环境说明
集群中有三个节点:一个Master,两个Slave。
节点的IP地址分别为:
Master:192.168.140.132
Slave1:192.168.140.133
Slave2:192.168.140.134
可以通过ifconfig查看自己虚拟机的IP地址。
网络配置
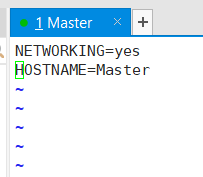
修改自己各个节点的主机名
vi /etc/sysconfig/network
修改节点的IP映射
vi /etc/hosts

重启虚拟机
sudo reboot
以上操作同时要在另外两个节点上配置
配置SSH免密登录
cd ~/.ssh
#删除之前的公钥
rm ./id_rsa*
#生成公钥,然后一直按回车
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys
#修改权限
chmod 600 authorized_keys
#验证
ssh Master

#将Master节点上公钥传输到另外两个节点上
scp ~/.ssh/id_rsa.pub stu@Slave1:/home/hadoop/
scp ~/.ssh/id_rsa.pub stu@Slave1:/home/hadoop/
#在Slave1、Slave2上将上述公钥加入授权
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
cd ~/.ssh/
chmod 600 authorized_keys
安装JDK,配置环境变量
分别在Master、Slave1、Slave2上安装JDK环境
cd /usr/local
tar -zxvf JDK-(看你虚拟机是32位的还是64位的,下载对应的安装包)
配置JAVA_HOME环境变量
vi ~/.bashrc
#在最后一行添加
export JAVA_HOME=(你JDK的安装位置)
export PATH=$JAVA_HOME/bin:$PATH:
#使环境变量配置生效
source ~/.bashrc
验证
java -version

安装配置hadoop
在Master节点上
#进入到你压缩包的位置,并解压
cd /usr/local
tar -zxvf hadoop-2.7.2.tar.gz
#将文件夹名修改位hadoop
mv hadoop-2.7.2 hadoop
#修改文件权限
chmon -R stu:stu hadoop
#修改环境变量
vi ~/.bashrc
#添加以下内容

#使配置生效
source ~/.bashrc
修改五个配置文件
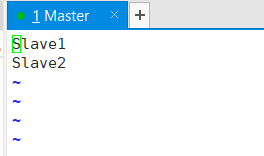
/usr/local/hadoop/etc/hadoop/slaves
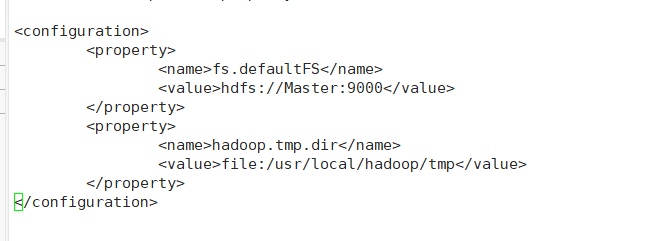
/usr/local/hadoop/etc/hadoop/core-site.xml添加
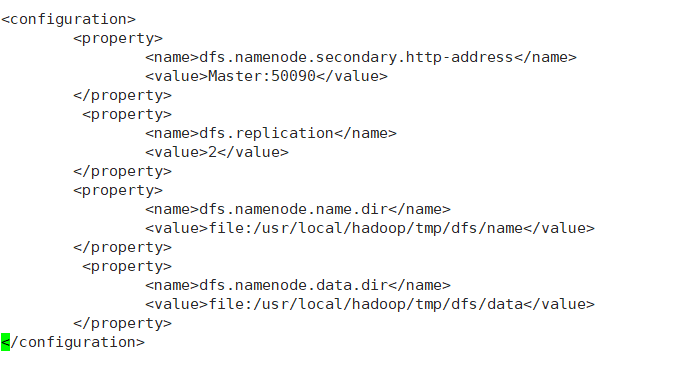
/usr/local/hadoop/etc/hadoop/hdfs-site.xml添加
/usr/local/hadoop/etc/hadoop/mapred-site.xml添加
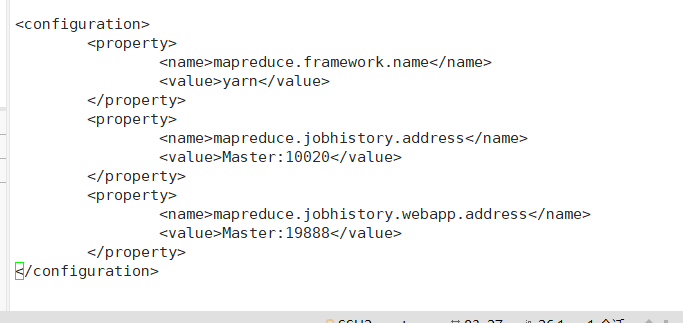
/usr/local/hadoop/etc/hadoop/yarn-site.xml添加

完成后分别将hadoop文件夹和bashrc文件发送到Slave1、Slave2节点上
sudo scp -r /usr/local/hadoop Slave1:/usr/local/
sudo scp -r /usr/local/hadoop Slave2:/usr/local/
scp /home/hadoop/.bashrc stu@Slave1:/home/hadoop/
scp /home/hadoop/.bashrc stu@Slave2:/home/hadoop/
接着进入Slave1、Slave2进行下面的操作
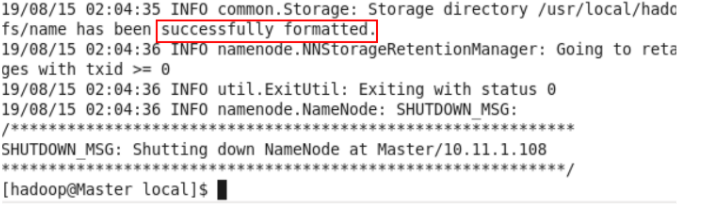
最后在Master节点上进行格式化
hdfs namenode -format
启动集群
在Master节点上start-all.sh
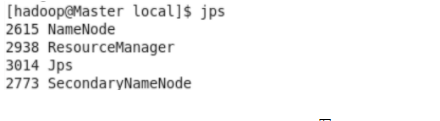
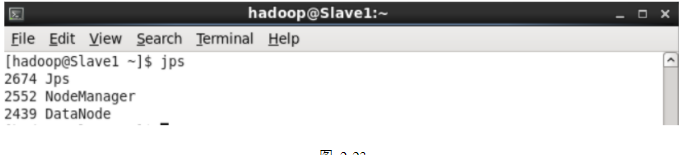
在Master、Slave1、Slave2上输入jps检查

进入Master:50070查看
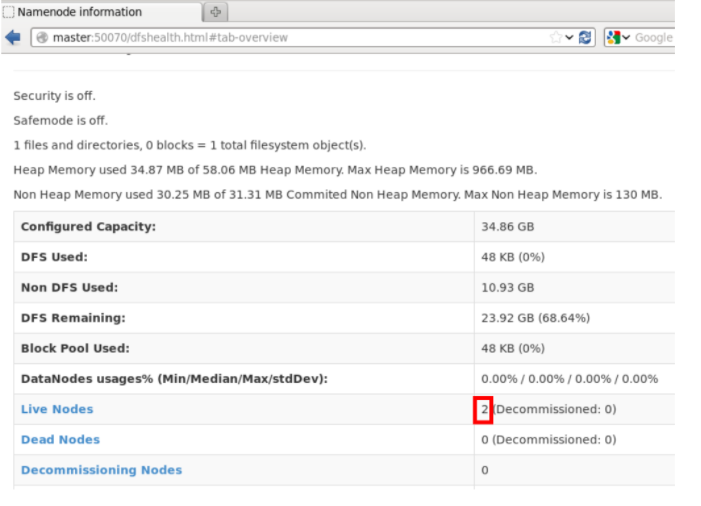
到此,hadoop完全分布式搭建成功。