写在前面
从今天开始的几篇文章,我将就国内目前比较主流的一些在线学习平台数据进行抓取,如果时间充足的情况下,会对他们进行一些简单的分析,好了,平台大概有51CTO学院,CSDN学院,网易云课堂,慕课网等平台,数据统一抓取到mongodb里面,如果对上述平台造成了困扰,请见谅,毕竟我就抓取那么一小会的时间,不会对服务器有任何影响的。
1. 目标网站
今天的目标网站是 http://edu.51cto.com/courselist/index.html?edunav 数据量大概在1W+,还不错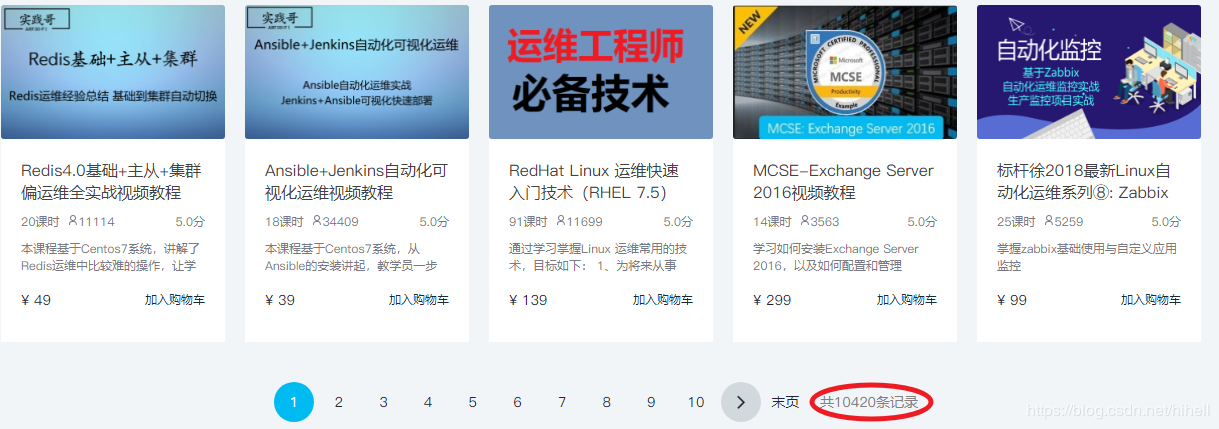
2. 分析页面需要的信息
下图标注的框框,就是我们需要的信息了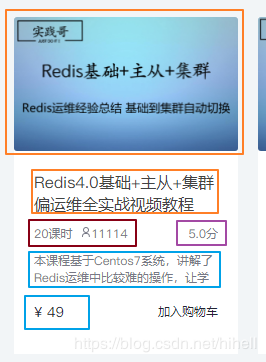
如果查看源码,我们还能得到其他有价值的隐藏信息,也同时的抓取到,另外,今天的主题不是下载图片,所以针对课程缩略图,我只保留一个图片链接到mongodb里面,就不做单独的处理了。
在开发者工具中,继续检索有用信息。发现一个独家 这个信息看似有用唉,可以做保留。

3. 分析爬取方式
分析完毕就是要爬取操作了,看一下这个网站是否是ajax动态加载的,如果不是,那么就采用最笨的办法爬取。
查阅网站源代码之后,发现没有异步数据。
采用URL拼接的方式爬取即可。
URL规律如下,因为数据相对变化不大,末尾的页码是417,所以URL直接生成就可以了。
https://edu.51cto.com/courselist/index-p2.htmlhttps://edu.51cto.com/courselist/index-p3.html
https://edu.51cto.com/courselist/index-p4.html
https://edu.51cto.com/courselist/index-p5.html
...
http://edu.51cto.com/courselist/index-p417.html
今天主要使用requests-html这个库。
我们拿51cto学院,完整的练个手。
from requests_html import HTMLSession
BASE_URL = "http://edu.51cto.com/courselist/index-p{}.html"
def get_content():
session = HTMLSession()
r = session.get(BASE_URL)
print(r.html)
if __name__ == '__main__':
get_content()
使用上面的代码,就能快速的获取到一个请求的响应了。
继续编写下面几行代码之后,你不得不惊叹,我去~,数据都获取到了!
print(r.html)
print(r.html.links)
print(r.html.absolute_links) # 获取所有的绝对地址
print(r.html.find('.cList',first=True)) # 获取class=cList的第一个标签
c_list = r.html.find('.cList',first=True)
print(c_list.text)当然这些对咱来说还是远远不够的,毕竟我们要把他写入mongodb里面
上面的只是叫你对这个库有一个基本的认知,更多的资料你可以去他的教程网站查阅
http://html.python-requests.org/
4. 分析爬取方式
看一下异步方式,异步的出现可以为我们的爬虫加速
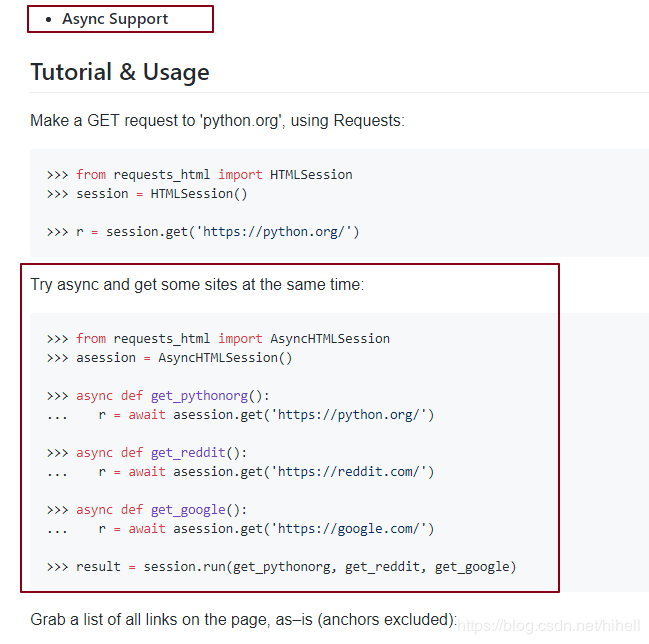
这个地方有一个你一定要注意的,我写这篇文章的时候,requests-html 是从github下载之后,更新的本次,你如果之前使用pip进行安装,那么异步应该是没有更新上去的。
好了,接下来我们实现一下异步,可能由于作者认为异步目前不是很稳定,所以我查阅了一下他的源码,然后实现了如下代码,写的不好,请见谅~
下面的代码,注意看模块的区别,以及核心的异步函数
async def get_html():
for i in range(1,3):
r = await asession.get(BASE_URL.format(i)) # 异步等待
get_item(r.html)
if __name__ == '__main__':
result = asession.run(get_html)
from requests_html import AsyncHTMLSession # 导入异步模块
asession = AsyncHTMLSession()
BASE_URL = "http://edu.51cto.com/courselist/index-p{}.html"
async def get_html():
for i in range(1,418):
r = await asession.get(BASE_URL.format(i)) # 异步等待
get_item(r.html)
def get_item(html): c_list=html.find('.cList',first=True) if c_list: items=c_list.find('.cList_Item') for item in items: title=item.find("h3",first=True).text href=item.find('h3>a',first=True).attrs["href"] class_time=item.find("div.course_infos>p:eq(0)",first=True).text study_nums = item.find("div.course_infos>p:eq(1)", first=True).text stars=item.find("div.course_infos>div",first=True).attrs['val'] course_target=item.find(".main>.course_target",first=True).text if item.find(".price>h4", first=True): price = item.find(".price>h4", first=True).text elif item.find(".price>span", first=True): price = item.find(".price>span", first=True).text dict = { "title": title, "href": href, "class_time": class_time, "study_nums": study_nums, "stars": stars, "course_target": course_target, "price": price } print(dict) else: print("数据解析失败")
if __name__ == '__main__':
result = asession.run(get_html) 代码运行之后,控制台就会输出相应的内容,上述代码中有个地方用到了大量的解析HTML,这个你搜索一下官方文档就可以看明白,不进行过多的解释。

5. 写入到mongodb里面
这部分代码就非常非常简单了
结果如下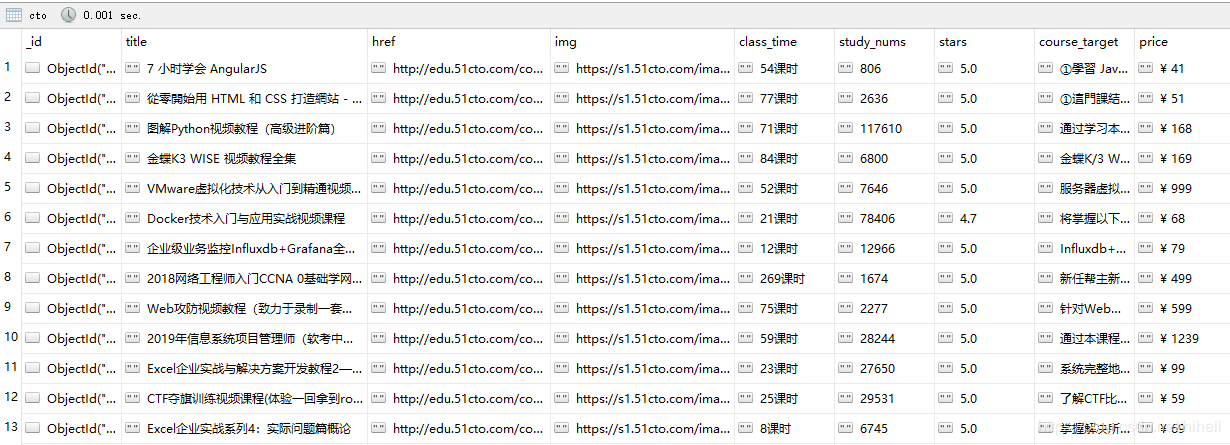
实际的爬取过程中,也没有发现反爬虫的一些限制,不过咱毕竟是为了研究一下requests-html的用法,所以只能对51CTO网站说一句多有得罪,罪过罪过。