鸡汤:
理想啊,你就像是一朵生在寒冬腊月里还未绽放的梅花,你的生命在满天的大雪中是显得这么的渺小、这么的脆弱。仿佛一阵北风吹过就能把你吹散至尽。未曾绽放你就要枯萎吗?未曾感受过春天的温暖你就要凋谢吗?春天的阳光近在咫尺了,请你一定要咬紧牙关在这冰天雪地的严冬里坚强的挺过去,只有这样才能在春天灿烂的阳光下开出你最美丽的花朵......
——奔跑吧小白
一、拾遗
1、闭包函数
(1)定义:
在函数内部的函数,该函数引用外部作用域而不是引用全局作用域的名字,这个函数就是闭包函数
(2)格式
def 外部函数名(形参): # 接收调用时传过来的参数
def 内部函数名(*args,**kwargs):
引用外部变形参
return 内部函数名 # 内部函数可以打破定义时的层级限制,就可以在任意位置使用了。
(3)验证
验证一个函数是否为闭包函数则用“__closure__”来验证。将会得到一个元组,(如果该闭包函数引用了多个值则得到一个包含多个元素的元组。)
如果打印的结果有值,则为闭包函数,反之会得到None
(4)查看闭包函数引用的值
先用“__closure__”验证得到一个元组,通过“[ ]”取出该元组内的元素,取出元素后通过“cell_contents”查看引用的值
例:
print(f.__closure__[0].cell_contents)
(5)闭包函数的优点
<1>自带作用域
<2> 惰性延迟 (什么时候想执行,加上括号就能执行)
2、装饰器
装饰器是闭包函数应用的场景
(1)定义:
装饰器本质是任意可调用对象 (以现在知识水平,可以认为装饰器就是函数)
被装饰对象也可以是任意可调用对象 (以现在知识水平,可以认为被装饰对象也是函数)
(2)装饰器的特性:
<1>开放封闭原则:对扩展开放,对修改封闭。(修改:修改源代码和调用方式)
<2>装饰器遵循的原则:
不修改被装饰对象的源代码和调用方式
(3)格式:
def 外部函数(func):
def 内部函数(*args,**kwargs):
函数体
return 内部函数
(4)装饰器的语法:
<1>在被装饰对象的正上方单独写一行:@装饰器名
<2>可以叠加多个装饰器,
定义阶段外部函数的计算的顺序是从下至上:。
调用阶段内部函数的执行顺序是从上至下。
(5)查看函数的注释信息
通过函数名.__doc__或help(函数名)便可查看函数的注释信息
<1>help(函数名)

<2>函数名.__doc__

例:

<3>保留被装饰函数原来的注释信息:
要求:
加上装饰器的目的是为了让软件加上功能并且让用户察觉不到。但是上面的例子中,如果用户使用了查看文档命令就会发现破绽了。为了完美地骗过用户,则还需要把注释信息进行更改
修改步骤如下:
步骤一:导入wraps模块:from functools import wraps
步骤二:在装饰器的闭包函数上面加上一行代码:@wraps(被装饰函数传过来的函数名)
例:
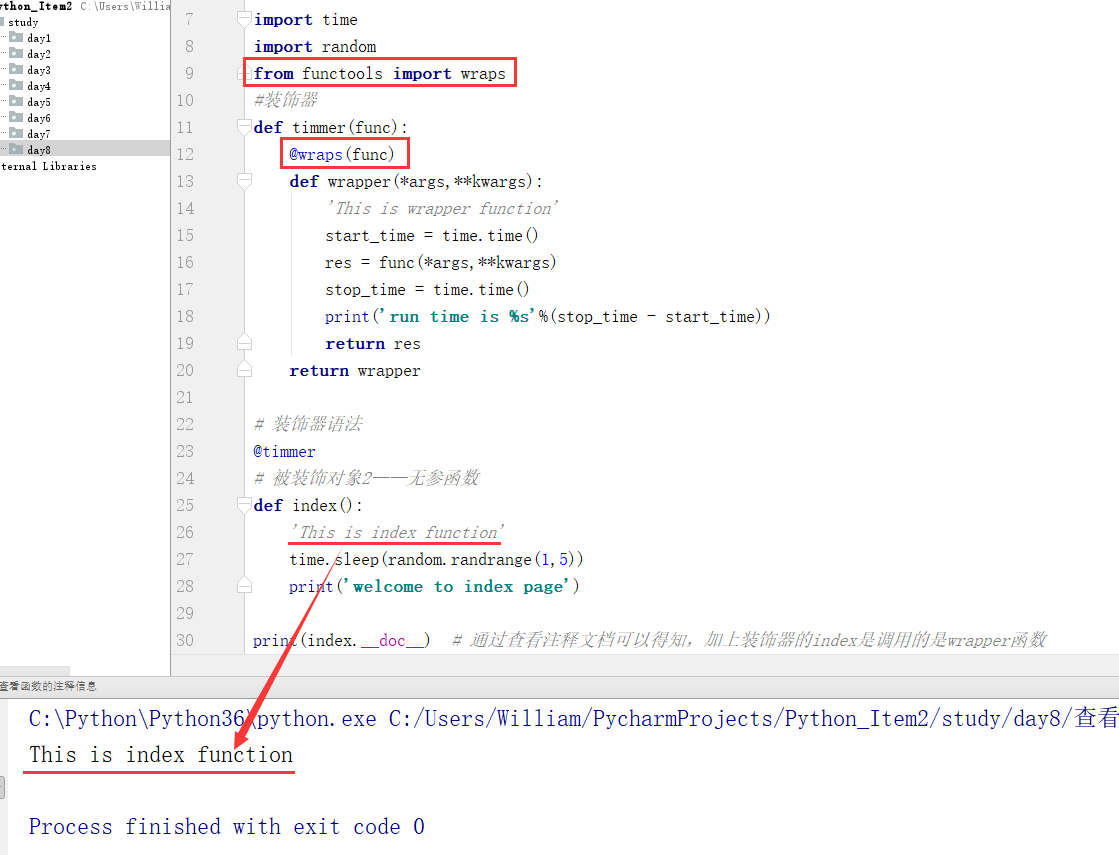
源码:
import time
import random
from functools import wraps
#装饰器
def timmer(func):
@wraps(func)
def wrapper(*args,**kwargs):
'This is wrapper function'
start_time = time.time()
res = func(*args,**kwargs)
stop_time = time.time()
print('run time is %s'%(stop_time - start_time))
return res
return wrapper
# 装饰器语法
@timmer
# 被装饰对象2——无参函数
def index():
'This is index function'
time.sleep(random.randrange(1,5))
print('welcome to index page')
print(index.__doc__) # 通过查看注释文档可以得知,加上装饰器的index是调用的是wrapper函数
输出结果:


This is index function
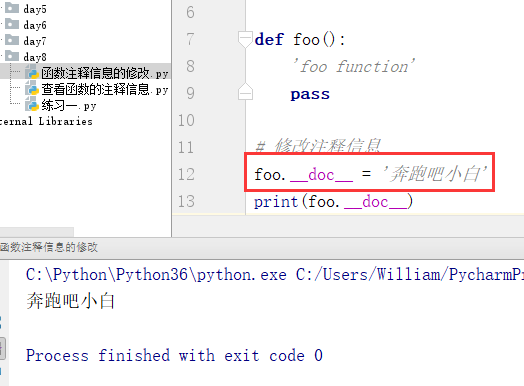
<4>修改注释信息
注意:1、修改函数的注释信息可以在函数外部进行更改,也可以在函数内部进行修改,但是不建议在函数内部进行修改。
2、函数的注释信息是在定义阶段就有的
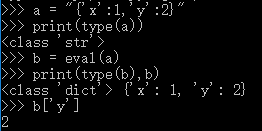
(6)补充:
内置命令:eval()
作用:从字符串中提取python的命令。
例1:

例2:
(7)补充2:
关于修改全局变量时,如果这个变量的值本身是可变类型的数据类型,那么局部作用域中可以改全局作用域中这个可变类型的中的元素
s = 1000
l = [1,2,3,4,]
d = {'x':1,}
def foo():
s = 11111111
l.append(5)
d['x'] = 2
foo()
print(s) # 结果:1000
print(l) # 结果:[1, 2, 3, 4, 5]
print(d) # 结果:{'x': 2}
# 因为字典和列表都是可变类型,在函数内部进行更改的只是可变类型里面的元素,
# 但是没有更改全局变量中的id、type,只是更改了value,
二、装饰器小练习
1、编写函数(函数执行的时间是随机的)
# 编写函数(函数执行的时间是随机的)
import time
import random
def index():
start_time = time.time()
time.sleep(random.randrange(1,4))
print('welcome to index page')
stop_time = time.time()
print('run time is %s'%(stop_time - start_time))
index()
2、编写装饰器,为函数加上统计时间的功能
import time
import random
def timmer(func):
def wrapper():
start_time = time.time()
func()
stop_time = time.time()
print('run time is %s'%(stop_time - start_time))
return wrapper
@timmer
def index():
time.sleep(random.randrange(1,4))
print('Welcome to index page!')
index()
3、编写装饰器,为函数加上认证的功能
import time
import random
# 装饰器1——统计运行时间
def timmer(func):
def wrapper():
start_time = time.time()
func()
stop_time = time.time()
print('run time is %s'%(stop_time - start_time))
return wrapper
# 装饰器2——认证功能
def foo(func):
def wrapper():
username = input('Please input your username:')
password = input('Please input your password:')
if username == 'xiaobai' and password == '123456':
print('Login successfully!')
func()
else:
print('Sorry! Login failed!')
return wrapper
# 装饰器语法
@foo
@timmer
# 原始函数
def index():
time.sleep(random.randrange(1,4))
print('Welcome to index page')
# 调用阶段
index()
4、编写装饰器,为多个函数加上认证功能(用户的账号密码来源于文件),要求登陆成功一次,后续的函数都无再输入用户名和密码
步骤一:
先将正确的用户名和密码写在一个字典里,然后将保存在文件里。
# 创建一个带有账号密码的文件——userinfo.txt
userinfo = {
'xiaobai':'123456',
'lisa':'haha',
'laozhang':'laozhangissb',
'jingliyang':'haha123456'
}
with open('userinfo.txt','w',encoding='utf-8') as f:
f.write(str(userinfo)) # 将userinfo字典转为字符串并写入一个名为userinfo.txt的文件内
步骤二:
给多个函数加上用户认证的功能,只完成题目需求的一半,当调用其它函数时仍然要进行验证
# 4、编写装饰器,为多个函数加上认证功能(用户的账号密码来源于文件),
# 要求登陆成功一次,后续的函数都无再输入用户名和密码
userinfo_path = r'C:UsersWilliamPycharmProjectsPython_Item2studyday8userinfo.txt'
# 装饰器
def auth(func):
def wrapper(*args,**kwargs): # *args,**kwargs是用来接收实参传过来的可变长参数
username = input('Please input your username:')
password = input('Plesase input your password:')
with open(userinfo_path,'r',encoding='utf-8') as f:
userinfo_dic = eval(f.read()) # eval()的作用是从字符串中提取pyhton的命令,这里将字符串转成字典
if username in userinfo_dic and password == userinfo_dic[username] :
print('Login successfully!')
res = func(*args,**kwargs) # 定义时加上*args,**kwargs,调用时也要这样写
return res # 用来返回原函数自带的返回值,如果原函数没有返回值则会返回None
else:
print('login failed!')
return wrapper
# 装饰器语法
@auth
# 原代码1
def index():
print('Welcome to index page!')
return '我快疯了' # 原函数中自带的返回值
# 装饰器语法
@auth
# 原代码2
def home(name):
print('welcome %s to home page!'%name)
# 调用阶段
print(index())
print(home('xiaobai'))
步骤三:
当一个函数认证成功时,其它函数无须再认证。
# 4、编写装饰器,为多个函数加上认证功能(用户的账号密码来源于文件),
# 要求登陆成功一次,后续的函数都无再输入用户名和密码
userinfo_path = r'C:UsersWilliamPycharmProjectsPython_Item2studyday8userinfo.txt'
login_dic = { # 定义一个全局变量,设置默认值:默认情况下是没有用户登陆,所以定义为“None”,用户的登陆状态也用布尔值“False”表示。
# 在用户登陆成功时把输入的用户名加入到login_dic变量里,并将状态改为True
# 在用户下一次登陆进来前进行判断之前是否已登陆过
'user':None,
'status':False,
}
# 装饰器
def auth(func):
def wrapper(*args,**kwargs): # *args,**kwargs是用来接收实参传过来的可变长参数
if login_dic['user'] and login_dic['status']:
res = func(*args,**kwargs)
return res
username = input('Please input your username:')
password = input('Plesase input your password:')
with open(userinfo_path,'r',encoding='utf-8') as f:
userinfo_dic = eval(f.read()) # eval()的作用是从字符串中提取pyhton的命令,这里将字符串转成字典
if username in userinfo_dic and password == userinfo_dic[username] :
print('Login successfully!')
login_dic['user'] = username
login_dic['status'] = True
res = func(*args,**kwargs) # 定义时加上*args,**kwargs,调用时也要这样写
return res # 用来返回原函数自带的返回值,如果原函数没有返回值则会返回None
else:
print('login failed!')
return wrapper
# 装饰器语法
@auth
# 原代码1
def index():
print('Welcome to index page!')
return '我快疯了' # 原函数中自带的返回值
# 装饰器语法
@auth
# 原代码2
def home(name):
print('welcome %s to home page!'%name)
# 调用阶段
print(index())
print(home('xiaobai'))
5、编写下载网页内容的函数,要求的功能是:用户输入一个url地址,函数返回下载页面的结果
# 5、编写下载网页内容的函数,要求的功能是:用户输入一个url地址,函数返回下载页面的结果
from urllib.request import urlopen # 下载网页模块
def get(url):
return urlopen(url).read() # 定义一个下载函数,通过参数传网址
print(get('https://www.baidu.com'))
print(get('https://www.baidu.com'))
print(get('https://www.baidu.com'))
6、为第5题编写装饰器,实现缓存网页内容的功能:
具体操作:实现下载页面存放文件中,如果文件内有值(文件大小不为0),就优先从文件中读取网页内容,否则下载
方法一:
# 5、编写下载网页内容的函数,要求的功能是:用户输入一个url地址,函数返回下载页面的结果
from urllib.request import urlopen
import os
cache_path = r'C:UsersWilliamPycharmProjectsPython_Item2studyday8cache.txt'
def make_cache(func):
def wrapper(*args,**kwargs):
if os.path.getsize(cache_path): # 有缓存,os.path.getsize返回文件大小,如果文件不存在就返回错误
with open(cache_path,'rb') as f:# 则把缓存里面的内容读出来
res = f.read()
else: # 无缓存
res = func(*args,**kwargs) # 下载
with open(cache_path,'wb',)as f:# 制作缓存
f.write(res)
return res
return wrapper
@make_cache
def get(url):
return urlopen(url).read() # 下载网页内容
print(get('https://www.baidu.com'))
print(get('https://www.baidu.com'))
print(get('https://www.baidu.com'))
方法二:
# 5、编写下载网页内容的函数,要求的功能是:用户输入一个url地址,函数返回下载页面的结果
from urllib.request import urlopen
import os
cache_path = r'C:UsersWilliamPycharmProjectsPython_Item2studyday8cache.txt'
def make_cache(func):
def wrapper(*args,**kwargs):
if not os.path.getsize(cache_path): # 没有缓存,os.path.getsize返回文件大小,如果文件不存在就返回错误
res = func(*args, **kwargs) # 下载
with open(cache_path, 'wb', )as f: # 制作缓存
f.write(res)
return res
return wrapper
@make_cache
def get(url):
return urlopen(url).read() # 下载网页内容
print(get('https://www.baidu.com'))
print(get('https://www.baidu.com'))
print(get('https://www.baidu.com'))
补充:
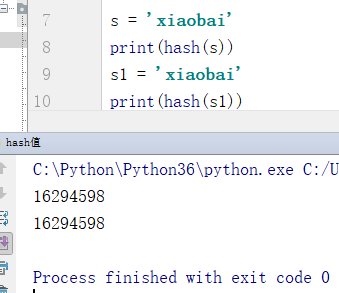
hash
定义:hash是一种算法,这种算法的作用是用来作文本校验
特点:
1、如果字符串的内容不变,经过hash校验后得到的结果永远不变。
2、算法不可以逆。(无法从数字推回去字符)
3、不管文本内容有多大,经过hash校验后得到的数字长度是固定的
例:
扩展:
以上第6题的虽然达到了题目的要求,但是还存在问题:只能缓存一个ur地址,如果换成了不同的url缓存则会出现问题。
解决方法:可以通过hash算法来解决问题。方法如下:
先在当前目录下创建一个cache的目录
from urllib.request import urlopen
import os
import os.path
files_hash = [] #给缓存文件的文件名哈希值存放在一个列表内
cache_path = r'C:UsersWilliamPycharmProjectsPython_Item2studyday8cache' #缓存网页的文件夹
for root,dirs,files in os.walk(cache_path): #遍历文件夹下的内容 root为根目录 dirs为子文件夹 files为文件名
for fn in files:
files_hash.append(hash(fn)) #将文件名遍历出来并将其哈希值存放在列表中
# print(files_hash)
def make_cache(func):
def wrapper(*args,**kwargs):
url=args[0][12:]+'.txt' #www.baidu.com的网页以baidu.com.txt命名
#print(url,type(url))
if hash(url) in files_hash and os.path.getsize(root+'\'+url): #文件存在且大小不为零
#有缓存
print('�33[45m=======>有缓存�33[0m')
with open(cache_path+'\'+url,'rb') as f:
res=f.read()
else:
res=func(*args,**kwargs)
with open(cache_path+'\'+url,'wb') as f:
f.write(res)
return res
return wrapper
@make_cache
def get(url):
return urlopen(url).read()
print(get('https://www.python.org'))
print(get('https://www.baidu.com'))
三、有参装饰器
简单地来说:有参装饰器就实际上就是在无参装饰器的外面包了一层参数而已。
语法:
@装饰器名(参数)
有参装饰器的格式:
程序运行的方向按数字的顺序运行
# 装饰器
def 装饰器名(参数1): # 2、形参接收装饰器语法这里传来的值,此时根据闭包原理,此时第二层函数中包含其内存址址以及从装饰器名传过来的值
def 第二层函数(参数2): # 4、形参接收原函数传过来的值,此时在第二层函数中包含了装饰器名里接收的值、第二层函数的内存址、参数(原函数)
def 第三层函数(*args,**kwargs):
增加的功能
变量名 = 参数2(*args,**kwargs)
return 变量名
增加的功能
return 第三层函数名
return 第二层函数名
@装饰器名(要传入的值) #1、当前位置相当于:@第二层函数 (得到第二层函数的内存地址以及传过去的值)
# 3、此时,相当于无参装饰器的语法一样了,把原函数当作参数传给装饰器的第二层函数
# 被装饰的函数
def 函数名():
函数体
return 一些功能
函数名()
例1:
要求:编写有参装饰器,先定义一个字典,然后能过装饰器把这些函数的函数名都加入到字典里,充当字典的key,字典里对应的value是这些函数的内存地址。
步骤一:先将装饰器传入的参数(原函数名)和原函数的内存地址加入到func_dic字典中,最后打印可以查看字典里的值
func_dic = {}
def make_dic(key):
def deco(func):
func_dic[key] = func # 字典的特性:字典名['键名'] = 值,就相当于把键和值加到字典里了。
return deco
@make_dic('f1')
def f1():
print('from f1')
@make_dic('f2')
def f2():
print('from f2')
@make_dic('f3')
def f3():
print('from f3')
print(func_dic) # 查看函数名与函数的内存地址
输出结果:
{'f1': <function f1 at 0x056236A8>, 'f2': <function f2 at 0x05623660>, 'f3': <function f3 at 0x05623618>}
步骤二:写一个循环判断,用户通过输入key取出value的形式来
func_dic = {}
# 有参装饰器
def make_dic(key):
def deco(func): # 因为只需将原函数的函数名加入字典,并不需要对原函数进行修改,所以无须写第三层函数。
func_dic[key] = func
return deco
@make_dic('f1')
# 原函数1
def f1():
print('from f1')
@make_dic('f2')
# 原函数2
def f2():
print('from f2')
@make_dic('f3')
# 原函数3
def f3():
print('from f3')
while True:
user_input = input('Please enter a command:').strip()
if user_input in func_dic: # 通过键名取出值,这个键名根据用户输入来定
func_dic[user_input]()
输出结果:
Please enter a command:f1 from f1 Please enter a command:f2 from f2 Please enter a command:f3 from f3 Please enter a command:
步骤三——路由功能,路由:把功能隐藏起来,通过路由的方式找到相应的功能,类似于映射。
对于本题目的要求,通过有参装饰器的方式,我们在给有参装饰器传值时,不一定要传与原函数名相同的名字,我们可以根据需求来传名字,譬如:用户一输入index就得到第一个原函数的内存地址,用户一输入home就得到第二个原函数的内存地址,用户一输入bar就得到第三个原函数的内存地址。所以,我们使用有参装饰器的好处就是在这里,可以灵活变动。代码如下:
func_dic = {}
# 有参装饰器
def make_dic(key):
def deco(func):
func_dic[key] = func
return deco
@make_dic('index') # 通过有参装饰器来传给key,可以根据需求灵活传值
# 原函数1
def f1():
print('from f1')
@make_dic('home') # 通过有参装饰器来传给key,可以根据需求灵活传值
# 原函数2
def f2():
print('from f2')
@make_dic('bar') # 通过有参装饰器来传给key,可以根据需求灵活传值
# 原函数3
def f3():
print('from f3')
while True:
user_input = input('Please enter a command:').strip()
if user_input in func_dic:
func_dic[user_input]()
输出结果:
Please enter a command:index from f1 Please enter a command:home from f2 Please enter a command:bar from f3 Please enter a command:
步骤四:如果要用到原函数只需要在在装饰器中添加第三层内部函数即可。
func_dic = {}
# 有参装饰器
def make_dic(key):
def deco(func):
func_dic[key] = func # 字典的特性:字典名['键名'] = 值,就相当于把键和值加到字典里了。
def wrapper(*args,**kwargs):
res = func(*args,**kwargs)
return res
return wrapper
return deco
@make_dic('index') # 把函数自己的名字传给装饰器,返回一个deco,
# 只是这个deco包含了刚刚传过去的参数:f1,这里相当于:@deco()
# 原函数1
def f1():
print('from f1')
@make_dic('home')
# 原函数2
def f2():
print('from f2')
@make_dic('bar')
# 原函数3
def f3():
print('from f3')
while True:
user_input = input('Please enter a command:').strip()
if user_input in func_dic:
func_dic[user_input]()
f1()
f2()
f3()
输出结果:
Please enter a command:index from f1 Please enter a command:home from f2 Please enter a command:bar from f3 Please enter a command:
例2:
将以上练习题第四题给函数加上认证功能的的代码中可能会出现的情况:
用户的认证的来源可能不止一个地方,但是练习4中的认证来源只来源于文件。所以我们要用代码模拟出多个认证来源。代码如下:
def deco(auth_type='file'): # 默认参数,若不传值则使用默认使用该参数
def auth(func):
def wrapper(*args,**kwargs):
if auth_type == 'file':
print('文件的认证方式') # 具体认证功以及取数据的功能这里用print来代替即可
elif auth_type == 'ldap':
print('ldap的认证方式') # 具体认证功以及取数据的功能这里用print来代替即可
elif auth_type == 'mysql':
print('mysql的认证方式') # 具体认证功以及取数据的功能这里用print来代替即可
else:
print('其它认证方式')
return wrapper
return auth
@deco(auth_type='mysql') #
def index():
print('welcome to index page!')
@deco(auth_type='ldap')
def home(name):
print('welcome %s to home page'%name)
@deco(auth_type='aaaa')
def bar():
print('welcome to bar page')
return '哈哈'
index()
home()
bar()