一、拾遗
1、通常情况下无参函数只是进行操作,所以不需要返回值;有参数函数则需要返回值。
2、练习:
判断用户输入一串字符,如果这串字符的长度小于5则重新输入,如果大于5则退出循环。
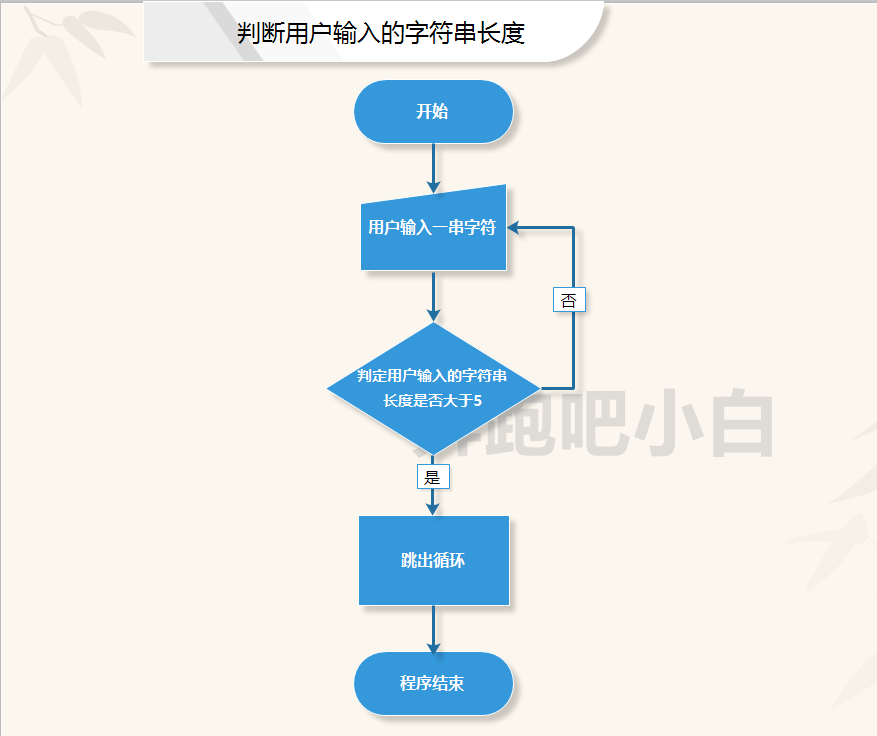
while True:
usr_input = input('Please input a string of characters:')
res = len(usr_input) # 将len()函数的返回值存储起来
if res > 5:
break
二、函数的使用原则
1、函数与变量
(1)变量与函数的相似之处
函数的定义与变量的定义是相似的
变量名与函数名都是指向一块内存地址
例:
变量:
x = 1 # x是名字,1是值,表示变量名x指向了一个变量值 1
函数:
def func # func是名字,函数体print('ok')则是值,表示定义了一个名字叫func的函数,函数名则指向了函数体print('ok')。
print('ok')
变量和函数都是必须先定义后使用。
变量如果未定义就引用则相当于引用一个不存在的变量名,会提示变量名未定义
函数如果未事先定义函数而直接引用函数就相当于引用一个不存在的变量。会提示函数名未定义
(2)函数与变量的不同之处
变量名不需要加括号就能调用。
函数的调用必须要加上括号才能运行,因为函数里封装了值,实际上是一段一段的代码。所以要加上括号才能执行。
2、函数的常见错误
例1:函数事先未定义
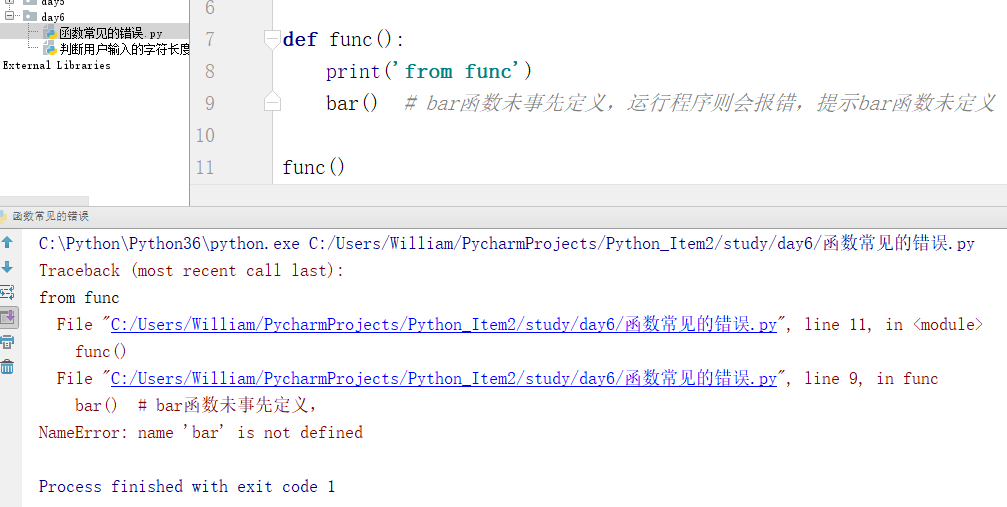
解决方法:
在func()函数上面定义一个bar函数:
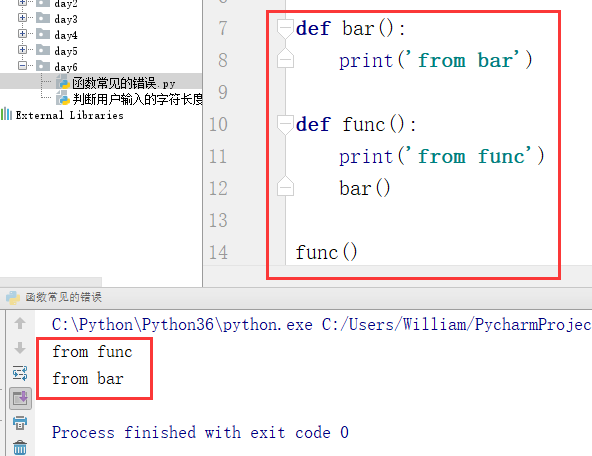
例2:以下函数执行时,很多人认为会报错。其实并不会报错。
def func():
print('from func')
bar()
def bar():
print('from bar')
func()
原因:
一定要熟练掌握函数的特性:先定义后调用!
func函数在定义时,函数体中的bar()并未执行,并且当调用func函数时也不会报错,是因为在定义 bar函数时,函数名bar已经存在内存中了,所以,此时对func函数体中的bar调用,则会找到bar函数,并且调用bar函数里的函数体。
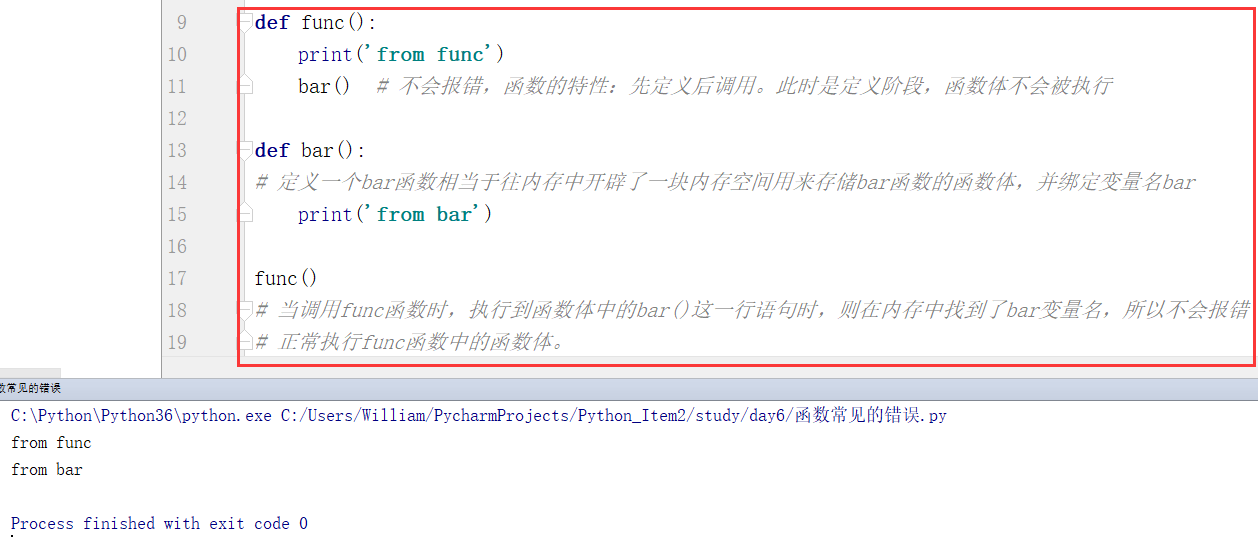
流程图如下:
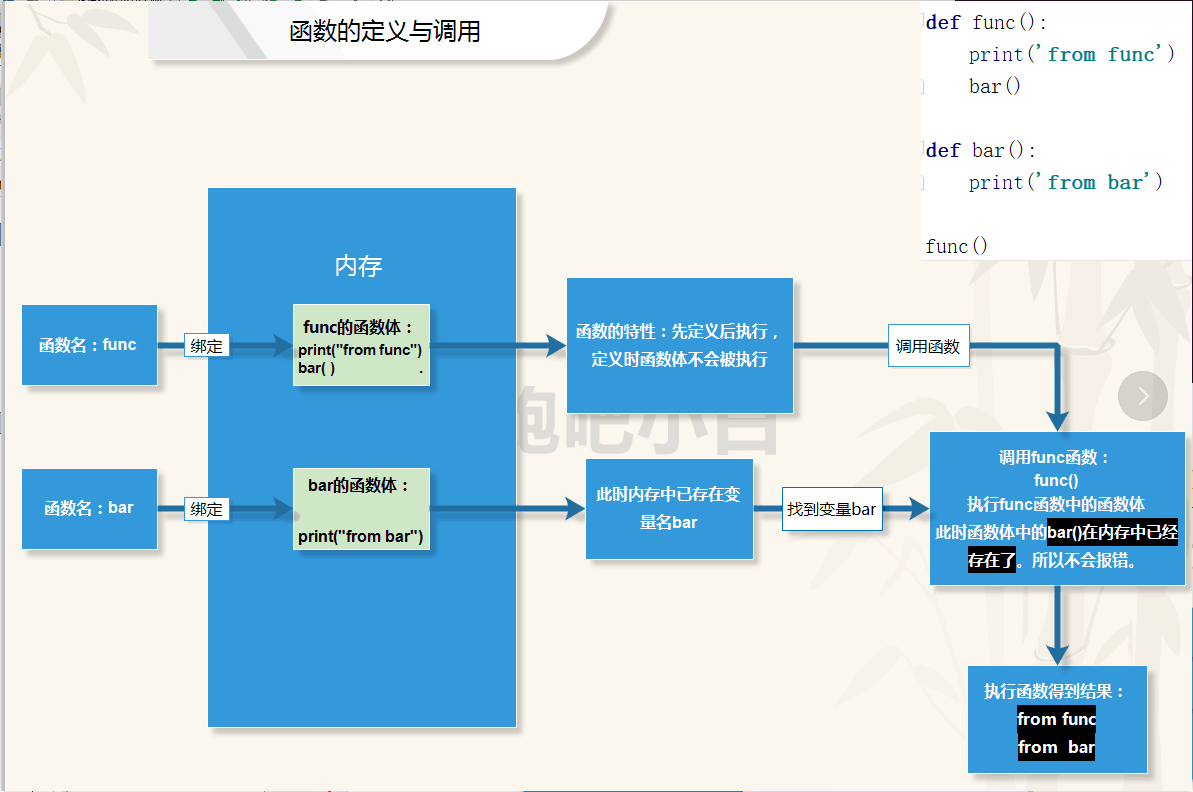
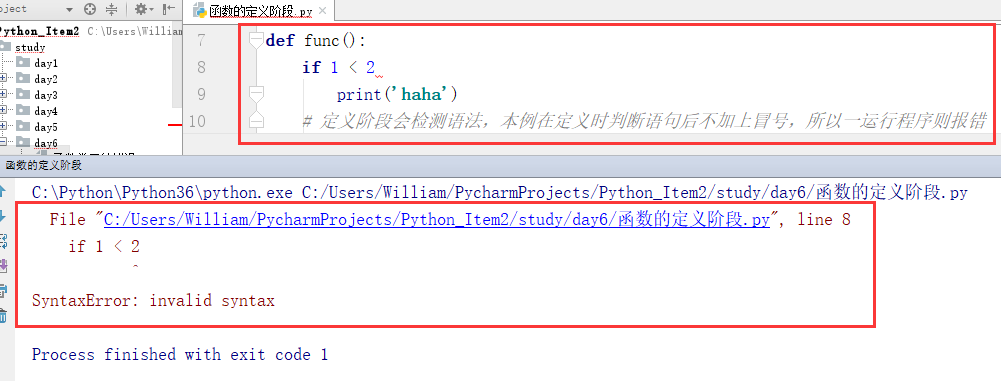
3、函数的定义阶段与调用阶段:
定义阶段:只检测语法,不执行代码。
如果没有语法错误,代码就不会执行。如果有语法错误则会报错
例:
三、函数的返回值:
python的函数可以有返回值也可以没有返回值,看具体需求
1、语法:
def 函数名(参数...):
函数体
return 要返回的值
通常情况下,有参函数需要返回值,因为有参函数调用时要通过外部传入进来值进行计算,最终要得到一个计算的结果,就要用到返回值的功能。
2、返回值的几种形式
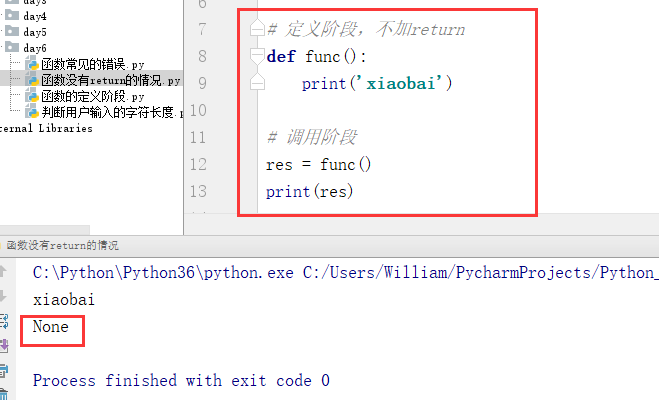
(1)没有return默认返回:None
例:
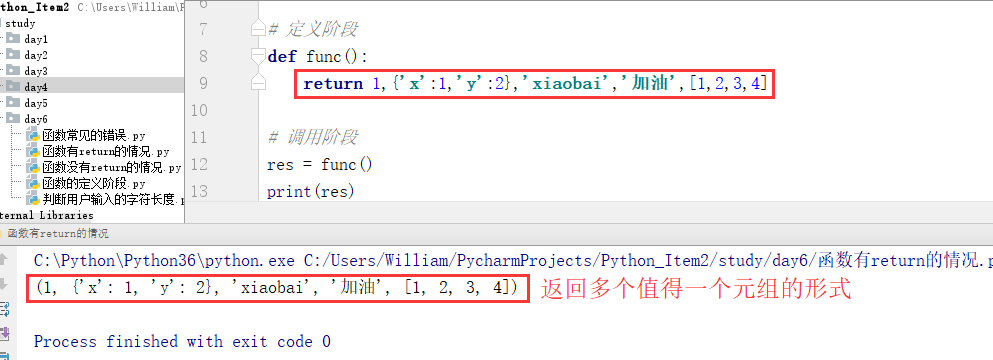
(2)有return时可以返回一个或多个任意类型的值。当返回多个值时(用逗号隔开),得到元组的形式。
例1:返回一个值
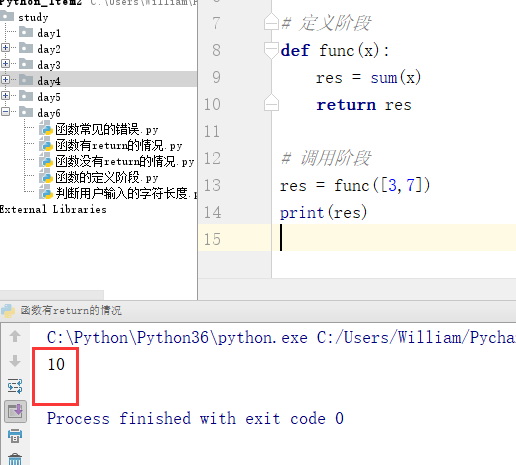
例2:返回多个值
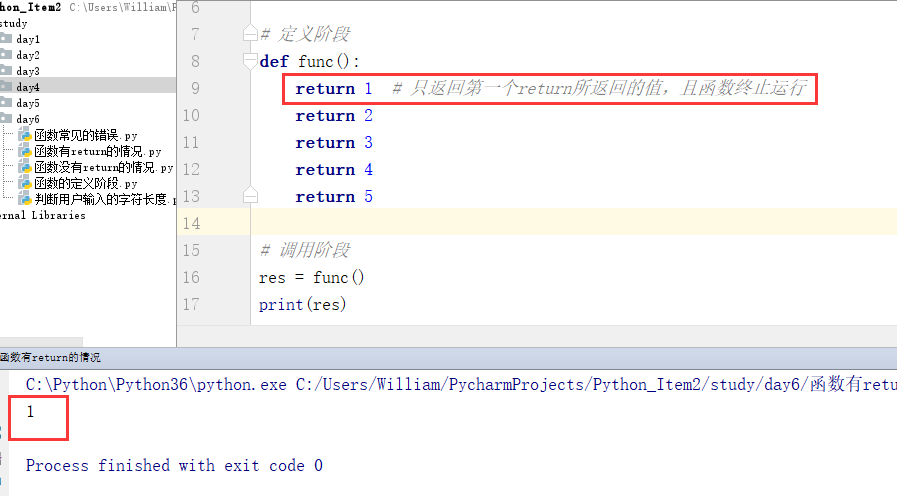
(3)当函数中有多个return时,只能返回第一个return的值且函数终止运行
例:
四、位置参数与关键字参数
Python是一门弱类型的语言,它定义一个变量可以传任意类型的值。
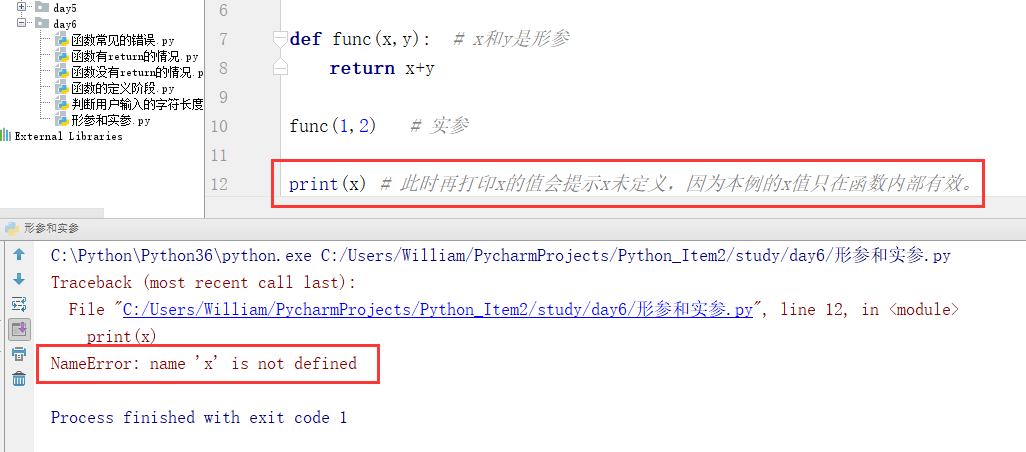
1、形参与实参
定义:形参只是形式存在,不是真的;实参是真实存在的,有值的。
例:

形参和实参的关系:
形参是变量名,实参是值,它们的关系是值一定要绑定给一个变量名才能够存储,所以形参在定义阶段不会占用内存空间,只有在函数调用的时候才会绑定值,这层绑定关系只在调用时生效。当函数执行完后,这层绑定关系则会失效。
例:
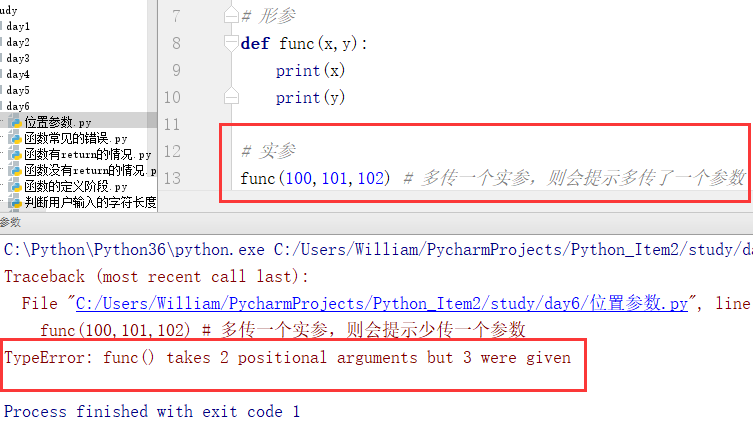
2、位置参数
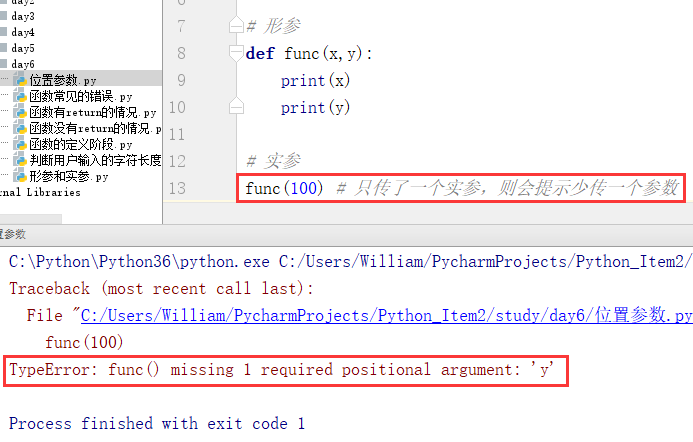
定义:按位置以逗号分隔从左至右的顺序依次定义的参数叫做位置参数
(1)位置形参
特点:必须被传值,不能多传也不能少传,否则报错。
例:
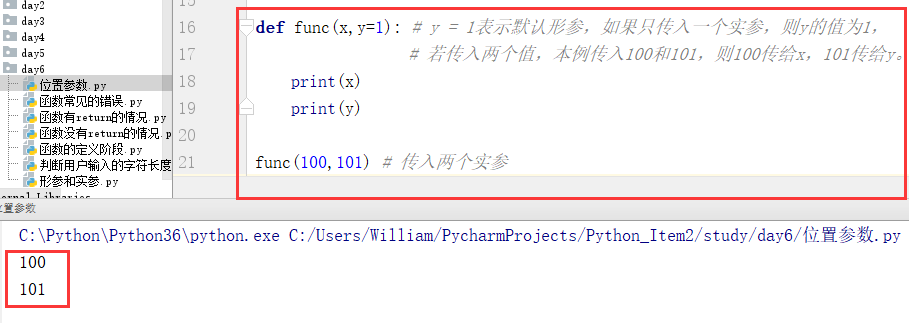
(2)位置实参
特点:位置实参必须与位形参一 一对应
3、关键字参数
关键字参数指的是实参——关键字实参
特点:实参在定义时按照"key = value" (字典)的形式定义,不用像位置实参一样一 一对应的传值。指名道姓地传值
例:

关键字实参与位置实参混用时要注意的问题:
问题一:
位置实参一定要在关键字实参的前面,否则报错!
例:
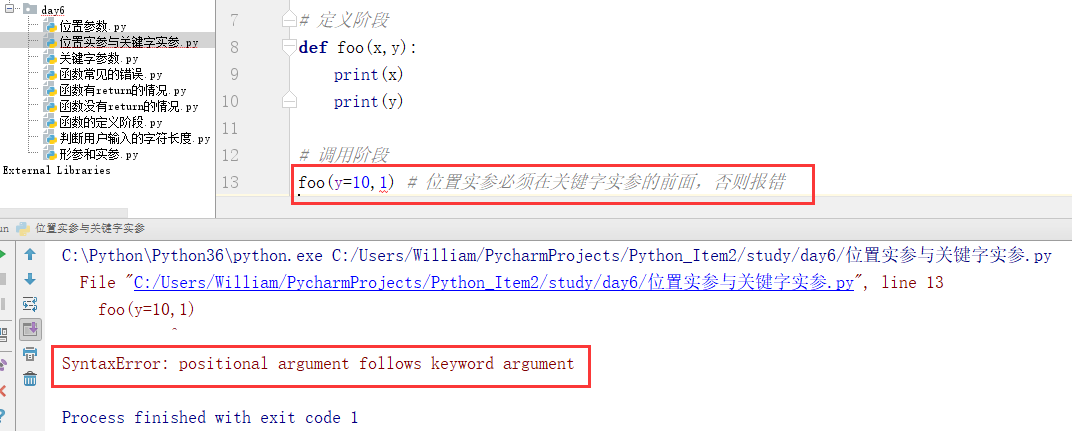
问题二:
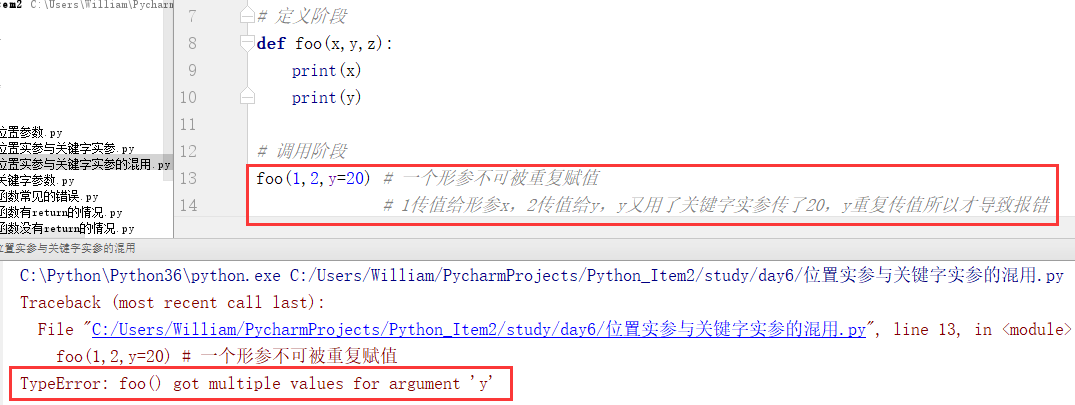
关键字实参与位置实参混用时,一个形参不能被重复传值。
例1:
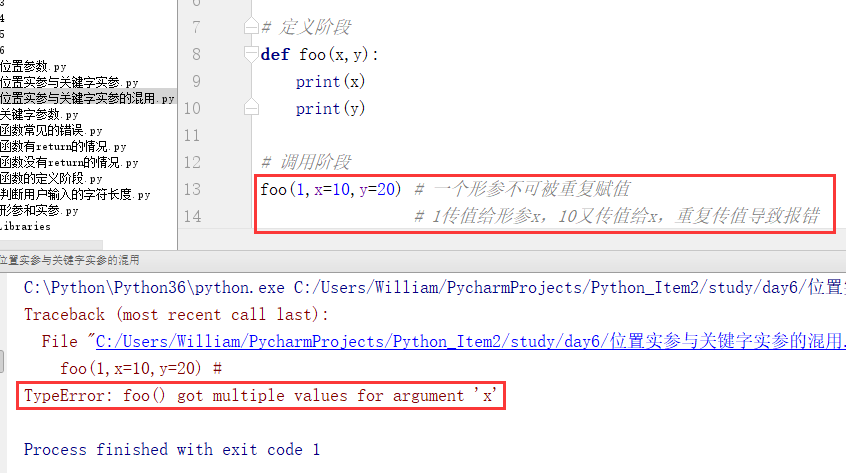
例2:
五、可变长参数
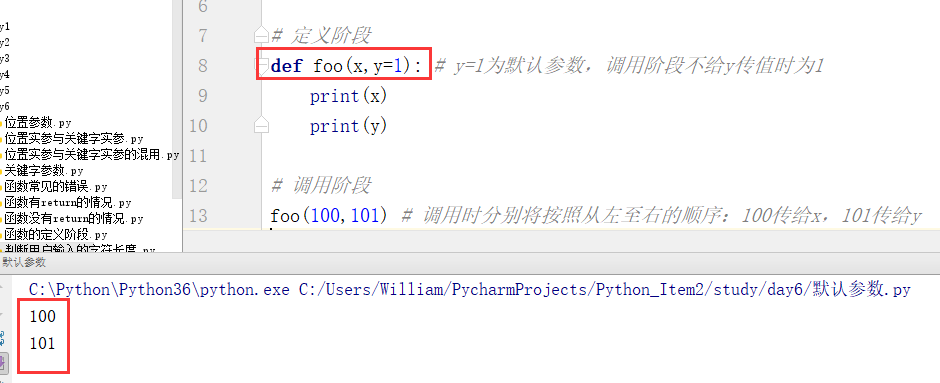
1、默认参数
默认参数指的是形参:在定义阶段就已经为形参赋值。定义阶段有值时,调用阶段可以不用传值
例1:
例2:
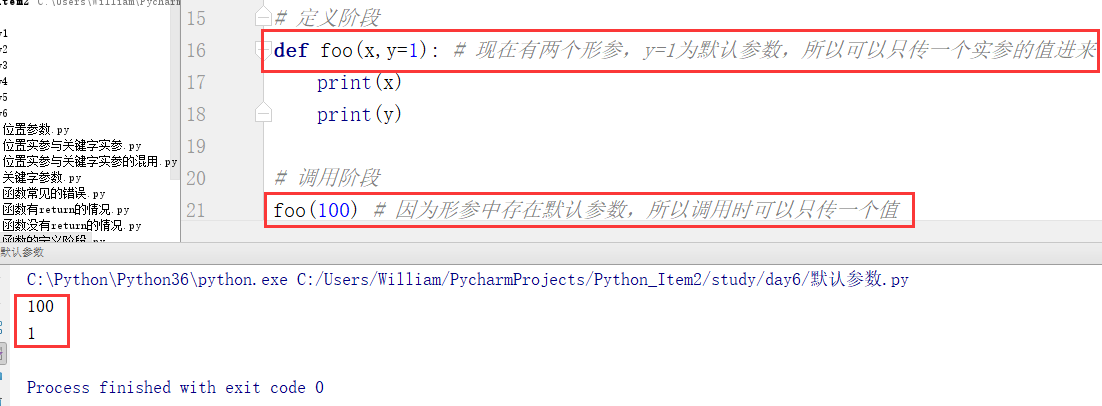
2、默认参数要注意的问题
在函数定义时:
(1)默认参数一定要在位置形参后面。
(2)默认参数通常要定义成不可变类型
(3)默认参数只在定义阶段被赋值一次
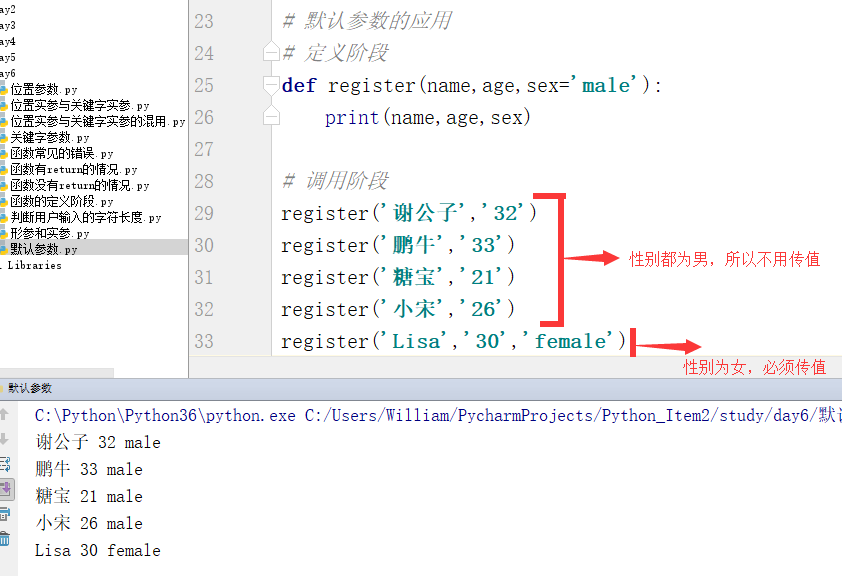
通常情况下,默认参数用于很少改变值的情况下,而位置形参则用于经常要改变值的情况下:
例1:
进入公司应聘时,搞IT这块的一般都是男的比较多,所以填写时的性别可以默认为男性,这里就要用到默认参数:
例2:

3、可变长参数 (重点)
定义:可变长参数指的是实参的个数不固定,所以形参必须要有一个规则来处理从实参传过来的值。
(1)按位置定义的可变长度的实参:
符号: *
作用:接收按位置定义的实参,再赋值给一个变量保存下来,通常用变量名args表示: *args
例1:
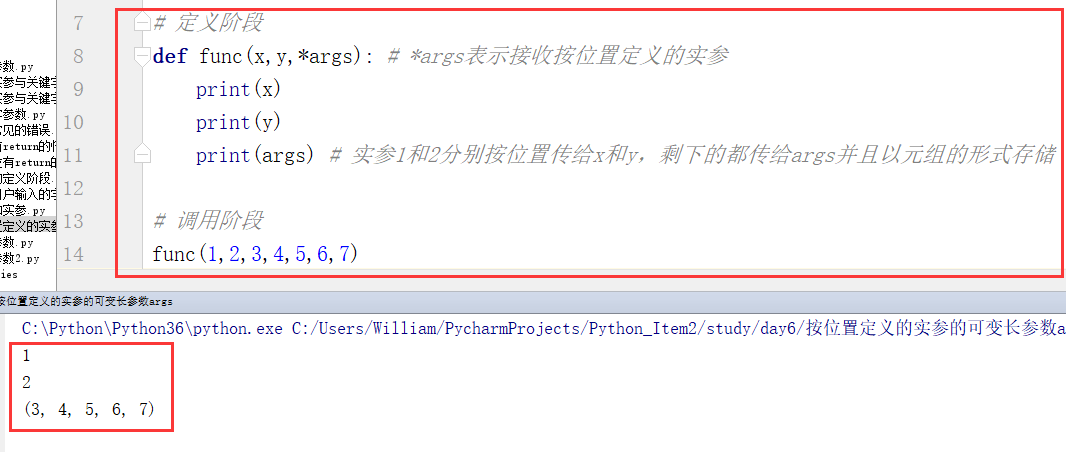
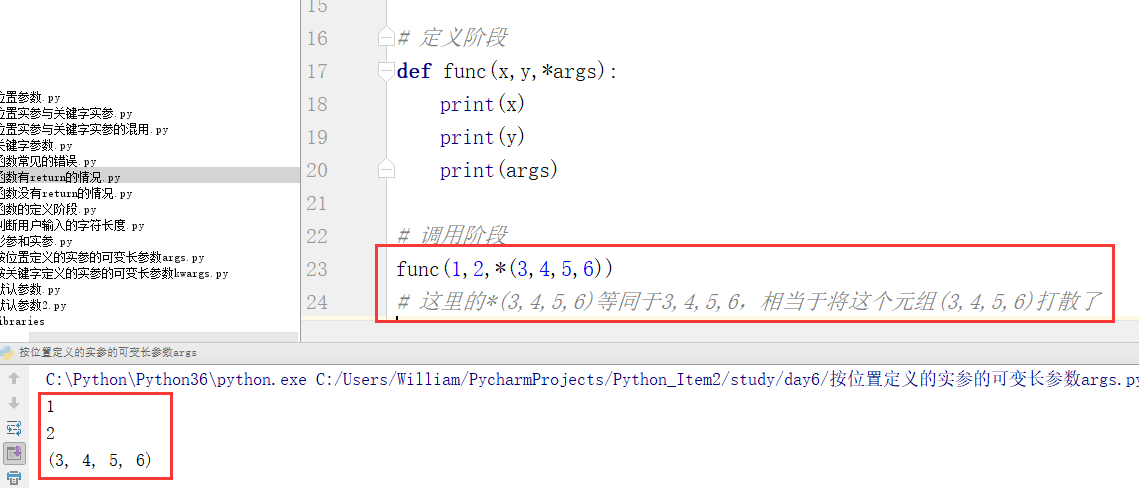
例2 :
*(参数1,参数2,参数3...) 等同于 参数1,参数2,参数3...
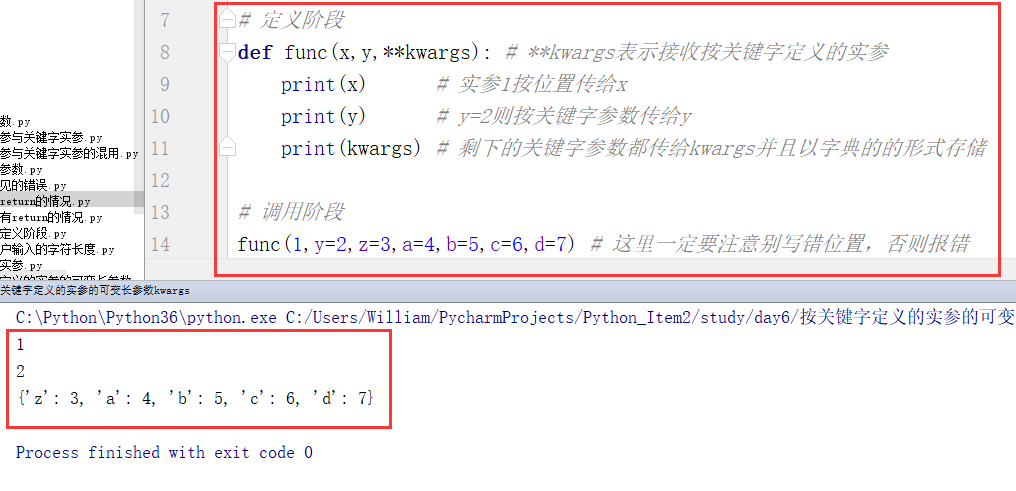
(2)按关键字定义的可变长度的实参:
符号: **
作用:接收按关键字定义的实参,再赋值给一个变量保存下来,通常用变量名kwargs表示: **kwargs
例:
例2:
**{‘key1’:value1,’key2‘:value2,‘key3’:value3...} 等同于 key1=value1,key2=value2,key3=value3...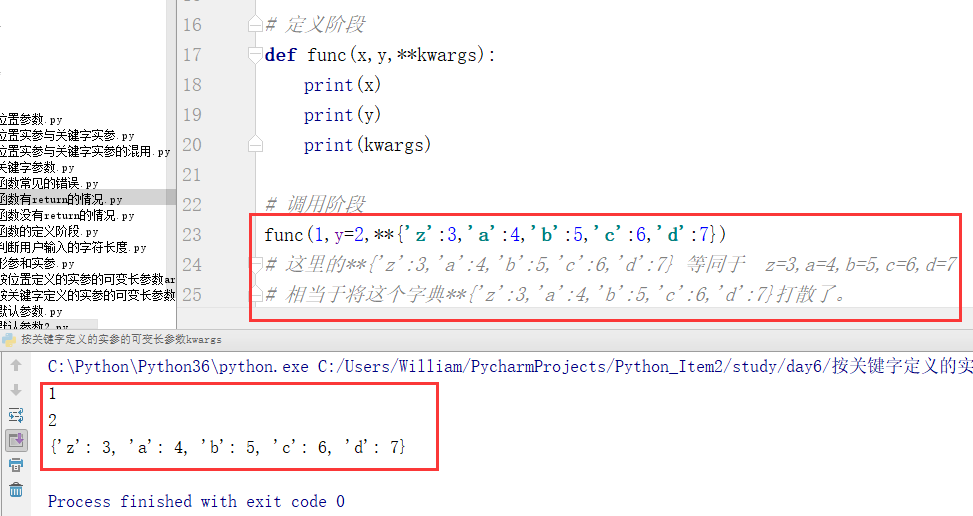
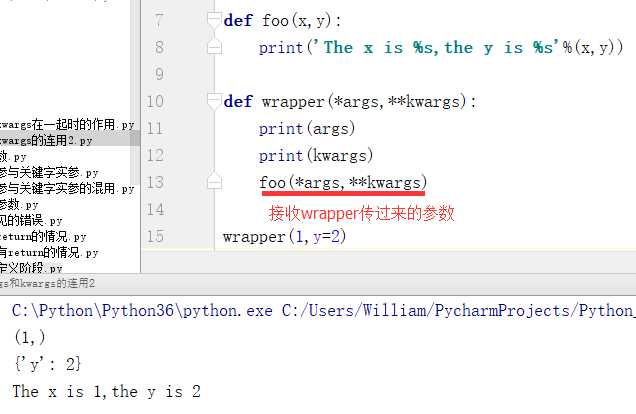
(3)*args和**kwagrs连用时的作用:
两者在一起时表示可以接收任意形式、任意长的参数
例1:
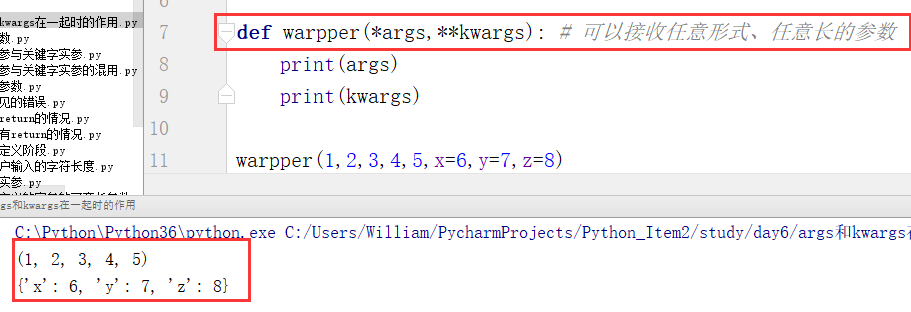
例2:装饰器的雏形
4、 命名关键字参数 (不常用)
(1)命名关键字参数的用法
定义:在形参中,“ * ” 后面的参数叫命名关键字参数,这些参数必须要被传值,且要求实参必须以关键字的形式传值
例:
需求:让用户输入姓名和年龄,并取出用户的姓名和年龄
用户一般都是不按常规了出牌,他不会老老实实地按照我们的流程来传值,有时候,他只传姓名或只传年龄,这里我们的程序就要按以下方式写
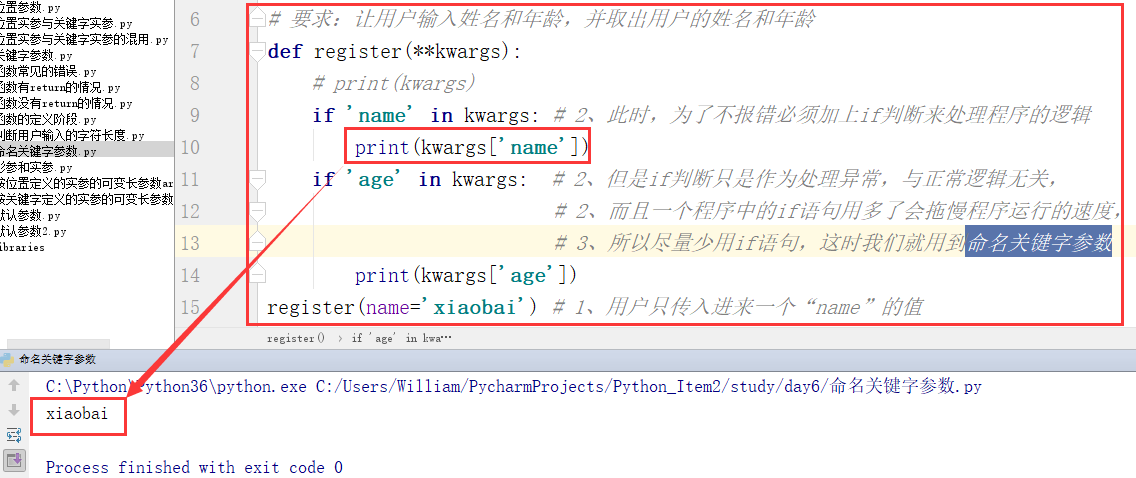
所以,根据以上问题,我们必须将以上程序进行更改:
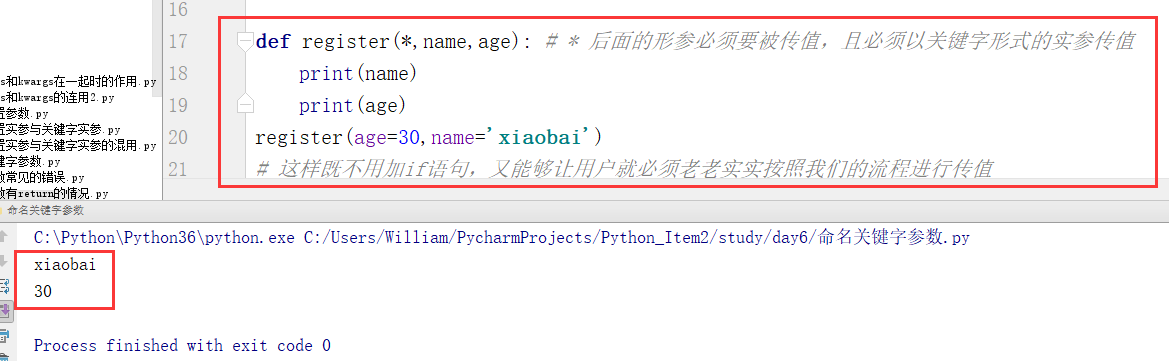
(2)命名关键字参数的补充——*args
在形参中,“ * ”也可以换作 “*args”,表示能接收实参传过来的任意长度的位置参数。
例1:
(3)命名关键字参数的补充——命名关键字参数的默认值
<1>作用:限制实参必须以关键字的形式传值。
<2>命名关键字参数的默认值与默认参数的区别:
它们的功能相同,区别在于它们在形参中的位置不同
命名关键字参数的默认值:
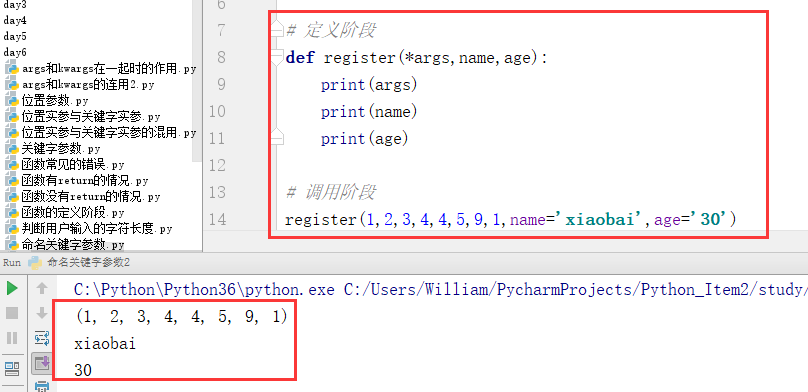
例:def register(*args,name='xiaobai',age): # 本例中的形参name和age只是命名关键字参数。
......
默认参数:默认参数必须在位置参数的后面
例:def register(name,age,sex='male') # 默认参数必须在位置位置形参的后面
......
例1:

例2:
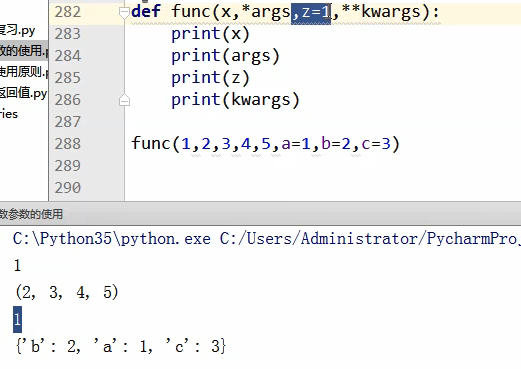
以下例子中,形参中的 “ * ” 后面定义的sex参数必须要被传值,而"**kwargs"则表示接收其它传进来的关键字实参。

例3:
六、函数的嵌套
函数的嵌套分为两种:
1、函数的嵌套调用
作用:减少重复的代码。
例:

2、函数的嵌套定义
函数的定义实际上与定义变量是一样,例:
定义变量:x = 1 # 定义了一个变量名:x
----------------------------------------------------------------
函数的定义:
def x(): # 定义了一个函数名:x
pass
print(x) # 打印这个函数名x,可以得到x的对象,所以函数的定义时,看到def就相当于定义一个变量名。
函数的嵌套定义
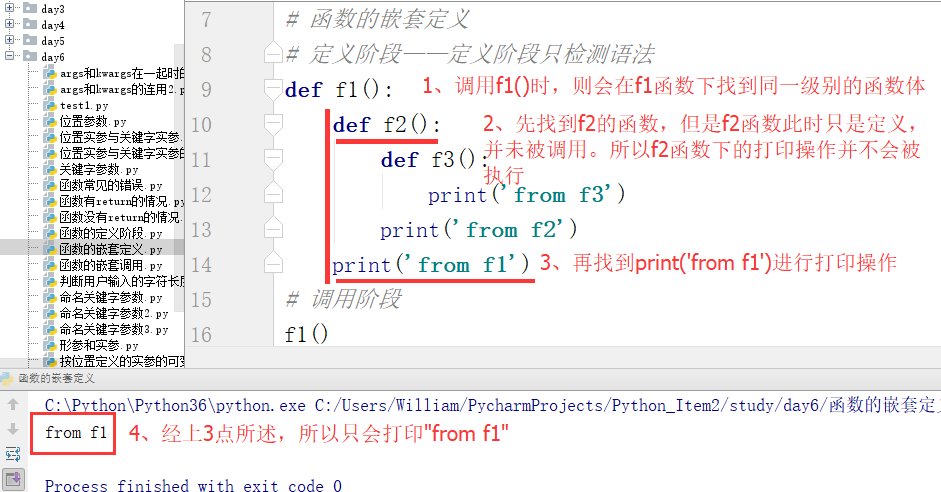
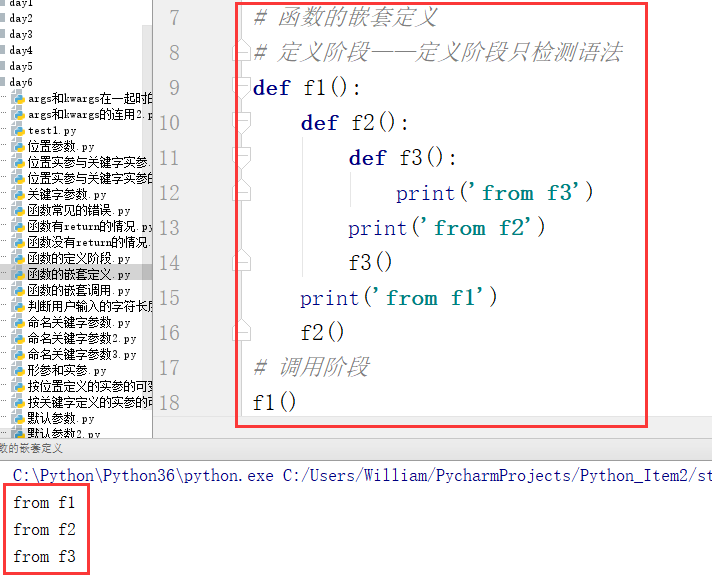
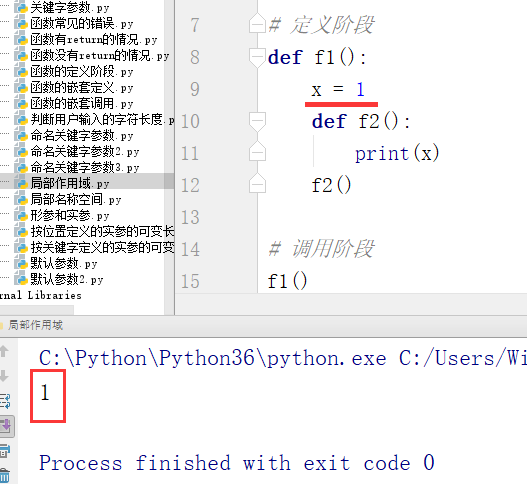
例1:只打印函数f1里的代码
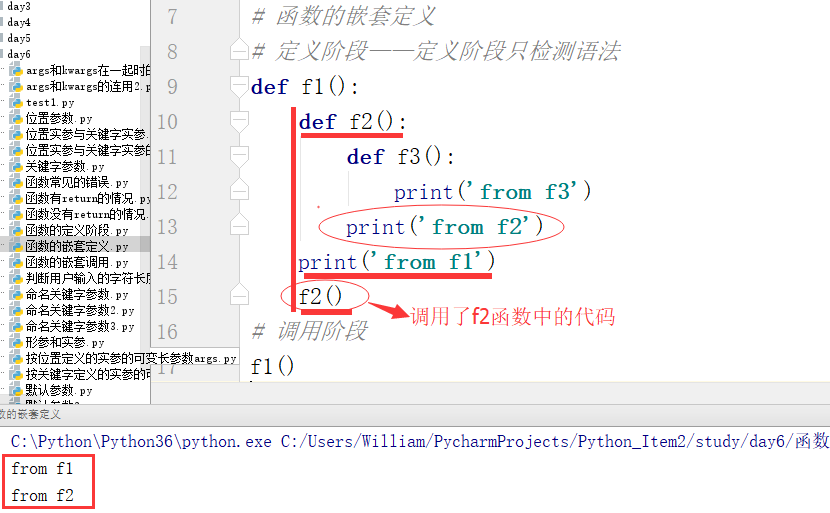
例2:打印函数f1和函数f2里的代码
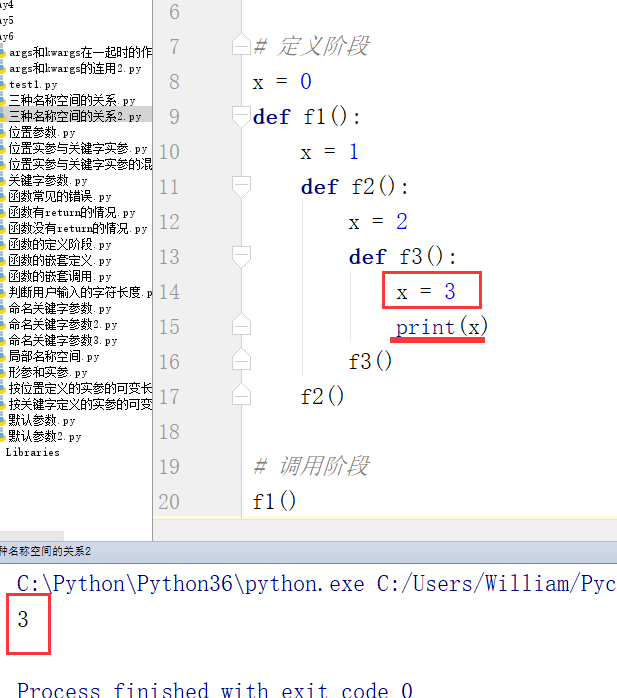
例3:执行函数f1、函数f2和函数f3里的代码
执行函数f1、函数f2和函数f3里的代码的过程:
第一步:

第二步:

第三步:

最终结果:
七、三种名称空间
名称空间
定义:存放名字与值的绑定关系的地方,呈现的都是字典的形式
例:之前学过的定义一个变量,如 ”x = 1“,”1“是被存放到内存开辟的一块内存空间里了,那“x”这个变量名以及和值 “1”的绑定关系则被存放到了名称空间里了。这个名称空间它也是在内存里开辟了一块空间。
名称空间分为三种:
1、内置名称空间
定义:Python解释器自带的变量名存放的空间。
生效:Python解释器启动则会生成内置名称空间。
失效:关闭python解释器后则失效
如:print、len、max、min、sum等等,只要python解释器一启动,这些名字便能直接使用。
2、全局名称空间
定义:文件级别的名字都会存放到全局名称空间。(不是内置的也不是函数内部定义的名字都是在全局名称空间里)
生效:执行python文件时则会生成全局名称空间。
失效:文件执行完后则失效
什么是文件级别的名字?
答:通俗地说就是顶头写且没有缩进的变量名
例:


3、局部名称空间
定义:定义在函数内部的名字
生效:函数调用时生效
失效:函数调用结束后失效
例:

4、三种名称空间的关系
按加载顺序排序:内置名称空间——>全局名称空间——>局部名称空间
按取值顺序排序:局部名称空间——>全局名称空间——>内置名称空间
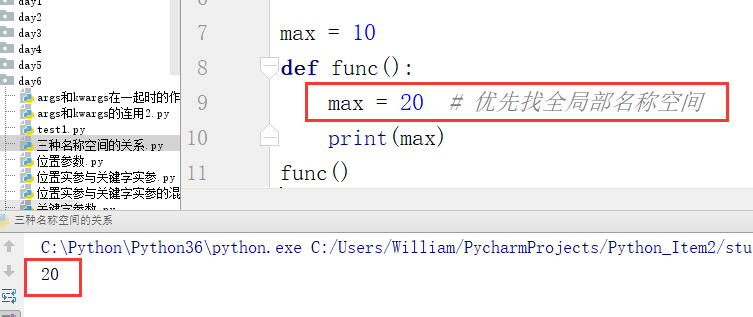
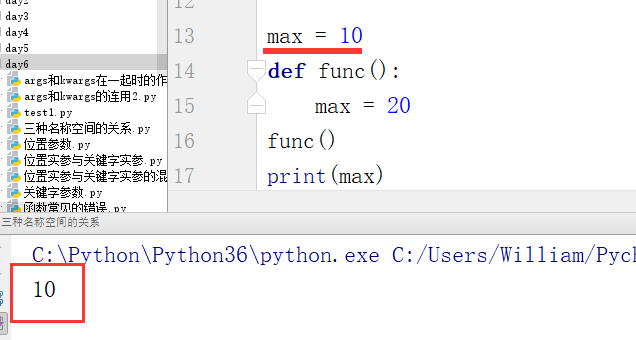
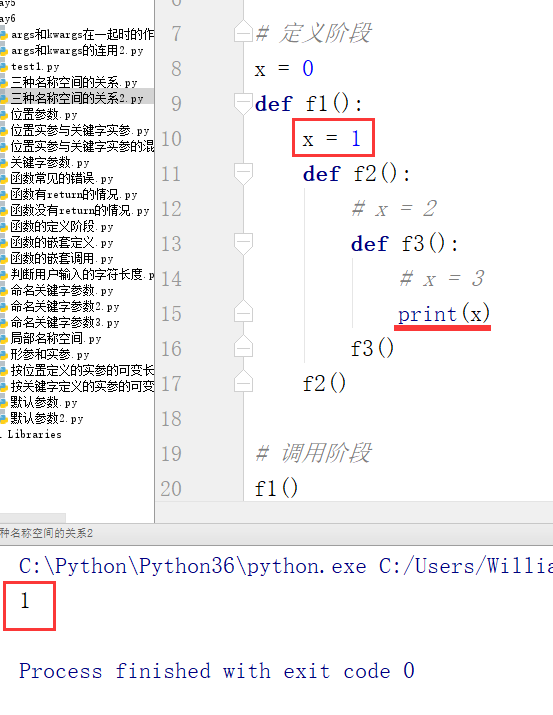
例:
max是内置函数的变量名,现将max变量名分别定义成内置、全局、局部,此时这三个名称空间里处存一份变量名。然后进行取值操作,证明它们的排序顺序
步骤一:
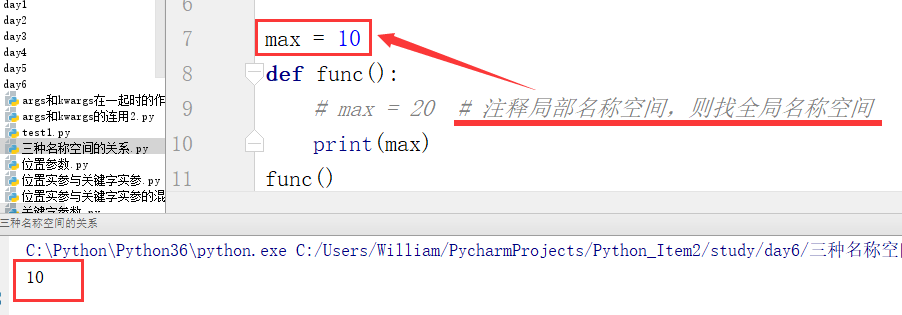
步骤二:
步骤三:
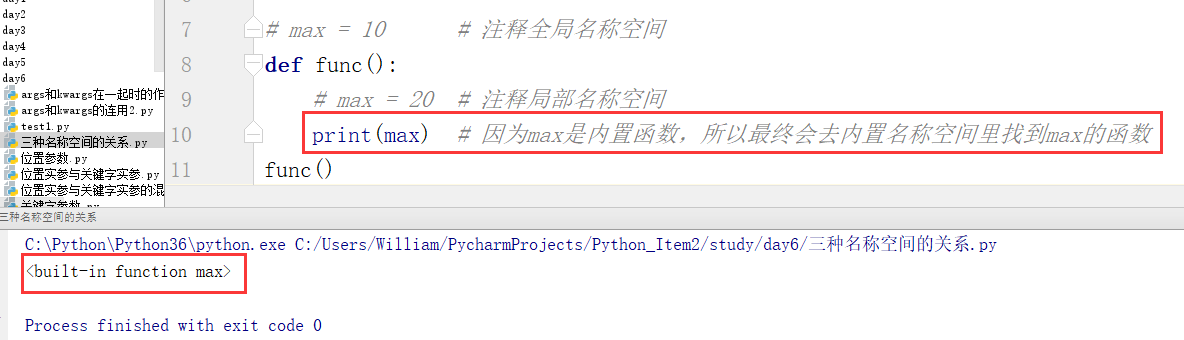
通过以上例子最终证明三种空间的取值顺序是局部名称空间——>全局名称空间——>内置名称空间
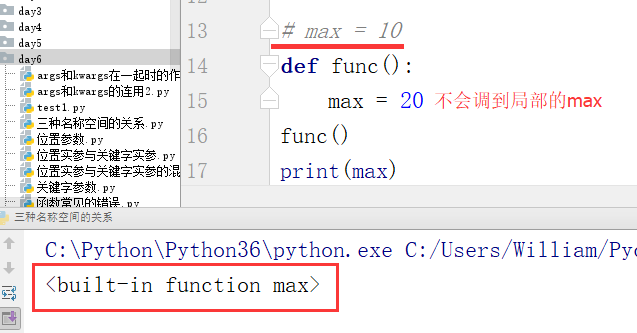
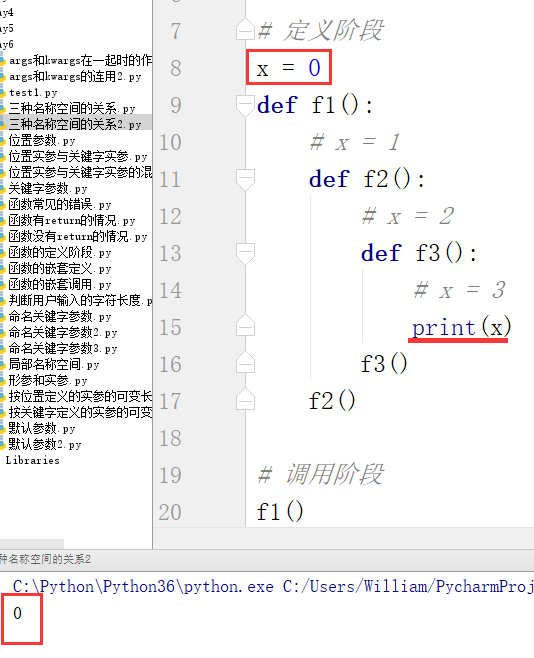
补充1:全局的局部仍然是全局
例:
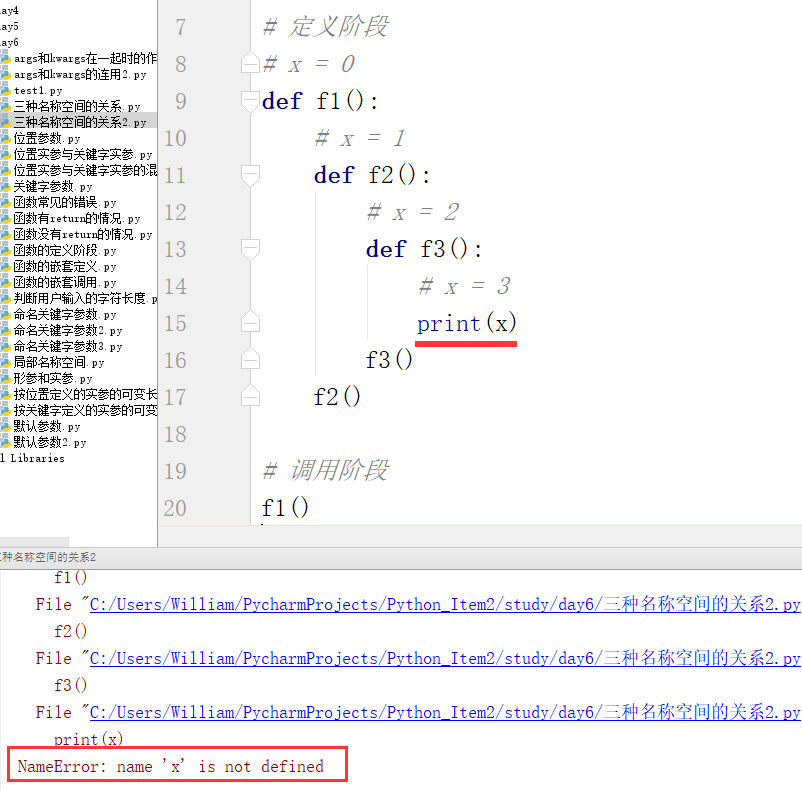
补充2:名称空间与名称空间之间是一种互相隔离的关系。
例:用以下例子证明查找顺序
八、作用域
定义:生效范围
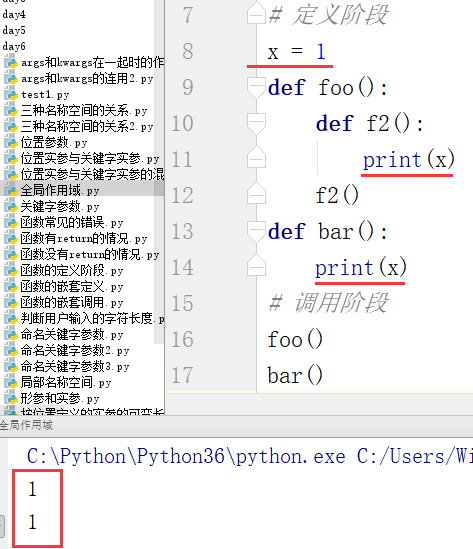
1、全局作用域
定义:包含内置名称空间和全局名称空间的名字,属于全局范围
生效:在整个文件的任意位置都能被引用,全局有效
例:
2、局部作用域
定义:局部名称空间属于局部范围。
生效:只在函数内部可以被引用,局部有效
只能从内看到外,不能从外看到内
例:
3、总结:
名称空间只是用来存放名字的地方,而查找名字则与范围有关
找一个名字跟所在的位置有关,这个所在的位置就是一个范围的概念,它优先从当前位置开始找:
局部作用域——>全局作用域
所以作用域才是我们找名字的概念
4、globals和locals
globals是查看全局名称空间的作用域的名字
返回的是当前的全局作用域的名字,而全局作用域的名字又包含全局和内置的名称空间的名字
locals是查看局部作用域的名字
局部作用域只包含局部名称空间自己的名字
例:
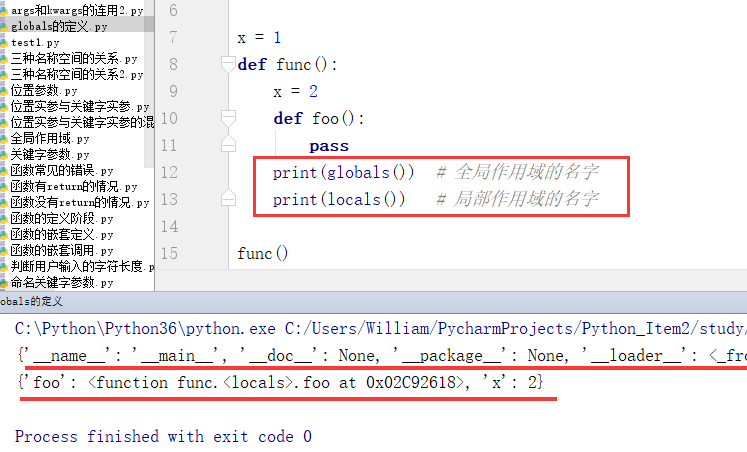
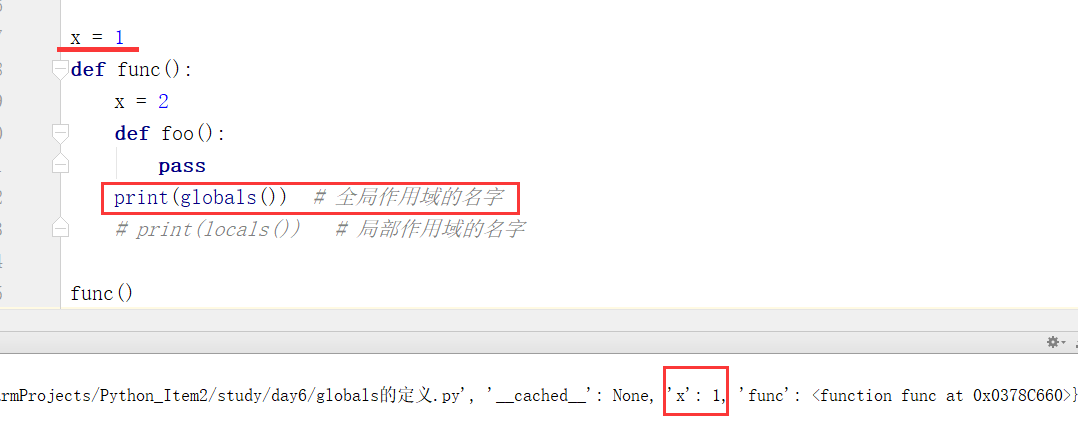
globals既包含全局名称空间名字又包含内置名称空间的名字
(1)globals查看全局名称空间里的名字
(2)globals查看内置名称空间的名字
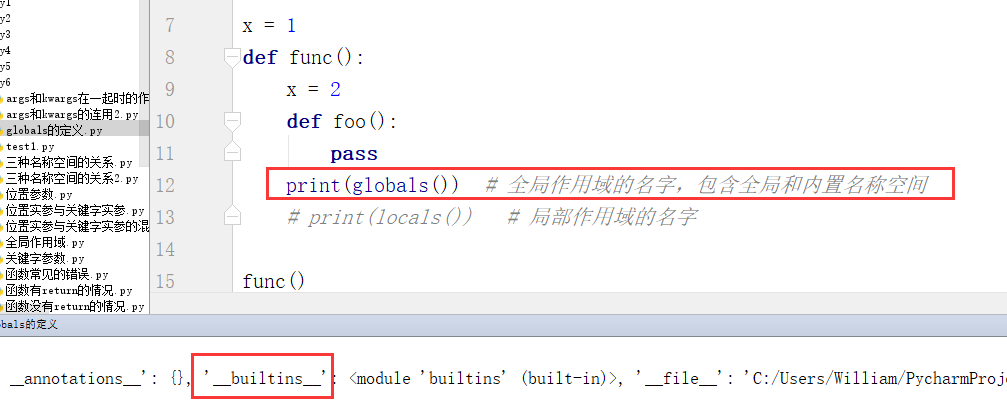
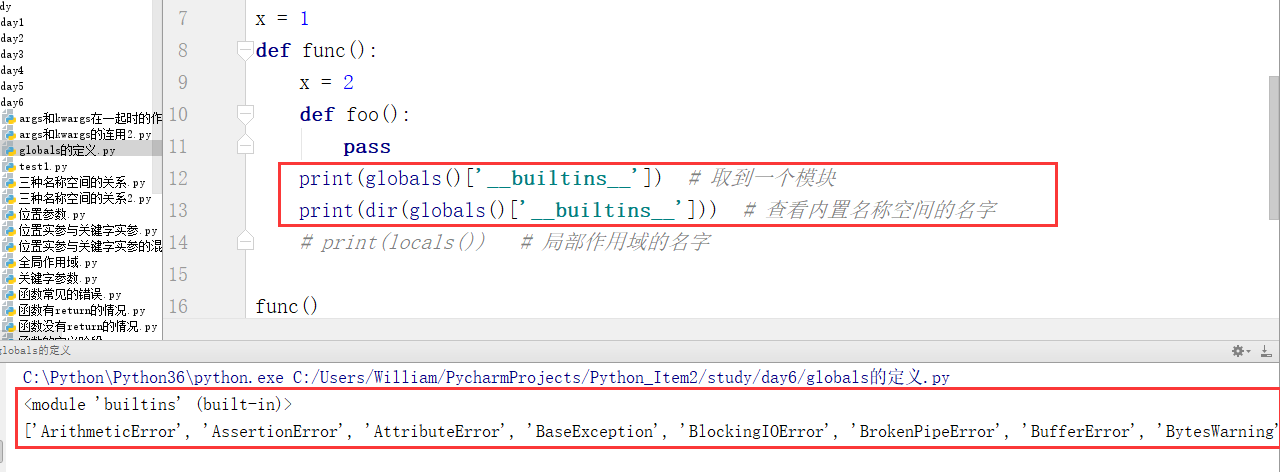
查看得到的结果:


['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
查看全局的范围内的globals和locals,得到一个结果:全局的局部仍然是全局

九、函数对象
1、函数对象
在Python中,函数是第一类对象。
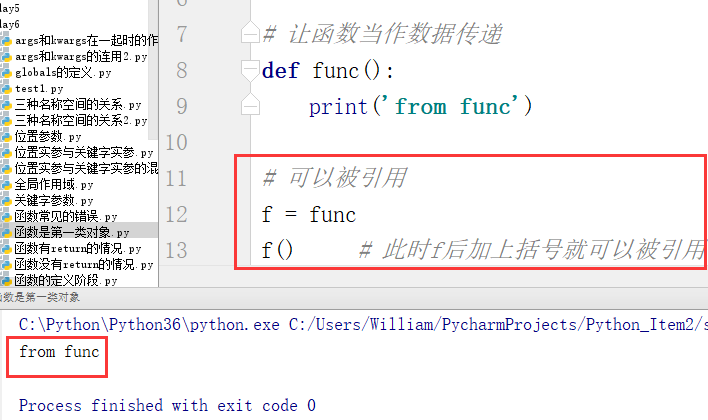
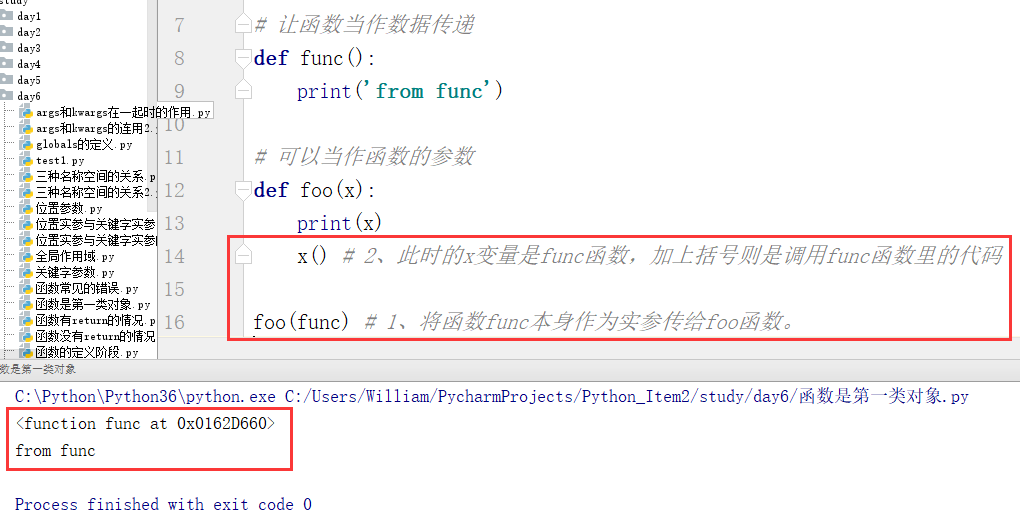
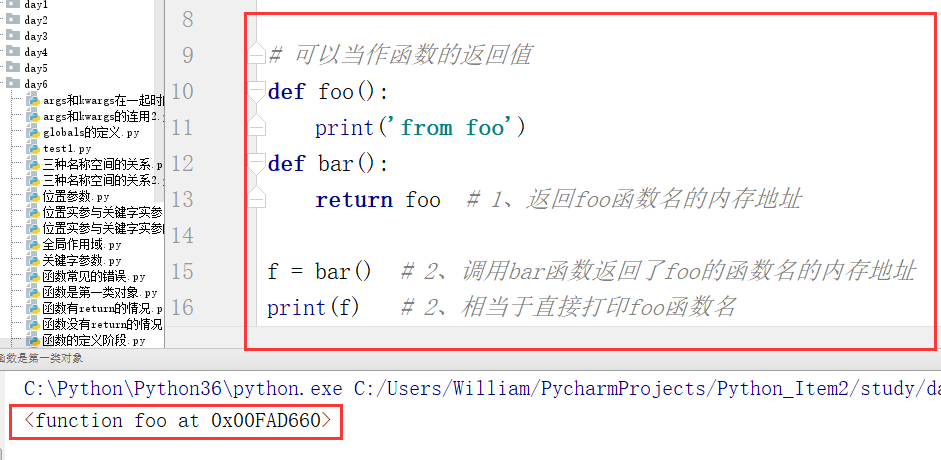
第一类对象:函数可以被当作数据传递。(数据可以做的事,函数也可以做,如:被引用、被当作参数传到一个函数里、可以被当作参数的返回值、可以被当作容器类型的一个元素等)
例:
(1)被引用
(2)被当作函数的参数
(3)被当作函数的返回值
(4)当作容器类型的元素
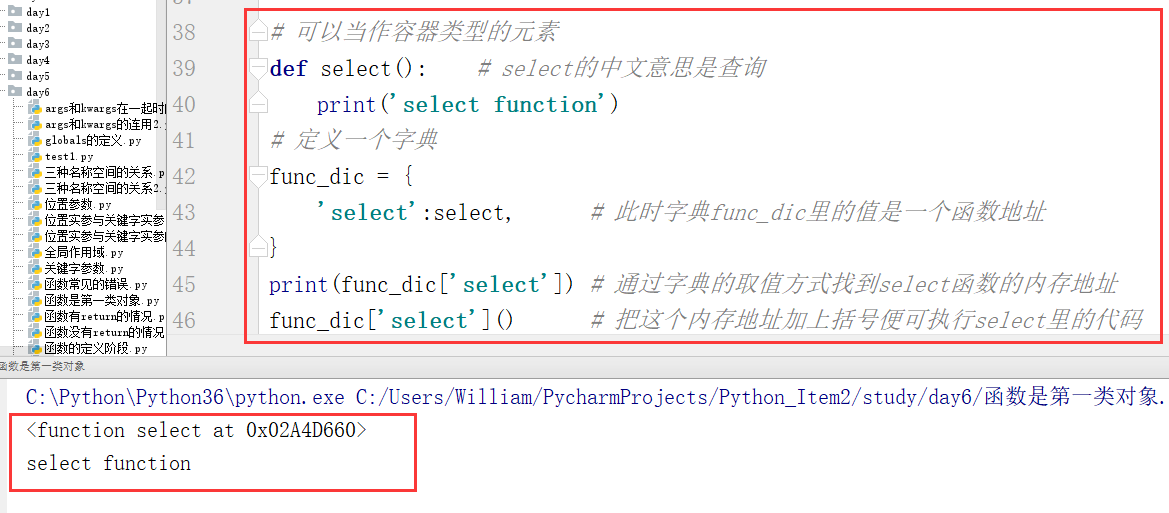
例:
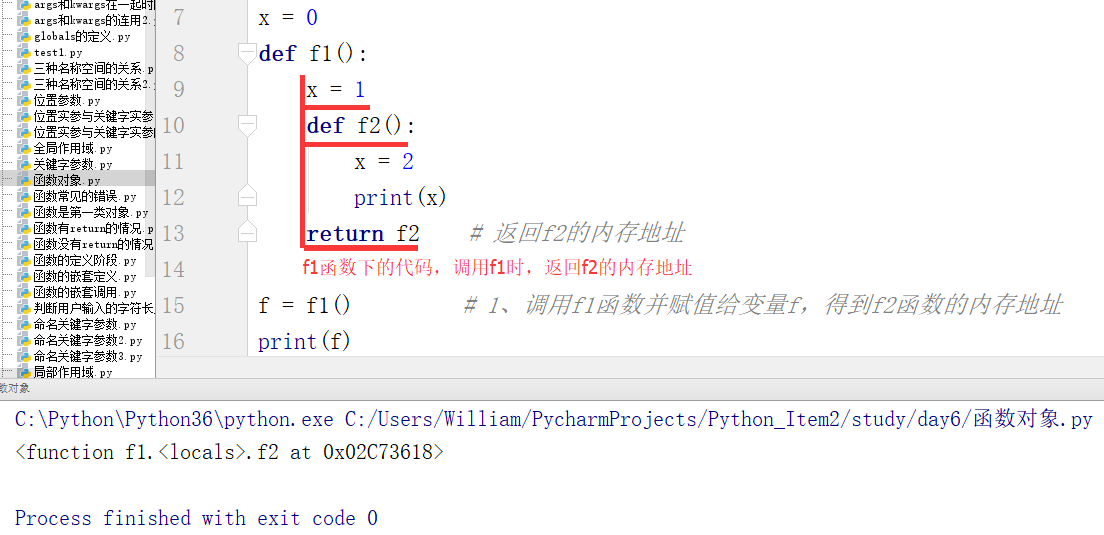
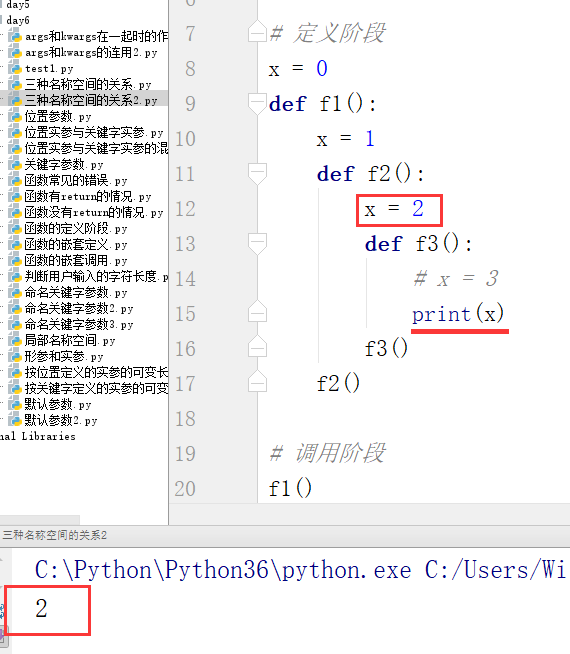
接上面的例子,给变量f加上括号,相当于直接调用f2函数,因为能把它返回到任何位置,所以f2函数的调用不再受层级限制了,此时打印的结果是2,如下图所示:

继续上面的例子,将f2函数中的x=2注释后,此时的打印x值的结果为1,而不是去找函数外面的x = 0,这是因为作用域关系在函数定义阶段就已经固定了,与调用位置无关。函数的调用不受层级限制,但是在调用的时候仍然要回到原来的位置去找作用域关系。

小练习: (重点)★★★★★
写一个文件的增删改查功能
要求:
与用户交互,用多分支判断,根据用户输入的内容不同执行不同的功能,如果用户输入的命令为空则继续输入,如果输入的是查询功能则调用查询的函数,如果是删除功能则调用delect()函数,这四个功能 只需要用print打印效果实现即可。
步骤一:
先定义好一个框架,如下图所示:

步骤二:
将以上框架的代码进行进一步优化
因为elif语句太多,如不将以上代码优化,倘若有100个功能,则需要写100个elif语句,所以为了减少代码冗余,则修改为如下图所示:

这种用字典来存放函数的形式可以很方便地添加新的功能的函数。
步骤3:
要求:将步骤2的代码进行更改,条件如下:
用户在输入查询功能时,不单单只输入字符串select,很可能要对某一个文件的某一行内容进行查询。比如:用户输入select xiaobai a.txt 表示用户要在a文件里查询是否包含有“xiaobai”字符串的内容。(用户输入的内容可以按照程序员自己定义的语法来写逻辑,比如:select a.txt xiaobai)
根据以上需求,用户此时输入的命令不再是一个单纯的命令了,这时得用到字符串的切片命令:split(),本例以空格作为分隔符,用户则必须按照以空格作为分隔符来输入命令。(这个规则由程序员自己定义)
代码如下:
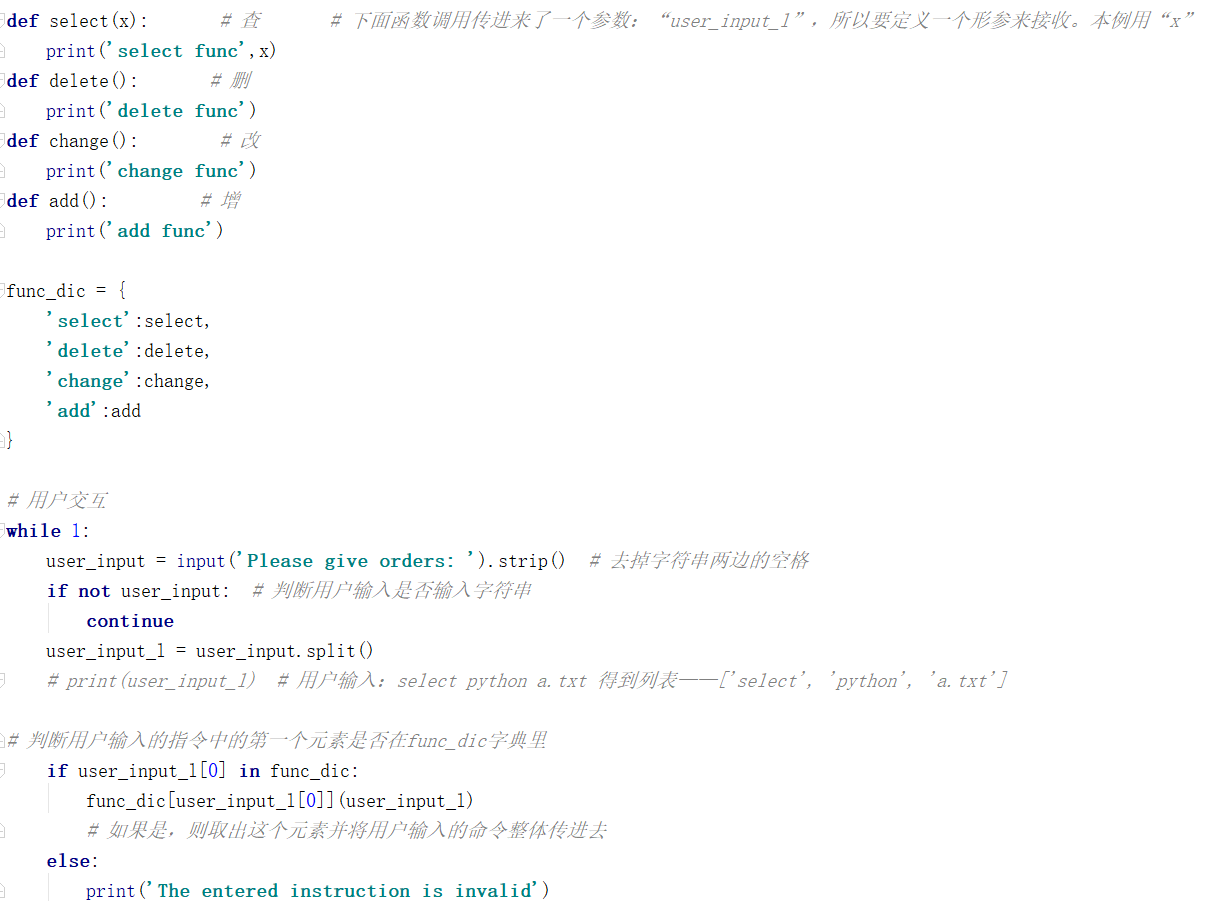
运行得到以下效果:

表示将用户输入的字符串以列表的形式被select函数接收了
步骤4:
创建一个a.txt的文件,文件内容如下:
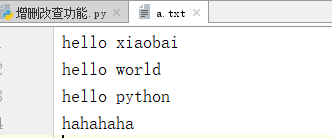
要求:写一个查询的功能,查出包含字符“python”的内容,并打印出该包含“python”关键字所在的行。

源代码:
只实现查了的功能
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# @File: 增删改查功能.py
# Author: xiaobai
# @Time: 2017/10/19 0:57
def select(x): # 查 # 下面函数调用传进来了一个参数:“user_input_l”,所以要定义一个形参来接收。本例用“x”
# print('select func',x) # 注释select函数的打印功能
filename = x[-1] # select函数接收的实参是['select','python','a.txt']
# 用户操作的文件名:a.txt在列表中是最后一个元素,所以写成:x[-1]
pattern = x[1] # (变量名pattern的中文为模式) 这里表示用户要查找的内容:python,在列表的位置是1。
with open(filename,'r',encoding='utf-8') as f:
# 以读的方式打开a.txt文件
for line in f: # 循环a.txt里的每一行内容
if pattern in line: # 判断“python” 字符串是否在这行里。
print(line) # 如果是则打印该行。
def delete(): # 删
print('delete func')
def change(): # 改
print('change func')
def add(): # 增
print('add func')
func_dic = {
'select':select,
'delete':delete,
'change':change,
'add':add
}
# 用户交互
while 1:
user_input = input('Please give orders: ').strip() # 去掉字符串两边的空格
if not user_input: # 判断用户输入是否输入字符串
continue
user_input_l = user_input.split()
# print(user_input_l) # 用户输入:select python a.txt 得到列表——['select', 'python', 'a.txt']
# 判断用户输入的指令中的第一个元素是否在func_dic字典里
if user_input_l[0] in func_dic:
func_dic[user_input_l[0]](user_input_l)
# 如果是,则取出这个元素并将用户输入的命令整体传进去
else:
print('The entered instruction is invalid')
输出结果:
打印出了a.txt文件中包含"python"字符串所在的行
Please give orders: select python a.txt
hello python
2、闭包的概念:
定义:定义在函数内部的函数称为内部函数,该内部函数包含对外部作用域,且不是对全局作用域名字的引用,那么该内部函数称为闭包函数。
举个通俗易懂的例子:快递送的包裹,这个包裹就类似于闭包,我们只看到这个包裹,看不到包裹内的东西。