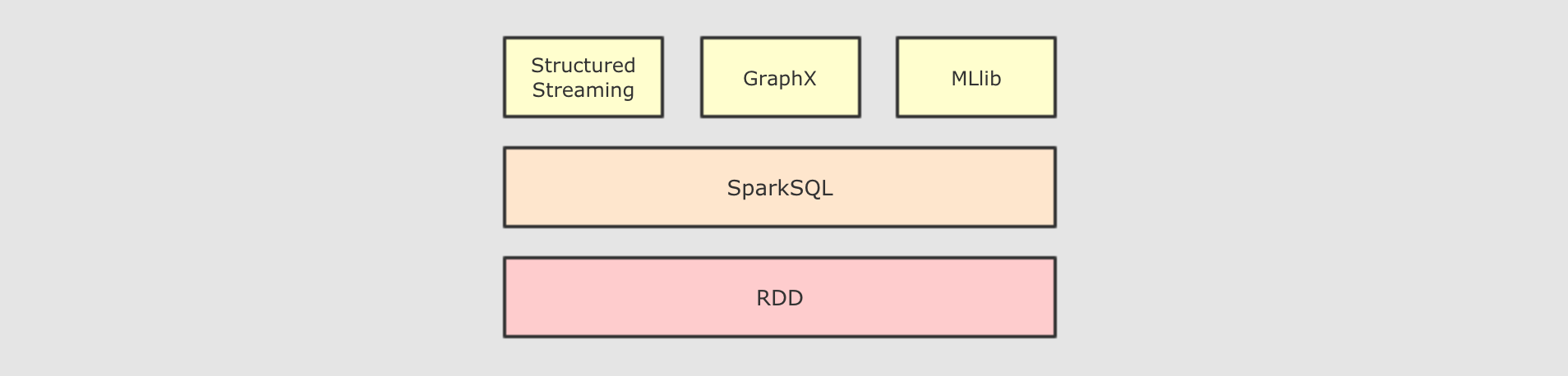
|
SparkSQL 是什么SparkSQL 是一个为了支持 SQL 而设计的工具, 但同时也支持命令式的 API
SparkSQL 的适用场景
| 定义 | 特点 | 举例 | |
|---|---|---|---|
|
结构化数据 |
有固定的 |
有预定义的 |
关系型数据库的表 |
|
半结构化数据 |
没有固定的 |
没有固定的 |
指一些有结构的文件格式, 例如 |
|
非结构化数据 |
没有固定 |
没有固定 |
指文档图片之类的格式 |
- 结构化数据
-
一般指数据有固定的
Schema, 例如在用户表中,name字段是String型, 那么每一条数据的name字段值都可以当作String来使用+----+--------------+---------------------------+-------+---------+ | id | name | url | alexa | country | +----+--------------+---------------------------+-------+---------+ | 1 | Google | https://www.google.cm/ | 1 | USA | | 2 | 淘宝 | https://www.taobao.com/ | 13 | CN | | 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN | | 4 | 微博 | http://weibo.com/ | 20 | CN | | 5 | Facebook | https://www.facebook.com/ | 3 | USA | +----+--------------+---------------------------+-------+---------+ - 半结构化数据
一般指的是数据没有固定的 Schema, 但是数据本身是有结构的
{
"firstName": "John",
"lastName": "Smith",
"age": 25,
"phoneNumber":
[
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "fax",
"number": "646 555-4567"
}
]
}- 没有固定
Schema -
指的是半结构化数据是没有固定的
Schema的, 可以理解为没有显式指定Schema
比如说一个用户信息的JSON文件, 第一条数据的phone_num有可能是String, 第二条数据虽说应该也是String, 但是如果硬要指定为BigInt, 也是有可能的
因为没有指定Schema, 没有显式的强制的约束
SparkSQL处理什么数据的问题?-
-
Spark的RDD主要用于处理 非结构化数据 和 半结构化数据 -
SparkSQL主要用于处理 结构化数据
-
SparkSQL相较于RDD的优势在哪?-
-
SparkSQL提供了更好的外部数据源读写支持-
因为大部分外部数据源是有结构化的, 需要在
RDD之外有一个新的解决方案, 来整合这些结构化数据源
-
-
SparkSQL提供了直接访问列的能力-
因为
SparkSQL主要用做于处理结构化数据, 所以其提供的API具有一些普通数据库的能力
-
-
SparkSQL 适用于什么场景?SparkSQL 适用于处理结构化数据的场景
SparkSQL 初体验
命令式 API 的入门案例
@Test def dsIntro(): Unit ={ val spark=new SparkSession.Builder() .appName("ds intro") .master("local[6]") .getOrCreate() import spark.implicits._ val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15), Person("wangwu", 30))) val personDS = sourceRDD.toDS() val result=personDS.where('age>10) .where('age<20) .select('name) .as[String] result.show() }
SparkSQL 中有一个新的入口点, 叫做 SparkSessionSparkSQL 中有一个新的类型叫做 DatasetSparkSQL 有能力直接通过字段名访问数据集, 说明 SparkSQL 的 API 中是携带 Schema 信息的
DataFrame & Dataset
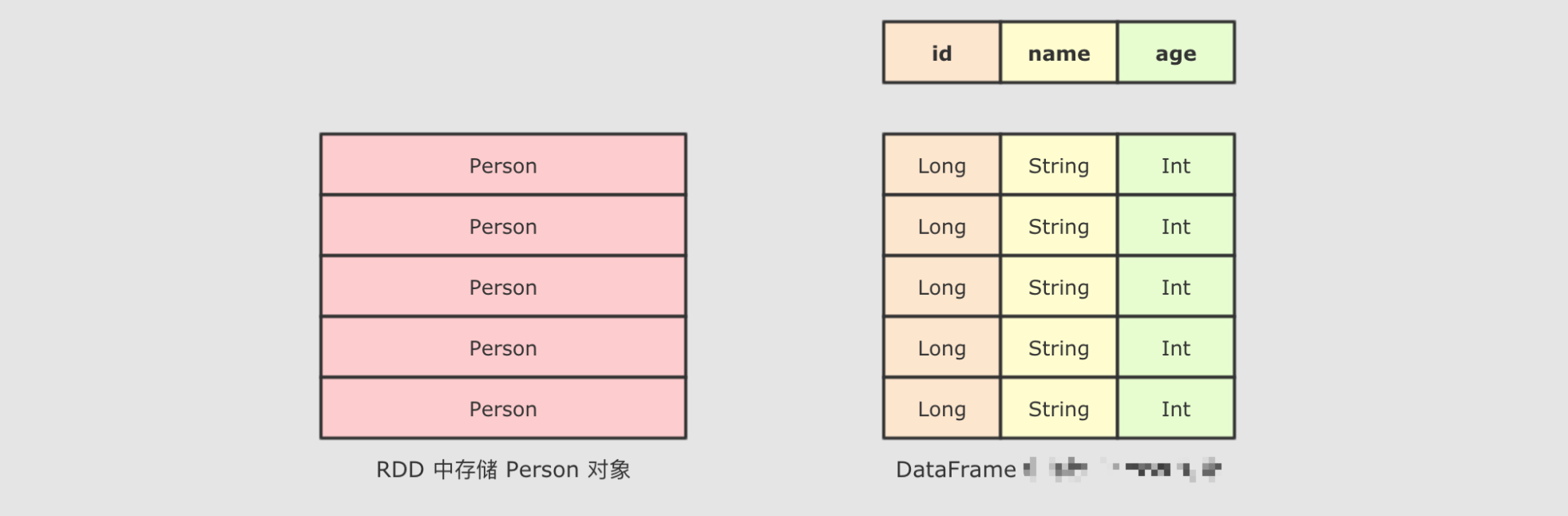
sparkSQL 对外提供的 API 有两类:SQL, 另外一类就是命令式. SparkSQL 提供的命令式 API 就是 DataFrame 和 Dataset, 暂时也可以认为 DataFrame 就是 Dataset, 只是在不同的 API 中返回的是 Dataset 的不同表现形式// RDD
rdd.map { case Person(id, name, age) => (age, 1) }
.reduceByKey {case ((age, count), (totalAge, totalCount)) => (age, count + totalCount)}
// DataFrame
df.groupBy("age").count("age")通过上面的代码, 可以清晰的看到, SparkSQL 的命令式操作相比于 RDD 来说, 可以直接通过 Schema 信息来访问其中某个字段, 非常的方便
SQL版本方式
@Test def dfIntro(): Unit ={ val spark=new SparkSession.Builder() .appName("ds intro") .master("local[6]") .getOrCreate() import spark.implicits._ val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15), Person("wangwu", 30))) val df = sourceRDD.toDF() df.createOrReplaceTempView("person") val result = spark.sql("select name from person where age>10 and age <20") result.show() }
以往使用 SQL 肯定是要有一个表的, 在 Spark 中, 并不存在表的概念, 但是有一个近似的概念, 叫做 DataFrame, 所以一般情况下要先通过 DataFrame 或者 Dataset 注册一张临时表, 然后使用 SQL 操作这张临时表
SparkSQL 提供了 SQL 和 命令式 API 两种不同的访问结构化数据的形式, 并且它们之间可以无缝的衔接
命令式 API 由一个叫做 Dataset 的组件提供, 其还有一个变形, 叫做 DataFrame
Dataset 的特点
Dataset 是什么?
@Test def dataset1(): Unit ={ //1.创建SparkSession val spark=new SparkSession.Builder() .appName("dataset1") .master("local[6]") .getOrCreate() //2.导入隐式转换 import spark.implicits._ //3.演示 val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15), Person("wangwu", 30))) val ds = sourceRDD.toDS() //DataSet 支持强类型的API ds.filter( item => item.age>10).show() //DataSet 支持弱类型的API ds.filter('age>10).show() ds.filter($"age">10).show() //DataSet 可以直接编写SQL 表达式 ds.filter("age >10").show() }
Dataset 是一个强类型, 并且类型安全的数据容器, 并且提供了结构化查询 API 和类似 RDD 一样的命令式 API
可以获取 Dataset 对应的 RDD 表示:
- 使用
Dataset.rdd将Dataset转为RDD的形式 Dataset的执行计划底层的RDD
DataFrame 的作用和常见操作
DataFrame 是什么?
DataFrame 中有 Schema 信息, 可以像操作表一样操作 DataFrame.
DataFrame 由两部分构成, 一是 row 的集合, 每个 row 对象表示一个行, 二是描述 DataFrame 结构的 Schema.
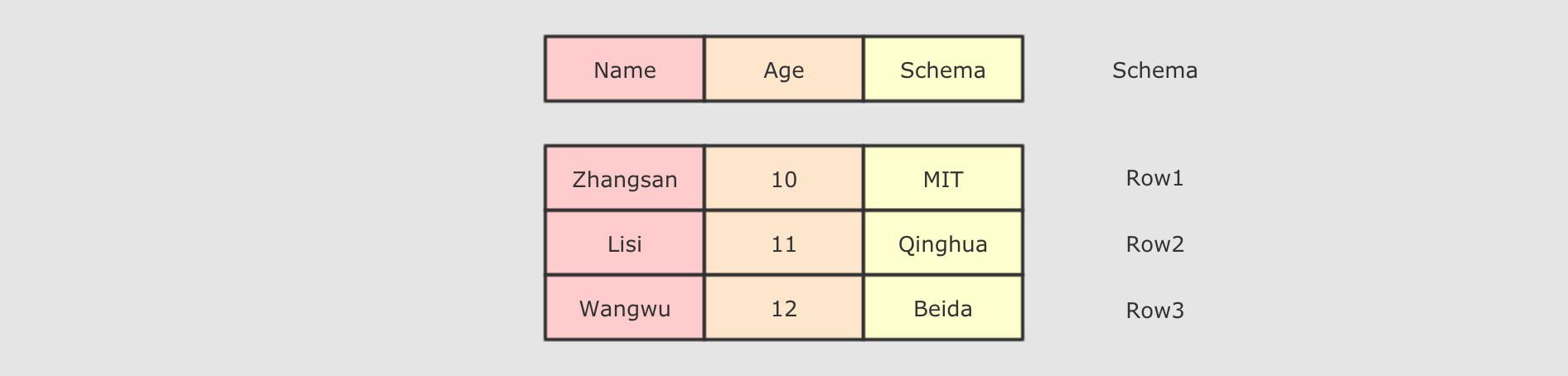
DataFrame 支持 SQL 中常见的操作, 例如: select, filter, join, group, sort, join 等
@Test def dataframe1(): Unit ={ //1.创建SparkSession val spark=SparkSession.builder() .appName("datafreame1") .master("local[6]") .getOrCreate() //2.创建DataFrame import spark.implicits._ val dataFrame = Seq(Person("zhangsan", 15), Person("lisi", 20)).toDF() //3.DataFrame花样 dataFrame.where('age>10) .select('name) .show() }
通过集合创建 DataFrame 的时候, 集合中不仅可以包含样例类, 也可以只有普通数据类型, 后通过指定列名来创建
//1.创建SparkSession val spark=SparkSession.builder() .appName("datafreame1") .master("local[6]") .getOrCreate() //2.创建DataFrame import spark.implicits._ val personList = Seq(Person("zhangsan", 15), Person("lisi", 20)) //1.toDF val df1=personList.toDF() val df2=spark.sparkContext.parallelize(personList).toDF()
在 DataFrame 上可以使用的常规操作
DataFrame 的 Schema, 查看其中所包含的列, 以及列的类型val spark: SparkSession = new sql.SparkSession.Builder() .appName("hello") .master("local[6]") .getOrCreate() val df = spark.read .option("header", true) .csv("dataset/BeijingPM20100101_20151231.csv") df.printSchema()
Step 2: 对于大部分计算来说, 可能不会使用所有的列, 所以可以选择其中某些重要的列
df.select('year, 'month, 'PM_Dongsi)
Step 3: 可以针对某些列进行分组, 后对每组数据通过函数做聚合
df.select('year, 'month, 'PM_Dongsi)
.where('PM_Dongsi =!= "Na")
.groupBy('year, 'month)
.count()
.show()
使用 SQL 操作 DataFrame
@Test def dataframe3(): Unit ={ //1.创建SparkSession val spark=SparkSession.builder() .appName("datafreame1") .master("local[6]") .getOrCreate() //2.读取数据集 import spark.implicits._ val dataFrame = spark.read .option("header",value = true) .csv("dataset/BeijingPM20100101_20151231.csv") //3.处理 //处理一 // dataFrame.select('year,'month,'PM_Dongsi) // .where('PM_Dongsi =!= "NA") // .groupBy('year,'month) // .count() // .show() //处理二 dataFrame.createOrReplaceTempView("pm") val result=spark.sql("select year,month,count(PM_Dongsi) from pm where PM_Dongsi != 'NA' group by year,month") result.show() spark.stop() //4.得出结论 }
-
DataFrame是一个类似于关系型数据库表的函数式组件 -
DataFrame一般处理结构化数据和半结构化数据 -
DataFrame具有数据对象的 Schema 信息 -
可以使用命令式的
API操作DataFrame, 同时也可以使用SQL操作DataFrame -
DataFrame可以由一个已经存在的集合直接创建, 也可以读取外部的数据源来创建
Dataset 和 DataFrame 的异同
DataFrame 就是 Dataset
第一点: DataFrame 表达的含义是一个支持函数式操作的 表, 而 Dataset 表达是是一个类似 RDD 的东西, Dataset 可以处理任何对象
- 第二点:
DataFrame中所存放的是Row对象, 而Dataset中可以存放任何类型的对象 - 第三点:
DataFrame的操作方式和Dataset是一样的, 但是对于强类型操作而言, 它们处理的类型不同 - 第四点:
DataFrame只能做到运行时类型检查,Dataset能做到编译和运行时都有类型检查
@Test def qubie(): Unit ={ //1.创建SparkSession val spark=SparkSession.builder() .appName("datafreame1") .master("local[6]") .getOrCreate() //2.创建DataFrame import spark.implicits._ val personList = Seq(Person("zhangsan", 15), Person("lisi", 20)) //DataFrame 是弱类型 val df=personList.toDF() df.map( (row:Row) =>Row(row.get(0),row.getAs[Int](1)*2) )(RowEncoder.apply(df.schema)) .show() //DataFrame 所代表的弱类型操作编译不安全 df.groupBy("name,age") //Dataset 是强类型 val ds=personList.toDS() ds.map( (person:Person) => Person(person.name,person.age*2) ) .show() //Dataset 所代表的强类型操作编译运行都安全 // ds.filter(person =>person.age) }
Row 是什么?
Row 对象表示的是一个 行
Row 的操作类似于 Scala 中的 Map 数据类型
@Test def row(): Unit ={ //1.row如何创建,他是什么 val p=Person("zhangsan",14) val row=Row("zhangsan",14) //2.如何从row中获取数据 println(row.getString(0)) println(row.getInt(1)) //3.Row是样例类 row match { case Row(name,age) => println(name,age) }
DataFrame 和 Dataset 之间可以非常简单的相互转换
val spark: SparkSession = new sql.SparkSession.Builder() .appName("hello") .master("local[6]") .getOrCreate() import spark.implicits._ val df: DataFrame = Seq(People("zhangsan", 15), People("lisi", 15)).toDF() val ds_fdf: Dataset[People] = df.as[People] val ds: Dataset[People] = Seq(People("zhangsan", 15), People("lisi", 15)).toDS() val df_fds: DataFrame = ds.toDF()
总结
-
DataFrame就是Dataset, 他们的方式是一样的, 也都支持API和SQL两种操作方式 -
DataFrame只能通过表达式的形式, 或者列的形式来访问数据, 只有Dataset支持针对于整个对象的操作 -
DataFrame中的数据表示为Row, 是一个行的概念
数据读写
DataFrameReader
DataFrameReader 由如下几个组件组成
| 组件 | 解释 |
|---|---|
|
|
结构信息, 因为 |
|
|
连接外部数据源的参数, 例如 |
|
|
外部数据源的格式, 例如 |
@Test def reader1(): Unit ={ //1.创建SparkSession val spark=SparkSession.builder() .appName("reader1") .master("local[6]") .getOrCreate() //2.框架 val read: DataFrameReader = spark.read }
DataFrameReader 有两种访问方式, 一种是使用 load 方法加载, 使用 format 指定加载格式, 还有一种是使用封装方法, 类似 csv, json, jdbc 等
@Test def reader2(): Unit ={ //1.创建SparkSession val spark=SparkSession.builder() .appName("reader1") .master("local[6]") .getOrCreate() //2.第一种形式 spark.read .format("csv") .option("header",value = true) .option("inferSchema",value = true) .load("dataset/BeijingPM20100101_20151231.csv") .show() //3.第二种形式 spark.read .option("header",value = true) .option("inferSchema",value = true) .csv("dataset/BeijingPM20100101_20151231.csv") .show(10) }
DataFrameWriter
DataFrameWriter 中由如下几个部分组成
| 组件 | 解释 |
|---|---|
|
|
写入目标, 文件格式等, 通过 |
|
|
写入模式, 例如一张表已经存在, 如果通过 |
|
|
外部参数, 例如 |
|
|
类似 |
|
|
类似 |
|
|
用于排序的列, 通过 |
mode 指定了写入模式, 例如覆盖原数据集, 或者向原数据集合中尾部添加等
Scala 对象表示 | 字符串表示 | 解释 |
|---|---|---|
|
|
|
将 |
|
|
|
将 |
|
|
|
将 |
|
|
|
将
|
DataFrameWriter 也有两种使用方式, 一种是使用 format 配合 save, 还有一种是使用封装方法, 例如 csv, json, saveAsTable 等@Test def writer1(): Unit = { //2.读取数据集 val df=spark.read.option("header",true).csv("dataset/BeijingPM20100101_20151231.csv") //3.写入数据集 df.write.json("dataset/bejing_pm.json") df.write.format("json").save("dataset/beijing_pm2.json") }
读写 Parquet 格式文件
读写 Parquet 文件:
@Test def parquet(): Unit = { //2.读取数据集 val df = spark.read.option("header", true).csv("dataset/BeijingPM20100101_20151231.csv") df.write .mode(SaveMode.Overwrite) .format("parquet") .save("dataset/beijing_pm3") spark.read .load("dataset/beijing_pm3") .show() }
写入 Parquet 的时候可以指定分区
Spark 在写入文件的时候是支持分区的, 可以像 Hive 一样设置某个列为分区列
@Test def parquetPartitions(): Unit ={ val df = spark.read.option("header", true).csv("dataset/BeijingPM20100101_20151231.csv") //2.写文件 表分区 //写分区的时候,分区列不会包含在生成的文件中 //直接通过文件来读取,分区信息会丢失 //spark sql 会进行自动分区发现 df.write .partitionBy("year","month") .save("dataset/beijing_pm4") //3.读文件,自动发现分区 spark.read .parquet("dataset/beijing_pm4") .printSchema() }
读写 JSON 格式文件
@Test def json(){ val df = spark.read.option("header", true).csv("dataset/BeijingPM20100101_20151231.csv") df.write .json("dataset/beijing_pm5.json") spark.read .json("dataset/beijing_pm5.json") .show() }
Spark 可以从一个保存了 JSON 格式字符串的 Dataset[String] 中读取 JSON 信息, 转为 DataFrame
@Test def json2(): Unit ={ val df = spark.read.option("header", true).csv("dataset/BeijingPM20100101_20151231.csv") //直接从rdd读取json的DataFrame val jsonrdd = df.toJSON.rdd spark.read.json(jsonrdd).show() }
访问 Hive
启动 Hive MetaStore
nohup /export/servers/hive/bin/hive --service metastore 2>&1 >> /var/log.log &
访问 Hive 表
在 Hive 中创建表
第一步, 需要先将文件上传到集群中, 使用如下命令上传到 HDFS 中
hdfs dfs -mkdir -p /dataset
hdfs dfs -put studenttabl10k /dataset/
第二步, 使用 Hive 或者 Beeline 执行如下 SQL
CREATE DATABASE IF NOT EXISTS spark_integrition; USE spark_integrition; CREATE EXTERNAL TABLE student ( name STRING, age INT, gpa string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LINES TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/dataset/hive';
第三步:将hdfs上的文件,加载到该表
LOAD DATA INPATH '/dataset/studenttab10k' OVERWRITE INTO TABLE student;
通过 SparkSQL 查询 Hive 的表
scala> spark.sql("use spark_integrition")
scala> val resultDF = spark.sql("select * from student limit 10")
scala> resultDF.show()
通过 SparkSQL 创建 Hive 表
val createTableStr = """ |CREATE EXTERNAL TABLE student |( | name STRING, | age INT, | gpa string |) |ROW FORMAT DELIMITED | FIELDS TERMINATED BY ' ' | LINES TERMINATED BY ' ' |STORED AS TEXTFILE |LOCATION '/dataset/hive' """.stripMargin spark.sql("CREATE DATABASE IF NOT EXISTS spark03") spark.sql("USE spark03") spark.sql(createTableStr) spark.sql("LOAD DATA INPATH '/dataset/studenttab10k' OVERWRITE INTO TABLE student") spark.sql("select * from student limit 100").show()
使用 SparkSQL 处理数据并保存进 Hive 表
package cn.itcast.spark.sql import org.apache.spark.sql.{SaveMode, SparkSession} import org.apache.spark.sql.types.{FloatType, IntegerType, StringType, StructField, StructType} object HiveAccess { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("hive example") .config("spark.sql.warehouse.dir", "hdfs://hadoop101:8020/dataset/hive") .config("hive.metastore.uris", "thrift://hadoop101:9083") .enableHiveSupport() .getOrCreate() import spark.implicits._ //读取数据 val schema = StructType( List( StructField("name", StringType), StructField("age", IntegerType), StructField("gpa", FloatType) ) ) val studentDF = spark.read .option("delimiter", " ") .schema(schema) .csv("hdfs://hadoop101:8020/dataset/studenttab10k") val resultDF = studentDF.where('age < 50) //写入 resultDF.write.mode(SaveMode.Overwrite).saveAsTable("spark03.student") } }
打包后:通过spark-submit来运行
bin/spark-submit --class cn.itcast.spark.rdd.WordCount --master spark://hadoop101:7077 ~/original-spark-1.0-SNAPSHOT.jar
然后去hive中查看:

JDBC
package cn.itcast.spark.sql import org.apache.spark.sql.{SaveMode, SparkSession} import org.apache.spark.sql.types.{FloatType, IntegerType, StringType, StructField, StructType} object Mysql { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("mysql example") .master("local[6]") .getOrCreate() val schema = StructType( List( StructField("name", StringType), StructField("age", IntegerType), StructField("gpa", FloatType) ) ) val studentDF = spark.read //分隔符:制表符 .option("delimiter", " ") .schema(schema) .csv("dataset/studenttab10k") studentDF.write .format("jdbc") .mode(SaveMode.Overwrite) .option("url", "jdbc:mysql://hadoop101:3306/spark02") .option("dbtable", "student") .option("user", "spark") .option("password", "fengge666") .save() } }
SparkSQL 中并没有直接提供按照 SQL 进行筛选读取数据的 API 和参数, 但是可以通过 dbtable 来曲线救国, dbtable 指定目标表的名称, 但是因为 dbtable 中可以编写 SQL, 所以使用子查询即可做到
| 属性 | 含义 |
|---|---|
|
|
指定按照哪一列进行分区, 只能设置类型为数字的列, 一般指定为 |
|
|
确定步长的参数, |
|
|
分区数量 |
spark.read.format("jdbc")
.option("url", "jdbc:mysql://node01:3306/spark_test")
.option("dbtable", "(select name, age from student where age > 10 and age < 20) as stu")
.option("user", "spark")
.option("password", "Spark123!")
.option("partitionColumn", "age")
.option("lowerBound", 1)
.option("upperBound", 60)
.option("numPartitions", 10)
.load()
.show()
