我们用 HTTP 协议做脚本,要注意的是,不同协议的函数是不一样的,假如换 websocket 协议,关联函数就要用其他的
参数化
原理
1、什么叫参数化
把脚本内一个写死的值,去一个数组内取值,进行替换
2、为什么要参数化
烂大街的回答:模拟真实场景,模拟真实情况
真实原因:
应用程序/数据库对数据有唯一性要求(应用程序内就是单点登录;数据库内就是该字段为 Unique ,唯一)
避免查询缓存对结果造成失真(重复查询同一条数据,如果该数据的表内开启了查询缓存,则会命中。那么响应时间会比市价值偏小)
3、可不可以不用参数化
查询缓存的开关是用query_cache_size = 20M和query_cache_type = ON 打开查询缓存,程序校验就得修改代码了,数据库唯一要求,把 Unique 的限制给拿掉就ok
如何参数化(参数化会变紫)
1、选中需要参数化的内容,右键,选择"Replace with a Parameter",
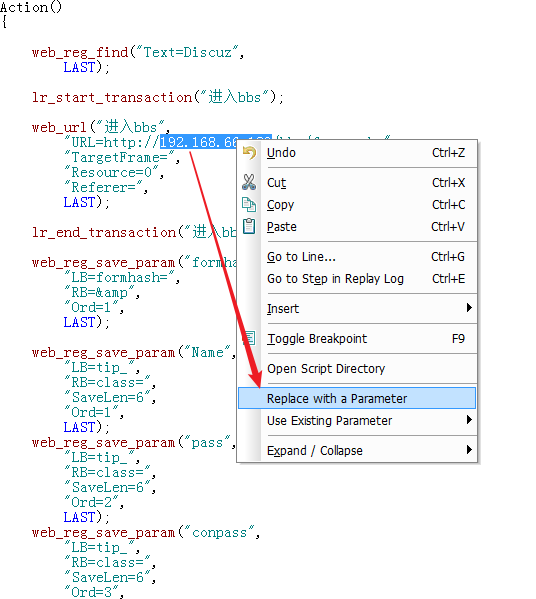
2、为参数命名,并且制定参数取值的文件格式
Parameter name,就是我么那要设定的参数名,这个是不能重复的
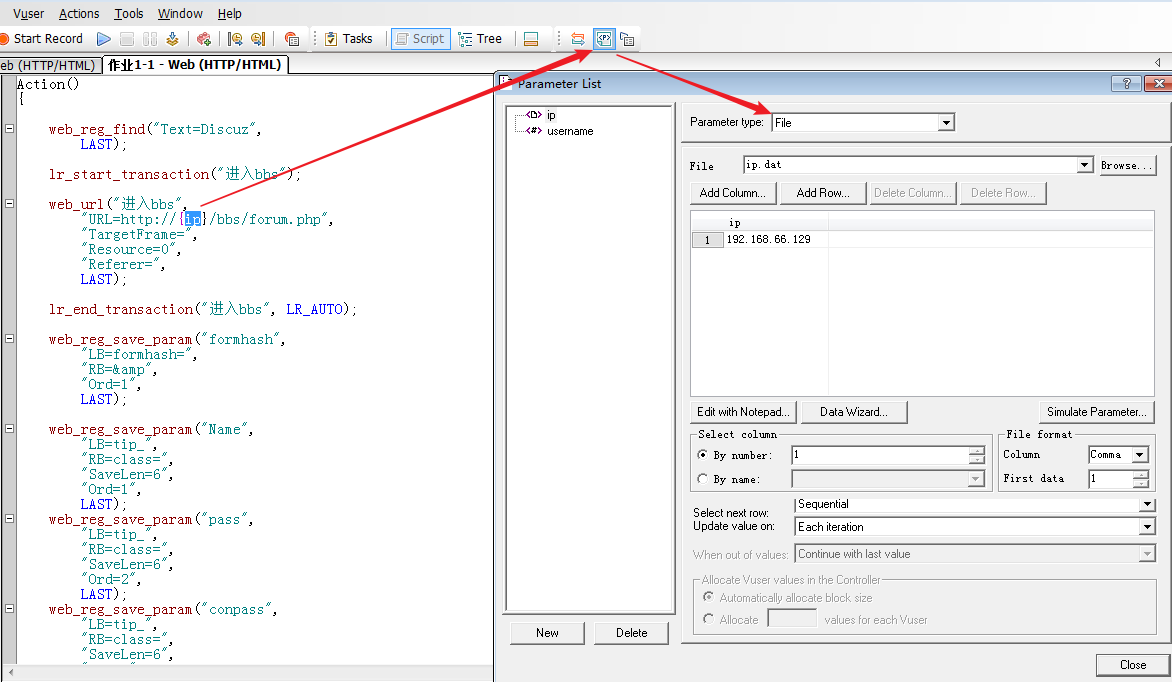
Parameter type 是参数取值的方式,这个 file 是从 .bat 文件中取值,这个文件会自动生成在项目路径下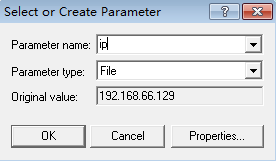
结果:
例如:
web_submit_data("提交", "Action=http://192.168.66.129/bbs/member.php?mod=register&inajax=1", "Method=POST", "TargetFrame=", "Referer=http://192.168.66.129/bbs/member.php?mod=register", ITEMDATA, "Name=regsubmit", "Value=yes", ENDITEM, "Name=formhash", "Value={formhash}", ENDITEM, "Name=referer", "Value=http://192.168.66.129/bbs/forum.php", ENDITEM, "Name=activationauth", "Value=", ENDITEM, "Name={Name}", "Value=hua00{username}", ENDITEM, "Name={pass}", "Value=123456", ENDITEM, "Name={conpass}", "Value=123456", ENDITEM, "Name={mail}", "Value=hua00{username}@qq.com", ENDITEM, LAST);
另一种情况,我们要把另一个数值也运用之前同一个参数咋办?

另外,我们的参数化还有种方式:可以先建好,然后再脚本内用,这种情况适用于只给了脚本,但是没有给参数化文件的情况

打开变量列表,填写变量值

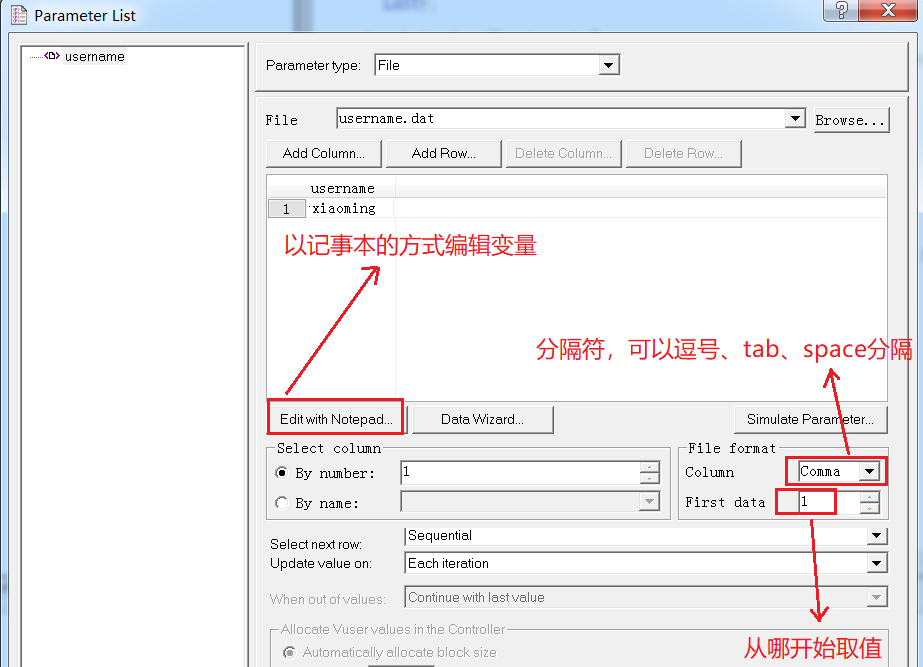
参数化变量和值是怎样对应的
根据脚本中的参数名({username})去找参数列表中的的参数username,再去找参数列表中的username对应的bat文件
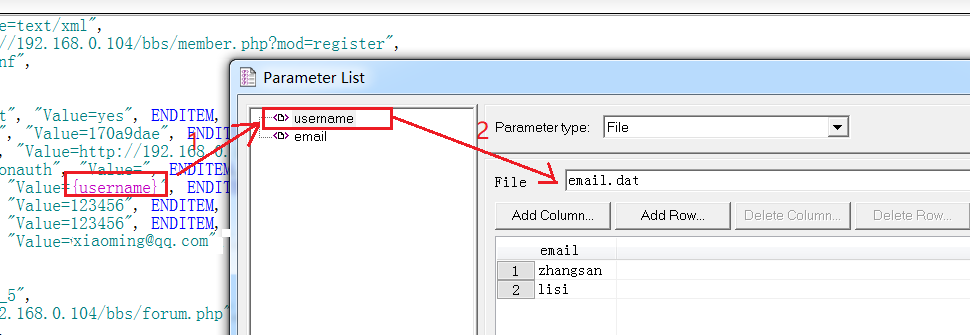
注意,我们 loadrunner 的参数化默认是以 {} 为边界的,我们也可以修改这个参数化的边界类型:
在 Tools-->General Options-->Parameterization的Paramrter Braces 内可以设置,我们可以看到默认是 {}

参数化策略
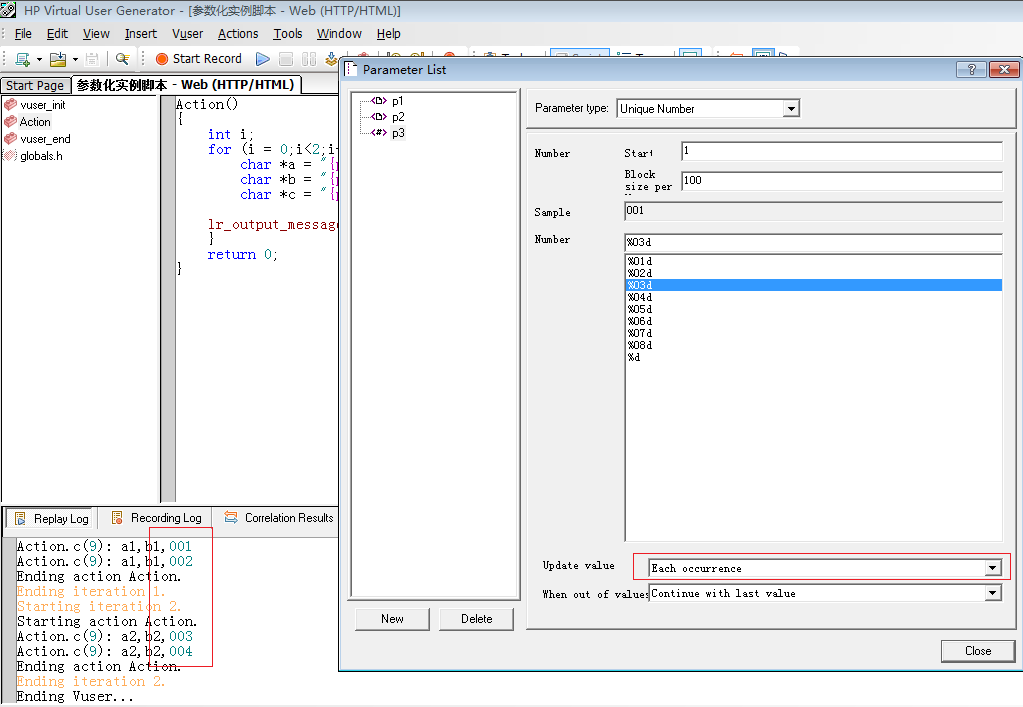
最常用的取值方式:唯一(Unique+XX)
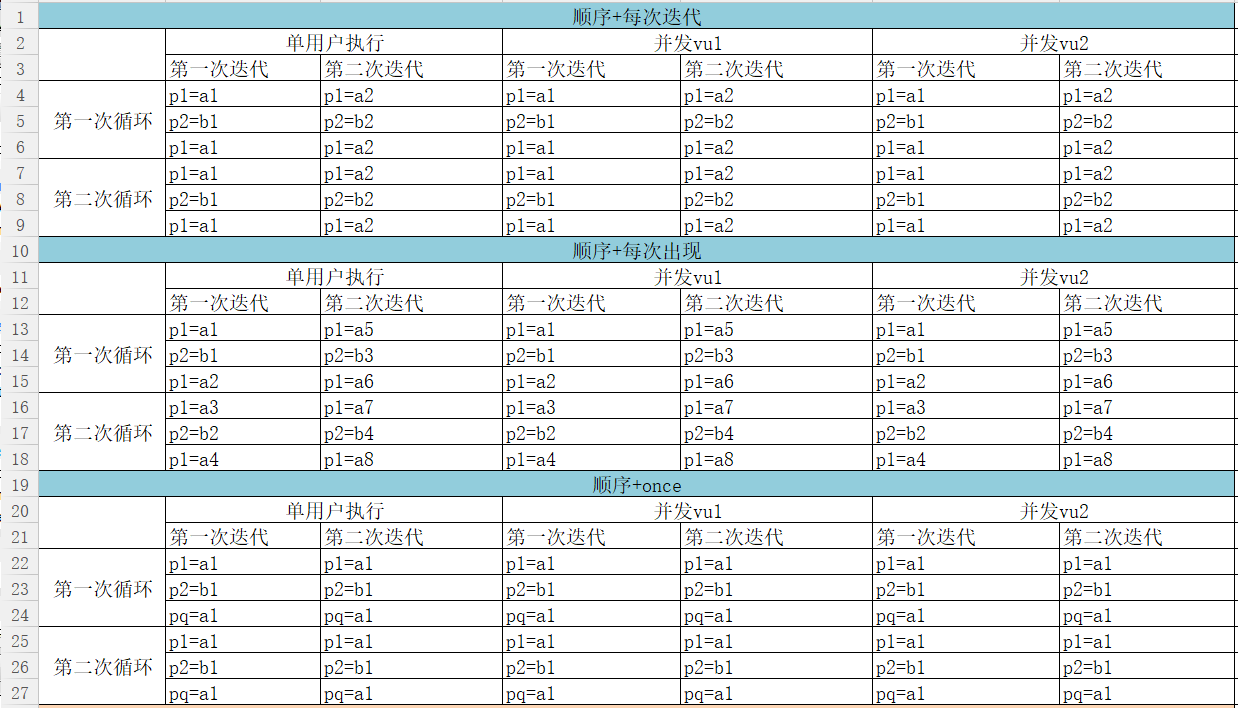
我们写一个脚本来执行不同的参数化策略:
Action() { int i; //申明变量 for (i = 0;i<2;i++) { //循环 char *a = "{p1}"; //获取参数值传给 a char *b = "{p2}"; //获取参数值传给 b char *c = "{p1}"; //获取参数值传给 c lr_output_message("%s, %s, %s",lr_eval_string(a),lr_eval_string(b),lr_eval_string(c));
//分贝演示 9 种不同的参数化策略组合结果 } return 0; }
如下Loadrunner参数化取值策略由[select next row]、[update value on]两部分组成。各取值情况如下:
● Select next row(除去same as):顺序、随机、唯一
● Update value on:每次迭代、每次出现、唯一
Select next row 代表下一行要变更时,下一行取哪个值

Update value on 代表触发值变更的条件
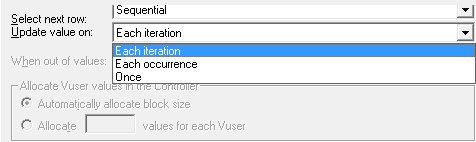
取值策略简单理解就是:当触发值的变更值条件时,下一个取值怎么取,除去same as 这种取值,根据排列组合共有9种取值情况。
另外,我们可以测试单个参数的取值
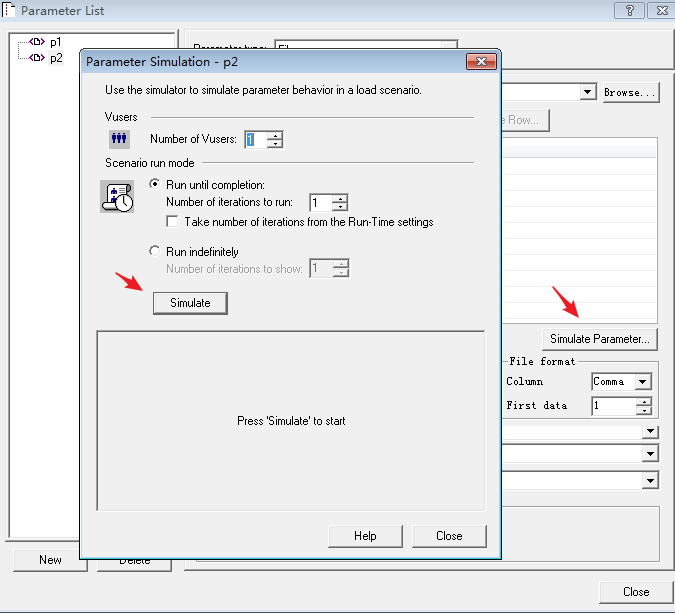
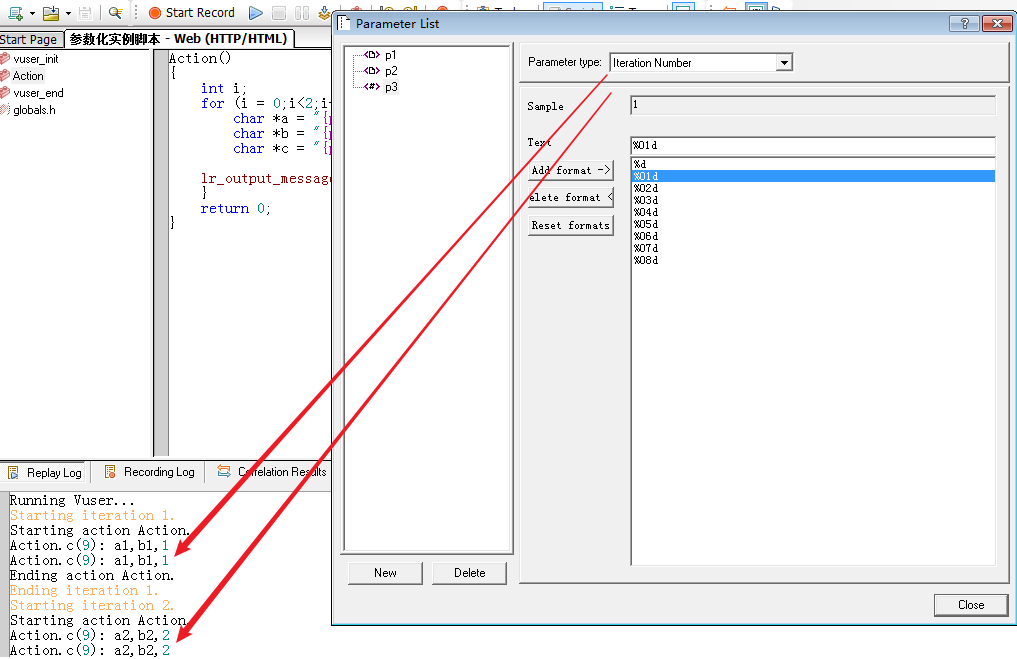
如我们刚刚的脚本所示,我们来理解下,这几种策略的美妙之处:简单地,我们 p1 取 a1~a10,p2 取 b1~b10
取值结果如下图:
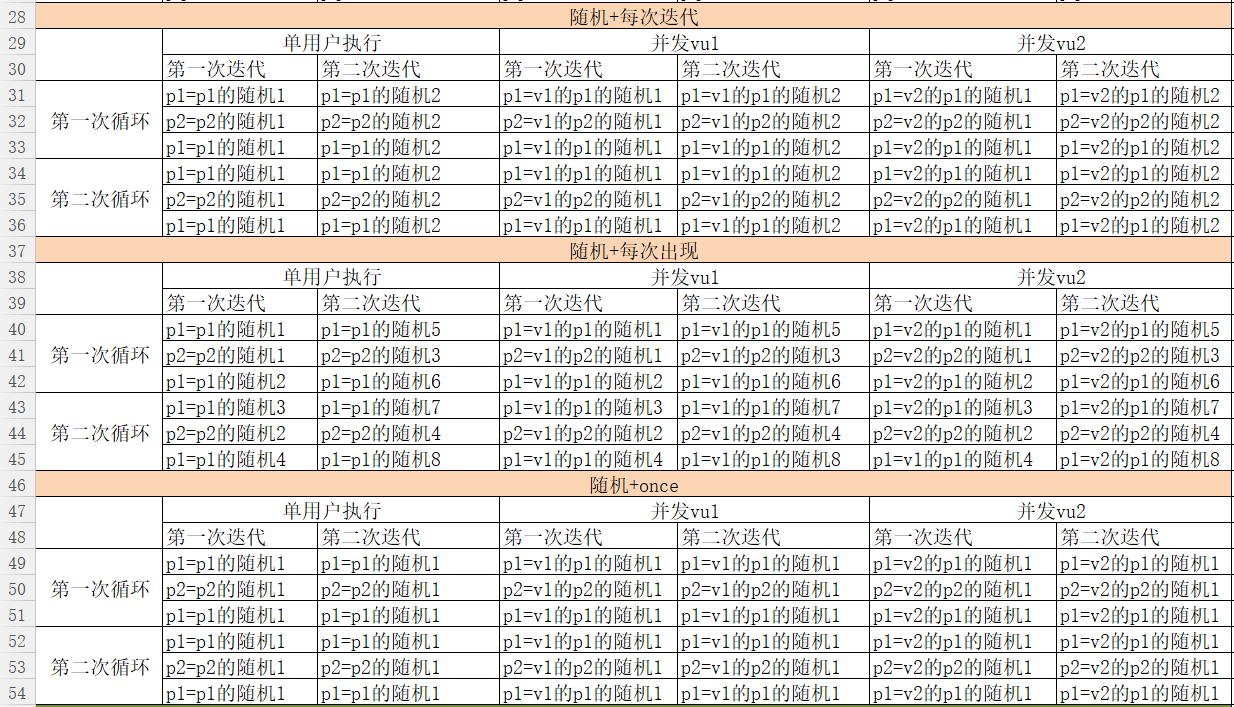

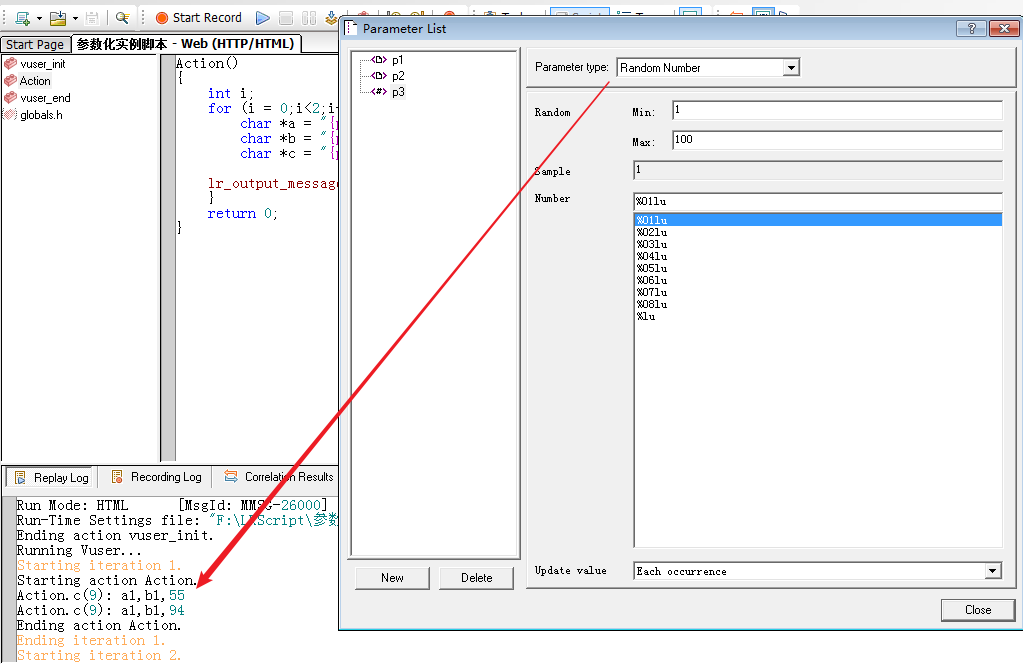
其他格式
这个其实也是每次的值都不一样,值唯一,1~100,是 3 位的
随机数
迭代内相同的值
日期(可选格式)

等等……
特别说明
当update value on值为[unique]时,可设置[when out of values]、[Allocate Vuser values in Cotroller]值
when out of values:当值用完怎么办?
Abort Vuers 退出
Continue in a cyclic manner 从头开始取
Continue with last value 一直用最后一个数
Allocate Vuser values in Cotroller,就是给每个 vu 分配的值个数
注意:
● 唯一+每次出现:不能自动分配(loadrunner不会读脚本,不知道脚本中的循环),只能手动分配
● 手动分配时要注意:计算每个用户分配多少个值、参数化文件中要录足够的值
计算手动分配时,为每个用户分配多少个值:
例1:银行流水号参数化,10个并发,跑10分钟,1个用户跑TPS=10,假如服务器的tps无限大
解:10个并发每秒跑的请求量:1*10*10=100
10个并发跑10分钟请求量:100*10*60=60000
10钟每个用户跑的请求数:60000/10=6000
则理想情况下为每个用户分配6000个值,考虑到实际可为每个用户分配6200个值。
例2银行流水号参数化,10个并发,跑10分钟,1个用户跑TPS=10,假如服务器的tps为50
解:10个并发每秒跑的请求量:1*10*10=100>服务器TPS。服务器处理不过来
以服务器最大TPS来处理
10个并发跑10分钟请求量:50*10*60=30000
10钟每个用户跑的请求数:30000/10=3000
则为每个用户分配3000+个值即可
连接数据库取值
1、选择好参数,点击 Data Wizard,如出现提示,点击 ok
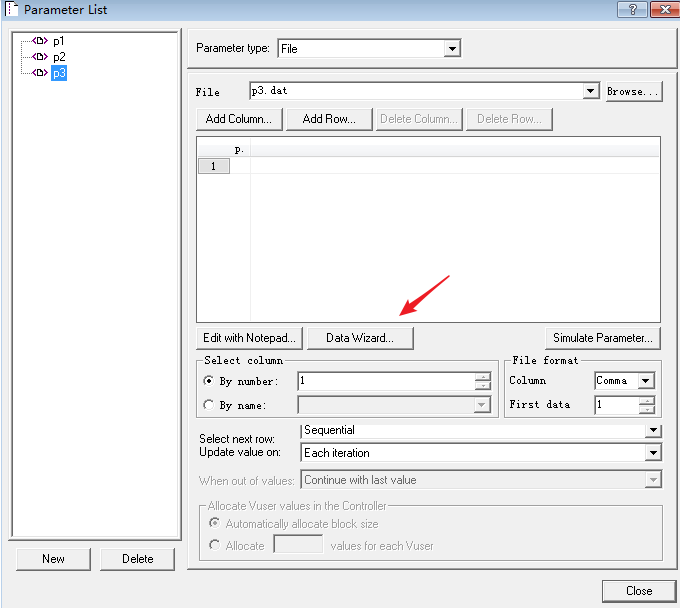
2、选择到系统数据源

3、如果要连接 Mysql 还要安装驱动:https://dev.mysql.com/downloads/connector/odbc/
安装过程中如果遇到类似于ANSI问题,要将Windows>>system32>>msvcr100_clr0400.dll复制,改名为msvcr100.dll
安装即可成功。进入到 C:WindowsSystem32 找到刚才安装的驱动。双击进入
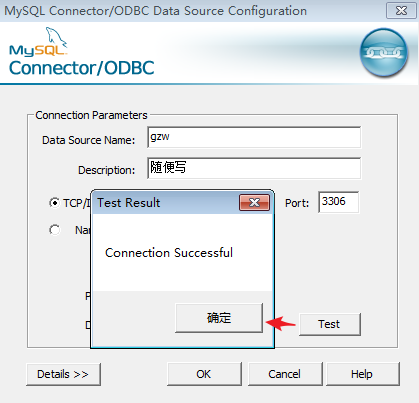
然后在 loadrunner 内可以看到该连接

前面俩都可以瞎写,后面填写数据库的连接信息,可以 test 一下,说明正常连接上了数据库
之后就简单了:
输入连接池的名称,以及 sql 语句
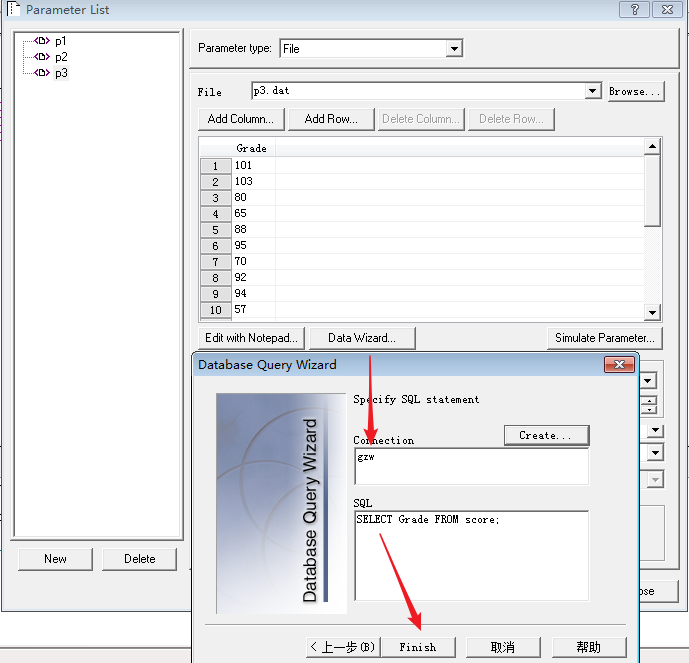
结果:取到了数据库的这些值
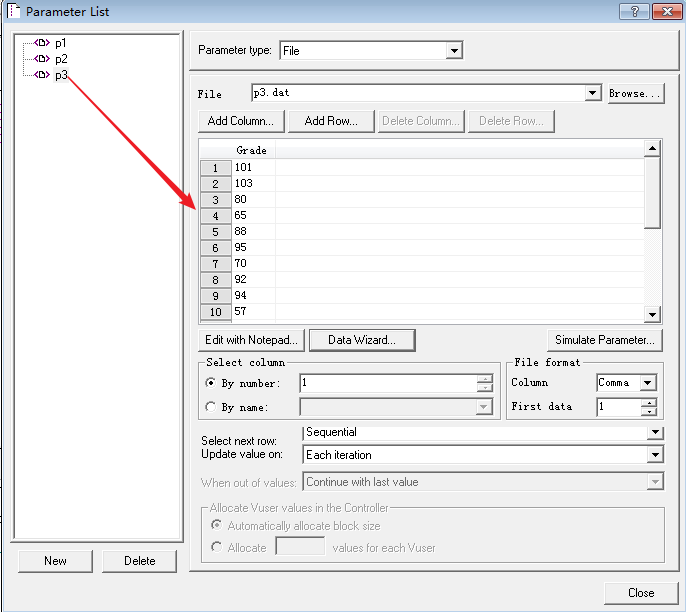
此方式比较麻烦,只适合装 X 使用
关联
1. 定义
关联就是将服务器返回的动态的变化的一个值把它保存为一个参数,以供后面需要用到该值的请求进行使用。
2. 为什么要关联
客户端发送的请求内,有某些动态值是由服务器返回并且在发送请求过程中会被服务器校验,不校验的值可以不用关联,比如一些时间戳
3. 哪些值需要关联
3.1经验判断
- 自己输入的值肯定不需要关联
- 常见的(1,0) (on,off) (yes,no) 空值 都不需要关联
- 90%以上都只会关联value,但有极少数情况下会出现关联key(key看起来不正经)
- 非自己输入的脚本里出现的参数是可能需要关联的
3.2根据关联类型判断
1)服务器校验提交请求的合法性(值的合法性、key的合法性)、正确性
- 验证码要校正确性,常见验证码包括:图片验证码、邮箱验证码、手机验证码
- 时间戳、token(手机)、session(http)要校验合法性
题外话:
- 图片验证码怎么处理:万能验证码、验证码失效、找开发要验证码的实现逻辑(做正则)
- 现在图片识别技术不成熟,有错误率
- token校验比session校验更安全,token更复杂
2)数据库类(值是int的数字,key是id类)
- 插入操作的关联就是把insert这个表的必填字段补全,这个必填字段是跟其他数据的关联关系的字段一般是id,不要让你的数据是垃圾(无根之源的数据)
语法:
insert into 表(字段,字段...) values (值,值...)
举例说明:
例1:insert into 户籍表("id","name","sex","bir","adr","fuid","muid")
------fuid,muid:来源于父母的户籍信息
------猜想:fuid,muid需要关联
例2:insert into 帖子表("自增id","msg","title","time","模块id","谁发的帖")
------猜想谁发的帖要关联,模块id看是否要求,time待定
● delete操作的关联就是补全where后面的条件值并且值是对的,这些条件值可能是一个也可能是多个
语法:
delete from 表 where xx = ??? and xx >= ???
------and/or
------>= ,<=, != ,in ,not in ,between
● update操作的关联就是补全where后面的条件值并且值是对的,这些条件值可能是一个也可能是多个
语法:
update 表 set xx=xxx where xx = ??? and xx >= ???
------and/or
------>= ,<=, != ,in ,not in ,between
● select操作的关联就是补全where后面的条件值并且值是对的,这些条件值可能是一个也可能是多个
语法:
select xx,xx from 表 where xx = ??? and xx >= ???
------and/or
------>= ,<=, != ,in ,not in ,between
题外话:
● 数据库简单定义
DDL:数据库模式定义语言,关键字:create
DML:数据操纵语言,关键字:Insert、delete、update
DCL:数据库控制语言 ,关键字:grant、remove
DQL:数据库查询语言,关键字:select
● int类型数字检索比char类型快很多
4. 关联位置放哪
哪个请求response中返回你想要用的那个值,关联函数就放在这个请求的前面。关联位置放哪,需要从应用程序和数据库角度去考虑。关联的值肯定是在触发校验请求之前给。如:seesion是在进入登录页面时给的,token是在登录后给的。
下面以注淘宝注册购物结束精简流程来说明关联的位置,例子比较粗糙,顺带说一下参数化。
● 注册
----参数化(用户名、手机号)
----关联(手机验证码,输入手机号点下一步时给)
● 登录
----参数化(用户名或手机号)
● 查看商铺详情
----参数化or关联都行(商品id,商铺id,避免缓存造成的结果失真)
----可能会记录谁在浏览,若记录就需要关联uid(最早在注册时给,后续登录也会给)
● 收藏商品
----关联(商品id,商铺id,uid),uid同上,商铺id,店铺id由商品列表返回)
● 加入购物车
----关联(商品id,商铺id,uid),uid同上,商铺id,店铺id由商品列表返回)
● 删除购物车
----关联(商品id,商铺id,uid),uid同上,商铺id,店铺id由商品列表返回)
● 结算
----关联(uid,商品id,店铺id)、delete购物车、update库存
● 查询订单
----关联(订单id,uid),订单id结算时返回,uid同上
5. 关联函数怎么写
5.1关联的5种方法
- tree视图右键关联
- tree视图获取左右边界,手写关联
- 扩展日志获取到服务器的返回结果,取到左右边界值,手写关联
- 抓包工具获取到服务器的返回结果,取到左右边界值,手写关联
- 通过查看页面源文件,到左右边界,手写关联
5.2关联值如果出现多个不同的关联边界,如何选取边界
- 选择出现次数多的
- 选择正经的(容易区分的)
5.3 tree视图右键关联操作
1)tree视图下选中要关联的值,点击右键-->Create Paramter
2)回到script视图,自动填写好关联函数,需要注意的是右键关联填写的边界值可能不对,需自己根据情况调整
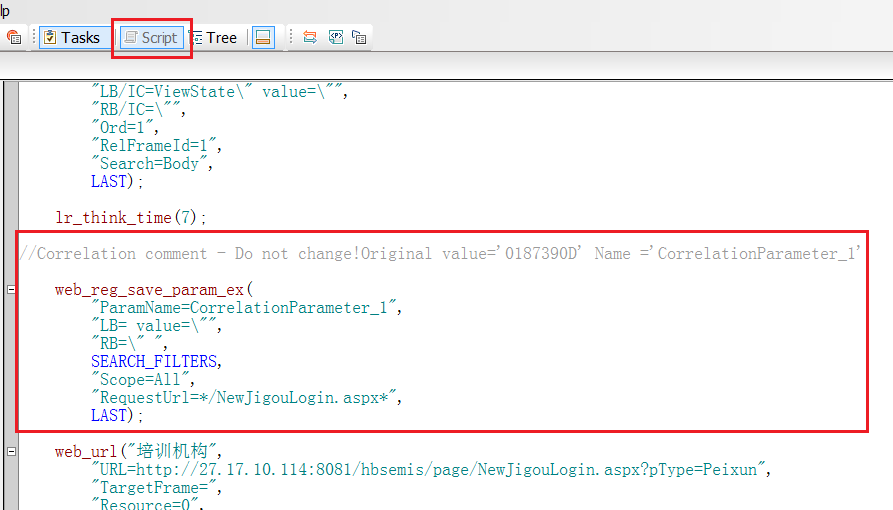
5.4手写关联
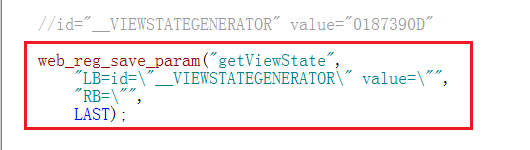
知道边界值的情况下可以自己手写关联函数,手写关联可以用web_reg_save_param或者web_reg_save_param_ex函数,当边界值不需要用到正则表达式时,推荐用web_reg_save_param即可。下面演示用web_reg_save_param手写关联。
1)点击【Insert-->New Step】
2)输入web_reg_save_param并选择,点击ok
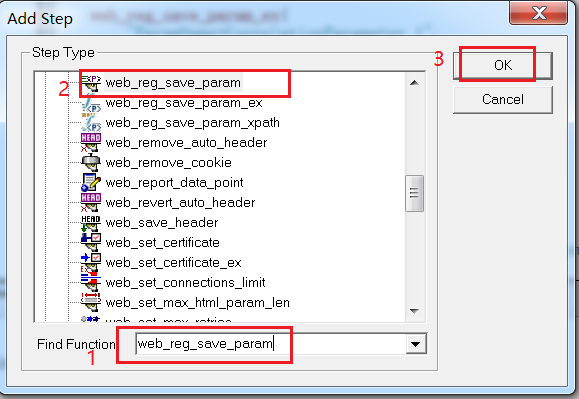
3)填写匹配规则后点击ok

● Notfound: 当在返回信息中找不到要找的内容时应该怎么处理
Notfound=error: 当在返回信息中找不到要找的内容时,发出一个错误讯息。这是缺省值。
Notfound=warning: 当在返回信息中找不到要找的内容时,只发出警告,脚本也会继续执行下去不会中断。
● LB( Left Boundary ) : 返回信息的左边界字串。该属性必须有,并且区分大小写。
● RB( Right Boundary ): 返回信息的右边界字串。该属性必须有,并且区分大小写。
● RelFrameID: 相对于URL而言,欲查找的网页的Frame。此属性质可以是All或是数字,该属性可有可无。
● Search : 返回信息的查找范围。可以是Headers,Body,Noresource,All(缺省)。该属性质可有可无。
● ORD : 说明第几次出现的左边界子串的匹配项才是需要的内容。该属性可有可无,缺省值是1。如为All,则将所有找到的内容储存起来。
● SaveOffset : 当找到匹配项后,从第几个字元开始存储到参数中。该属性不能为负数,缺省值为0。
● SaveLen :当找到匹配项后,偏移量之后的几个字元存储到参数中。缺省值是-1,表示一直到结尾的整个字串都存入参数。
4)关联函数写完