MapReduce概述
MapReduce是一种分布式计算模型,运行时不会在一台机器上运行.hadoop是分布式的,它是运行在很多的TaskTracker之上的.
在我们的TaskTracker上面跑的是Map或者是Reduce Task任务.
通常我们在部署hadoop taskTracker 的时候,我们的TaskTracker同时还是我们的Datanode节点.datanode和tasktracker总是部署在一起的.
MapReduce执行流程:
为什么要有多个datanode:
因为我们的datanode是专门用来存储数据的,我们的数据很大,在一个节点上是存不下的,存不下的情况下,我们就把数据存放在多个节点上.
MapReduce:分布式计算模型.把我们的程序代码分到所有的tasktracker节点上去运行.只处理当前datanode上的数据,datanode和程序代码都在一台机器上处理,避免了网络传输.
我们的代码拿到tasktracker上去执行,我们的tasktracker执行的数据来源于datanode,我们的程序就把各个datanode上的数据给处理了.
reduce汇总的是这种map的输出,map处理的数据来自于datanode,但是map程序处理后的结果不一定放在datanode中,可以放到linux磁盘.reduce处理的数据来自于各个数据处理节点的linux磁盘.reduce处理完之后的输出放到datanode上.
如果有节点空闲,reduce节点就在空闲节点上运行,如果都跑程序,就随机一个节点跑reduce
tasktracker处理的任务都是来自于datanode,处理数据是并行的.map处理完之后结果放到linux磁盘上.r educe程序的处理,是把map处理后linux磁盘上的数据都汇总到reduce节点处理,reduce处理完之后,将结果输出到datanode上.
我们的数据是放在hdfs中,hdfs决定把数据是放在哪个datanode上的,决定的权利不在于我们的处理,而是在于hdfs.到底放在哪个datanode上不需要我们去关心.
datanode有副本,数据在进行存储的时候,是把数据放到多个datanode上.
并行处理数据,把我们处理问题的应用程序放到各个存放数据的节点上进行处理,处理完之后获得的是每一个本地的数据,通过redcue把各个本地的数据进行汇总起来,就得到一个最终的结果.reduce可以有多个.
原来集中式的数据处理方式,缺点是海量数据移动到一个数据处理节点上,程序运行的大量时间消耗在网络传输上.串行,性能不好.
把计算程序放到存储数据的各个节点上并行执行.map程序计算本地节点的数据,并行结束后,会有很多的中间结果,reduce程序是把Map程序运行的中间结果汇总到一起,作为最终结果.
原来的这种处理数据的方式,是把应用程序放到一个地方,然后海量的数据不断的往这个应用上挪,它的大量时间消耗在网络传输上还有磁盘的io上.程序处理起来并不复杂,因为数据量太大,所以把时间都耗费到这上面了.
我们改进行一下计算方法,把我们的小程序放到各个的数据节点上,map程序就去处理本机的数据,每一个map程序都去处理本机的数据,处理完之后,会得到多个中间结果.
map处理本地操作可以节省网络传输,在本地就可以把数据处理了.map程序适合于计算的本地化.我们的Reduce程序不能实现计算的本地化,因为是汇总map的输出,map的输出必然会分布在很多的机器上.
我们的map是放在各个tasktracker上去执行的,就是把各个tasktracker的本地数据给处理掉,处理后会得到一个中间结果,reduce程序就会各个map处理的结果给汇总起来,mapreduce在这里就是这么一个过程,map是处理各个节点的.reduce是汇总map输出的.
MapReduce是一个分布式计算模型,主要是用来处理海量数据的.
MapReduce原理:
MapReduce计算模型包括Map和Reduce两个阶段,我们用户只需要处理map阶段和reduce阶段就行了.
1) map用来处理本机数据,在处理本地的数据时,需要想我的数据存放在本机的什么位置,我要进行什么样的计算,计算结果我要放在本机的什么位置.这些东西都是由mapreduce框架给我们实现的,数据在哪,我们只需要知道hdfs就行了,数据处理之后的中间结果放在哪,这个也是mapreduce框架给我们做的,我们自己不需要管.
2) reduce是把map输出的结果给汇总到一起,map输出的结果在哪,怎样传输到reduce中,我们开发人员也不需要管,我们只需要管数据汇总这一件事就可以了,处理之后的结果,只需要再写进hdfs中就可以了,别的就不需要管了.
所以我们实现一个分布式计算还是比较简单的,这里边我们关心的是我们map处理的数据来自于hdfs,处理之后又会写出到中间结果,reduce程序又会把我们的中间结果的数据拿过来进行处理.处理完成之后又会把结果写出到hdfs中,在处理的过程中是在不断的传输数据,数据传输的的方式是采用键值(key,value)对的形式.键值对也就是我们两个函数的形参,输入参数.
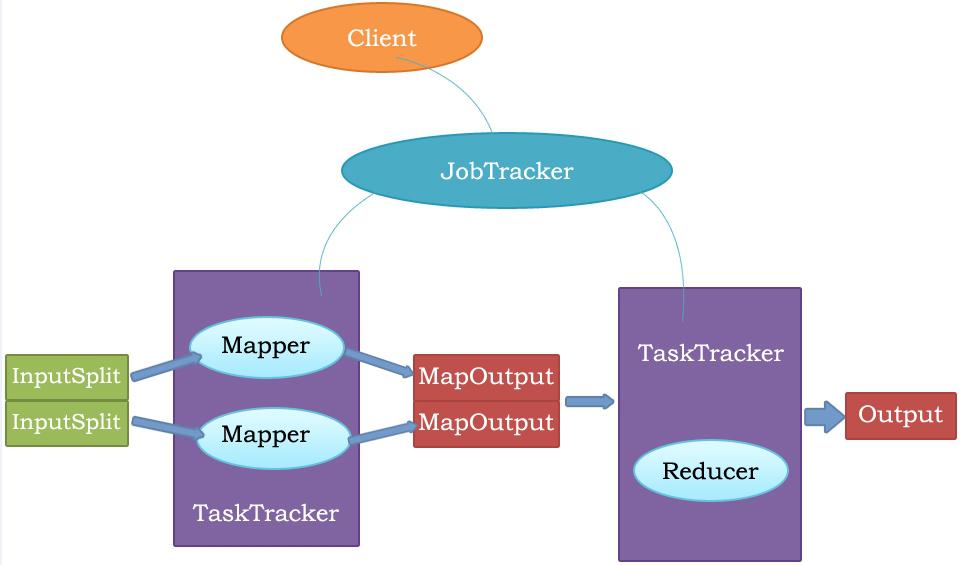
MapReduce执行流程:
Mapper任务处理的数据位于各个程序上的,处理完之后,会产生一个中间的输出,Reduce就是专门处理Mapper产生的中间输出的.reduce处理完之后,就会把结果作为一个中间结果输出出来.Map任务和Reduce任务到底在那个TaskTracker上去执行,什么样的tasktracker执行map任务,什么样的taskTracker去执行Reduce任务,这个事不需要我们去关心,是框架中的JobTracker管理的.Jobtracker它里边的这个程序来自于客户的提交.客户把我们的程序提交给Jobtracker之后,用户就不需要参与了,JobTracker就会自动把我们的程序分配到TaskTracker上去执行,有的tasktracker上跑map,有的taskTracker上跑reduce.Map程序读数据来自于hdfs,我们只需要告诉是哪个文件的路径就可以了,别的不需要我们去管.MapReduce就会把我们的程序自动的运行,把原始的数据处理完产生中间数据,然后在处理,最终就会产生一个最终的结果,用户看到的其实是最后的reduce输出结果.
map任务处理完之后产生的数据位于我们各个节点本地的,也就是我们linux磁盘,而不是位于hdfs中.会起多个reduce任务,每个reduce任务会取每个map任务对应的数据,这样reduce就会把各个map任务的需要的数据给拿到.
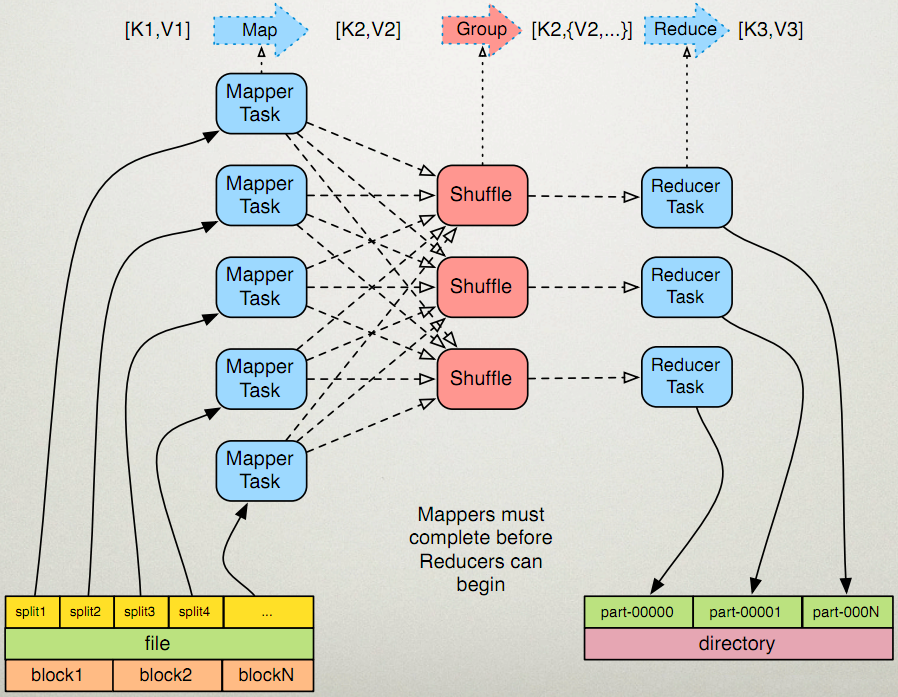
map和reduce之间数据分发的过程称作shuffle过程,shuffle在细节中:map数据产生之后需要进行分区,每个reduce处理的数据就是不同map分区下的数据.reduce就会把所有map分区中的数据处理完之后写出到磁盘中.
按官方的源码步骤讲会把shuffle归结为reduce阶段,map到reduce数据分发的过程叫做shuffle.
shuffle是把我们map中的数据分发到reduce中去的一个过程.
reduce执行完之后就直接结束了,直接写出去.不会经过Jobtracker,但是会通知Jobtracker运行结束.
有几个reduce就有几个shuffle分发的过程.
map它只做本机的处理,处理完之后,是由reduce做汇总的.会读取所有map中相同分区中的数据,所以shuffle可以认为是reduce的一部分,因为map执行完之后就已经结束了.
汇总节点是主动去其他节点要数据.reduce这个节点其实是知道各个map的,一些map执行完之后,会把数据写到本地linux磁盘,那么我们的reduce就会通过http的协议把map端处理后的数据要过来.
JobTracker是管理者,TaskTracker是干活的,TaskTracker分map任务和reduce任务,那么map任务运行完成之后,会告诉JobTracker我写完了,JobTracker一看map写完之后,就会在一个TaskTracker起一个Reduce任务,把他们这些执行完毕之后的map任务的地址告诉reduce,reduce就会通过http协议去map那读取数据.理解这些东西需要有JobTracker做管理,只要是出现他们之间做协调的时候,全部都是JobTracker做协调,管理的.哪个机器承担reduce任务也是JobTracaker在接到任务之后分配好了的.因为TasktTracker只是工作者,本身没有思考能力的,只有JobTracker有思考能力.
JobTracker分配的原理:在存储数据的节点上起map任务,jobTracker怎么会知道哪些节点存放数据呢 这个需要问namenode,namenode会知道哪些Datanode会存放数据.
要处理的文件被划分为多少个block就会有多少个map.JobTracker 没有存储任何东西,只是一个管理角色.
map在输出的时候会确定分成多少个区对应的就会有多少个reduce任务,数据分发的时候就会由shuffle的这个过程进行分发.所以说按道理来讲的话,reduce分区的数量应该有map分区的数量来决定的.
map的个数由inputSplit的个数决定的.因为inputSplit的大小默认和block的大小一样的.
hadoop的一个特点就是高容错性,JobTracker会监控各个节点的map任务和reduce任务的执行情况,如果有一个map任务宕了,会启用一个重启机制,会再重启一个mapper任务去执行.如果连续宕个三次左右,就不会重启了.那么这个程序的整个运行就失败了.会有一定的容错性在里边的,这个容错性是由JobTracker来进行控制的.
map处理其他节点的block,我们用户是没法控制的.
有datanode的节点 杀死Tasktracker,我们的程序在运行的时候只能使用其他节点的block了.我们的处理的原始数据,不允许被很多的map任务处理,只允许被一个处理,我们的数据是分配到多个dataNode上的,那么这一个map势必要读取其他节点的block.
MapReduce的执行过程:
1.map任务处理:
1.1 读取hdfs文件为内容,把内容中的每一行解析成一个个的键(key)值(value)对.文件总是有行的,键是字节的偏移量,值是每一行的内容,每一个键值对调用一次map函数.map函数处理输入的每一行.
1.2 自定义map函数,写自己的逻辑,对输入的key,value(把每一行解析出的key,value)处理,转换成新的key,value输出.
1.3 对输出的key,value进行分区.根据业务要求,把map输出的数据分成多个区..
1.4 对不同分区上的数据,按照key进行排序,分组.相同key的value放到一个集合中.
1.5 把分组后的数据进行归约.
2.reduce任务处理:
shuffle:把我们map中的数据分发到reduce中去的一个过程,分组还是在map这边的.
2.1 每个reduce会接收各个map中相同分区中的数据.对多个map任务的输出,按照不同的分区通过网络copy到不同reduce节点.shuffle实际指的就是这个过程.
2.2 对多个map任务的输出进行合并,排序.写reduce函数自己的逻辑,对输入的key,value处理,转换成新的key,value输出.
2.3 把reduce的输出保存到新的文件中.
TaskTracker节点上如果跑的是map任务,我们的map任务执行完之后,就会告诉我们的JobTracker执行完毕,把这个数据让我们的reduce来读取.读取的时机是一个map执行完毕之后让reduce去处理获取数据.
JobTracker只做管理和通知,数据只在map和reduce之间流动,准确的说,只会在TaskTracker之间流动.
排序是框架内置的.默认就有.分组不是减少网络开销,分组不是合并,只是把相同的key的value放到一起,并不会减少数据.
分组是给了同一个map中相同key的value见面的机会.作用是为了在reduce中进行处理.
map函数仅能处理一行,两行中出现的这个单词是无法在一个map中处理的.map不能处理位于多行中的相同的单词.分组是为了两行中的相同的key的value合并到一起.
在自定义MyMapper类内部定义HashMap处理的是一个block,在map方法内部定义处理的是一行.
在hadoop全局中不会有线程问题,因为hadoop起的是进程,不会有并发问题存在.
为什么hadoop不使用线程?
线程实际指的是在集中式开发下,通过线程,可以让我们的并发量,处理的吞吐量上升,线程会带来一个数据竞争的问题.hadoop中MapReduce是通过分布式多进程来实现高吞吐量,在里边不会通过线程来解决问题,因为它里边已经有很多的服务器,很多的线程了,没有必要使用线程.