Word2vec构造情感字典
基本含义
基于Word2vec的字向量能从大量未标注的普通文本数据中无监督地学习到字向量,而且这些字向量包含了字与字之间的语义关系,正如现实世界中的“物以类聚,类以群分”一样,字可以由它们身边的字来定义。
从原理上讲,基于字嵌入的Word2vec是指把一个维数为所有字的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单字被映射为实数域上的向量。把每个单字变成一个向量,目的还是为了方便计算,比如“求单字A的同义字”,就可以通过“求与单字A在cos距离下最相似的向量”来做到。相关案例可参看《作为一个合格的“增长黑客”,你还得重视外部数据的分析!》。下面是基于Word2vec的字向量模型原理示意图。

情感字典
首先加载咱们的诗词数据,进行切分,然后用word2vec进行训练
然后将我们需要的七中情感词进行关联词查找,并保存至对应的表中
from gensim import models
from gensim.models.word2vec import Word2Vec
import os
def split_poetry(file='qi_jueju.txt'):
all_data=open(file,"r",encoding="utf-8").read()
# all_data=all_data.replace(',','').replace('。','')
all_data_split=" ".join(all_data)
with open("split.txt", "w", encoding='utf-8') as f:
f.write(all_data_split)
def train_vec(split_file='split.txt'):
#word2vec模型
vec_params_file= "vec_params.pkl"
#判断切分文件是否存在,不存在进行切分
if os.path.exists(split_file)==False:
split_poetry()
#读取切分的文件
split_all_data=open(split_file,"r",encoding="utf-8").read().split("\n")
#存在模型文件就去加载,返回数据即可
if os.path.exists(vec_params_file):
return Word2Vec.load(vec_params_file)
#词向量大小:vector_size,构造word2vec模型,字维度107,只要出现一次就统计该字,workers=6同时工作
embedding_num=128
model=Word2Vec(split_all_data,vector_size=embedding_num,min_count=1,workers=6)
#保存模型
model.save(vec_params_file)
return model
if __name__ == '__main__':
model=train_vec()
emotion=['悲','惧','乐','怒','思','喜','忧']
em_list={}
for e in emotion:
res = model.wv.most_similar(e, topn=100)
lists=[]
lists.append(e)
for item in res:
print(item[0] + "," + str(item[1]))
lists.append(item[0])
em_list[e]=",".join(lists)
import xlwt
xl = xlwt.Workbook()
# 调用对象的add_sheet方法
sheet1 = xl.add_sheet('sheet1', cell_overwrite_ok=True)
sheet1.write(0, 0, "emotion")
sheet1.write(0, 1, 'similar')
i=0
for k in em_list.keys():
sheet1.write(i + 1, 0, emotion[i])
sheet1.write(i + 1, 1, em_list[k])
i+=1
xl.save("emotion.xlsx")
结果:

情感分析
任选一首古诗,对其进行单句切分,分析每个句子的情感,然后进行汇总,预测整首诗的情感
import pandas as pd
def emotion():
data=pd.read_excel('emotion.xlsx')
similar=data.get('similar')
sad_list=str(similar[0]).split(',')
fear_list=str(similar[1]).split(',')
happy_list=str(similar[2]).split(',')
anger_list=str(similar[3]).split(',')
think_list=str(similar[4]).split(',')
like_list=str(similar[5]).split(',')
worry_list=str(similar[6]).split(',')
return sad_list,fear_list,happy_list,anger_list,think_list,like_list,worry_list
def test_sentence(sentence):
sad_list, fear_list, happy_list, anger_list, think_list, like_list, worry_list=emotion()
sad=fear=happy=anger=think=like=worry=0
for k in sentence:
if k in sad_list:
sad+=1
elif k in fear_list:
fear+=1
elif k in happy_list:
happy+=1
elif k in anger_list:
anger+=1
elif k in think_list:
think+=1
elif k in like_list:
like+=1
elif k in worry_list:
worry+=1
ans=max(sad,fear,happy,anger,think,like,worry)
scord_list=[]
scord_list.append(sad)
scord_list.append(fear)
scord_list.append(happy)
scord_list.append(anger)
scord_list.append(think)
scord_list.append(like)
scord_list.append(worry)
emotion_list=['悲','惧','乐','怒','思','喜','忧']
i=0
for i in range(len(scord_list)):
if scord_list[i]==ans:
print(emotion_list[i])
break
return emotion_list[i]
def read():
data=pd.read_excel('tang.xlsx')
content_list=data.get('content')
for i in range(len(content_list)):
content=content_list[i].replace('\n','')
ans_content=[]
content_l=str(content).split('。')
for k in content_l:
kk=str(k).split(',')
for it in kk:
if it!='':
ans_content.append(it)
ans_emotion = {}
for sentence in ans_content:
print(sentence)
emot=test_sentence(sentence)
if emot not in ans_emotion.keys():
ans_emotion[emot] = 1
else:
ans_emotion[emot]+=1
print(sorted(ans_emotion.items(), key=lambda item: item[1], reverse=True))
ans_emotion=dict(sorted(ans_emotion.items(), key=lambda item: item[1], reverse=True))
for key,value in ans_emotion.items():
print('整篇文章情感:'+key)
break
break
if __name__ == '__main__':
read()
例如:宗武生日

原诗鉴赏:
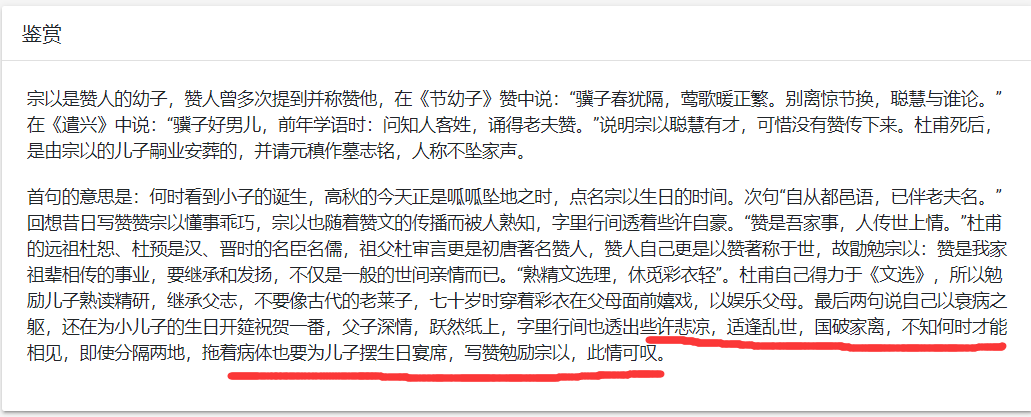
还是比较吻合的