NLP
一. 词向量
表示词的向量,可认为是词的特征向量或表征
词嵌入,把词映射为实数域向量
离散表示:
One-hot表示
词袋模型:通过先构建一个包含语料库中所有词的词典,然后根据词典完成对每个词的向量化,进而完成文本向量化。
问题:维度灾难;未保留次序;语义鸿沟(通过向量无法表示两个词是否为同义词)
TF-IDF:一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)

TF_IDF=TF*IDF :可以看出,当w在文档中出现的次数增大时,而TF-IDF的值是减小的
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。
统计模型:一个句子是由多个词语按顺序组合构成。统计语言模型就是计算这个组合出现的概率。

N-gram模型:为了保持词的顺序,做了一个滑窗的操作,这里的n表示的就是滑窗的大小,例如2-gram模型,也就是把2个词当做一组来处理,然后向后移动一个词的长度,再次组成另一组词,把这些生成一个字典,按照词袋模型的方式进行编码得到结果。改模型考虑了词的顺序。
n-gram模型假设一个词的出现只与它前面的固定数目的词有关系,相当于做了一个n-1阶的Markov的假设,认为一个词的出现只与它前面n-1个词相关,即
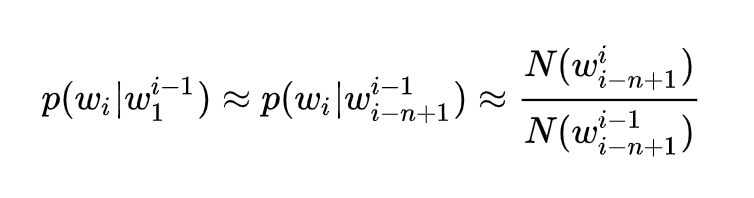
缺点:
对于一般的NLP问题,是可以使用离散表示文本信息来解决问题的,但对于要求精度较高的场景就不适合了。
- 无法衡量词向量之间的关系。
- 词表的维度随着语料库的增长而膨胀。
- n-gram词序列随语料库增长呈指数型膨胀,更加快。
- 离散数据来表示文本会带来数据稀疏问题,导致丢失了信息,与我们生活中理解的信息是不一样的。
分布式表示
用一个词附近的其它词来表示该词,一个词是由这个词的周边词汇一起来构成精确的语义信息
共现矩阵:词共同出现,词文档的共现矩阵主要用于发现主题(topic),用于主题模型,如LSA
局域窗中的word-word共现矩阵可以挖掘语法和语义信息,例如:
- I like deep learning.
- I like NLP.
- I enjoy flying
有以上三句话,设置滑窗为2,可以得到一个词典:{"I like","like deep","deep learning","like NLP","I enjoy","enjoy flying","I like"}。
我们可以得到一个共现矩阵(对称矩阵):
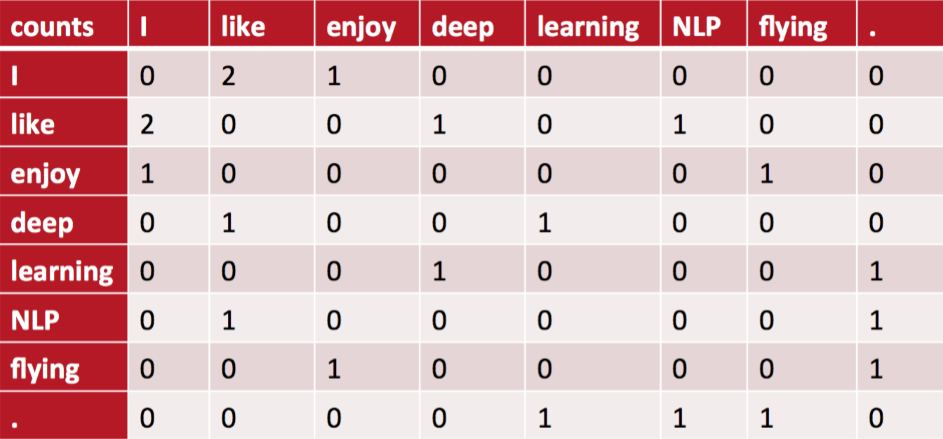
中间的每个格子表示行和列组成的词组在词典中共同出现的次数,也就体现了共现的特性。
缺点:
- 向量维数随着词典大小线性增长。
- 存储整个词典的空间消耗非常大。
- 一些模型如文本分类模型会面临稀疏性问题。
- 模型会欠稳定,每新增一份语料进来,稳定性就会变化。
神经网络表示
NLNLM:定义一个前向窗口大小,其实和上面提到的窗口是一个意思。把这个窗口中最后一个词当做y,把之前的词当做输入x,通俗来说就是预测这个窗口中最后一个词出现概率的模型
(和n-gram模型功能一样,输入是词序列,输出是概率)

Word2Vec:实际是一种浅层的神经网络模型,它有两种网络结构,**分别是CBOW(Continues Bag of Words)连续词袋和Skip-gram;
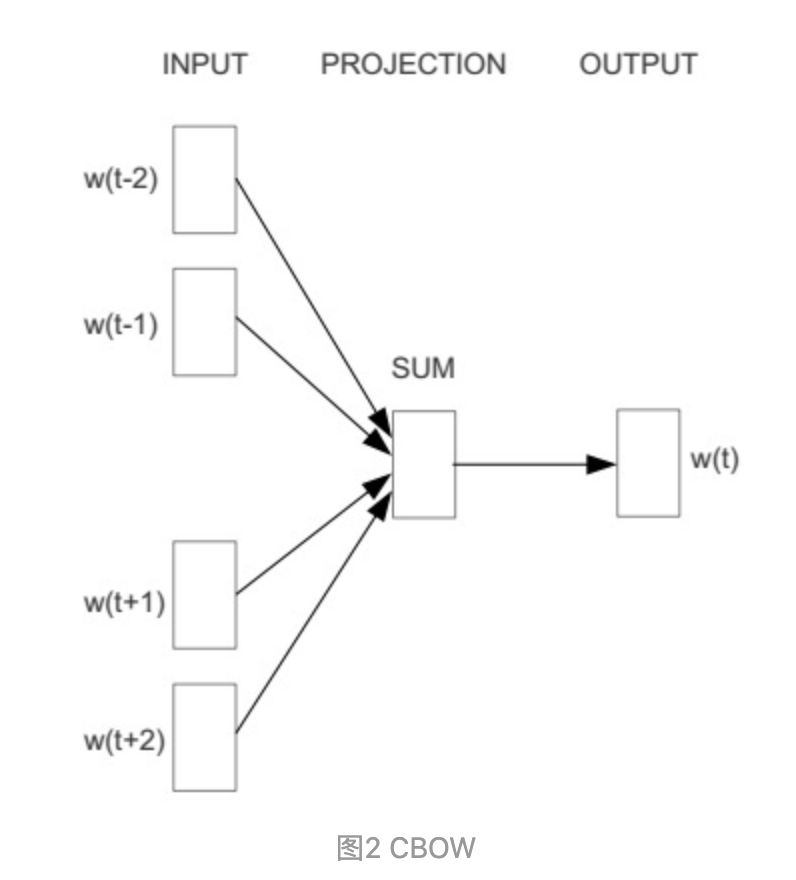
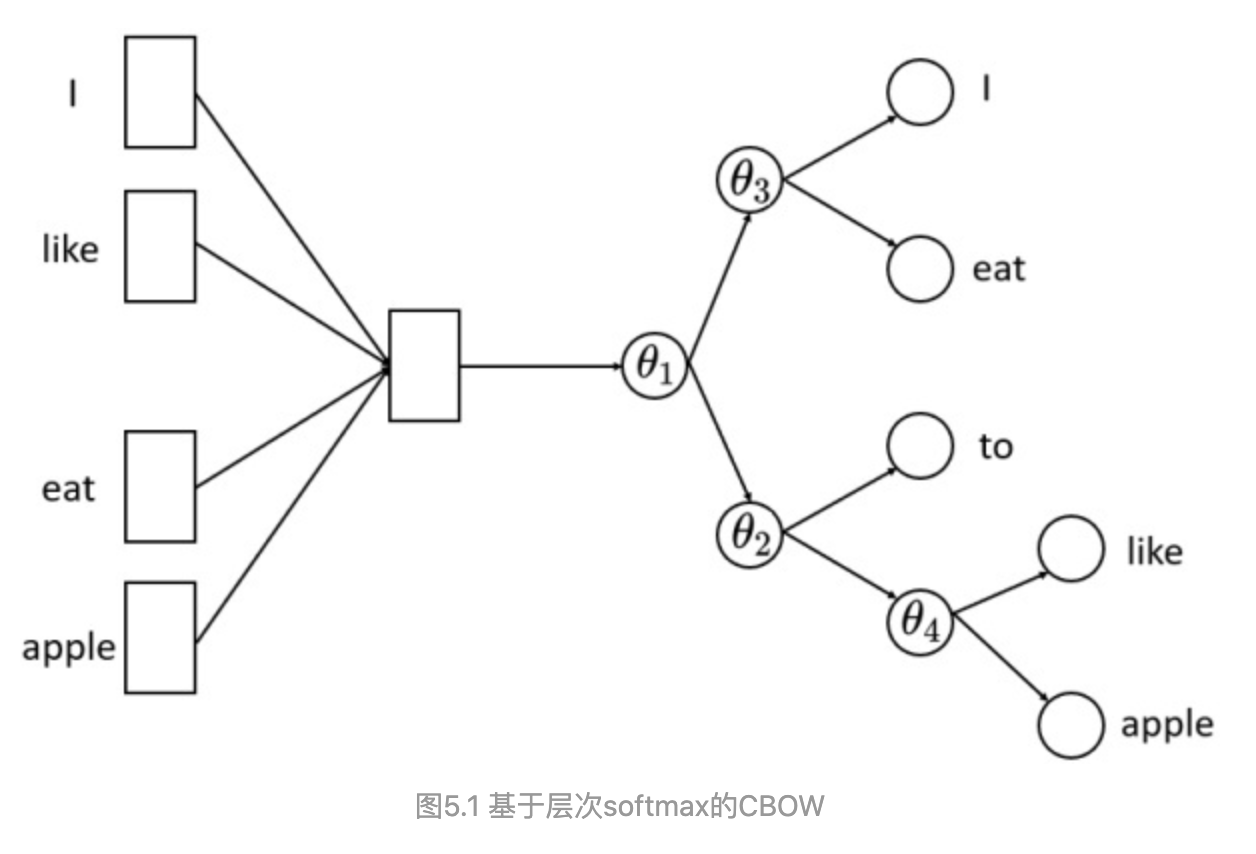
CBOW:获得中间词两边的的上下文,然后用周围的词去预测中间的词,把中间词当做y,把窗口中的其它词当做x输入,x输入是经过one-hot编码过的,然后通过一个隐层进行求和操作,最后通过激活函数softmax,可以计算出每个单词的生成概率
(图中目标词 Wt 前后只取了各两个词,所以窗口的总大小是2)
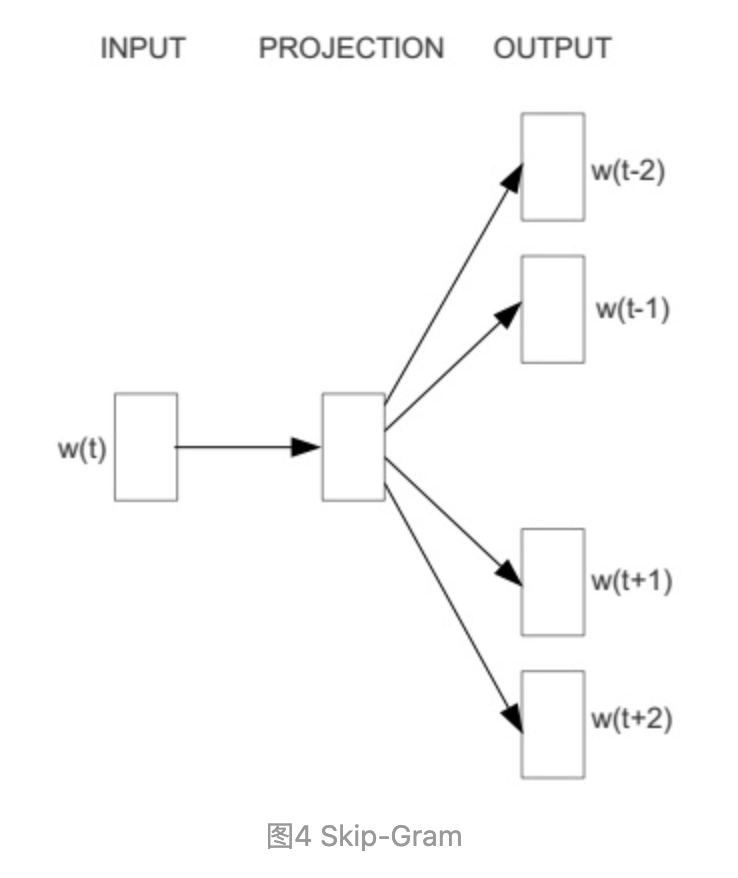
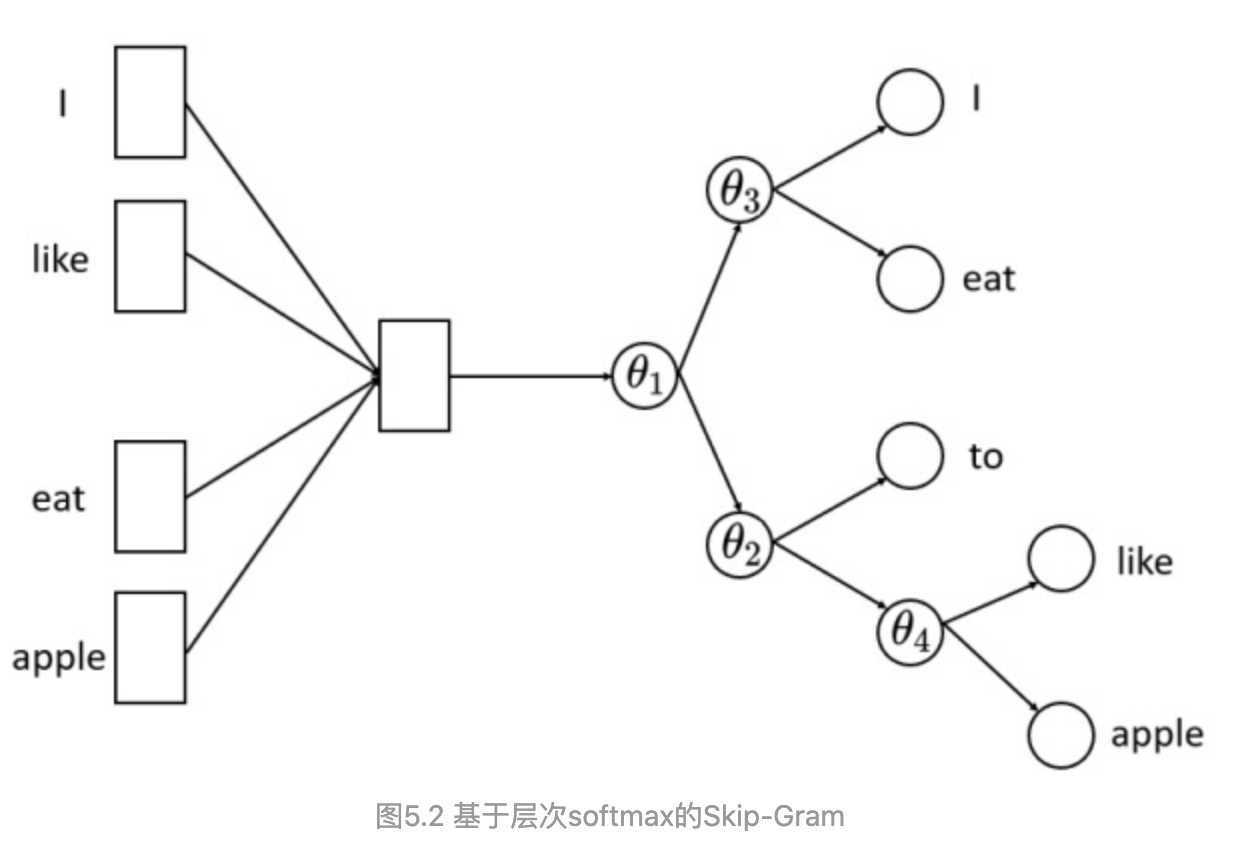
Skip-gram:与CBOW相反,通过当前词来预测窗口中上下文词出现的概率模型,把当前词当做x,把窗口中其它词当做y,依然是通过一个隐层接一个Softmax激活函数来预测其它词的概率
(图中目标词 Wt 前后只取了各两个词,所以窗口的总大小是2)
ULMFIT:通用语言模型的微调,搞定一项NLP任务,不再需要从0开始训练模型,拿来ULMFiT,用少量数据微调一下,它就可以在新任务上实现更好的性能
ELMo:用语言模型(language model)来获取词嵌入,同时也把词语所处句、段的语境考虑进来。
BERT:Bidirectional Encoder Representations from Transformers,意思是来自Transformer的双向编码器表示,也是一种预训练语言表示的方法
Auto Keras:执行AutoML任务的开源库
层次softmax和负采样替换输出层softmax,降低复杂度
参考链接:https://zhuanlan.zhihu.com/p/44599645
层次softmax(Hierarchical Softmax):

基于层级sotfmax的CBOW:

负采样(Negative Sampling):随机采样代替softmax
负采样实际上是采样负例来帮助训练的手段,其目的与层次softmax一样,是用来提升模型的训练速度。我们知道,模型对正例的预测概率是越大越好,模型对负例的预测概率是越小越好。由于正例的数量少,很容易保证每个正例的预测概率尽可能大,而负例的数量特别多,所以负采样的思路就是根据某种负采样的策略随机挑选一些负例,然后保证挑选的这部分负例的预测概率尽可能小。所以,负采样策略是对模型的效果影响很大,word2vec常用的负采样策略有均匀负采样、按词频率采样等等。