最近一段时间比较忙,都很少来园子逛了,刚好,用到了ElasticSearch,感觉还不错,所以就给大家推荐一下,自己也顺便学习;虽然公司选择用ElasticSearch,但是以前都没有用过这个,而且公司没有一个人对它熟悉,所以比较坑就是,遇到问题,还得自己去解决;好了,其他话就不多说了,先给大家介绍一下ElasticSearch(下面简称ES)吧!
简介
ES是一个开源的基于Lucene的分布式搜索引擎,具备高可靠性。但是,ES并不是一个标准的数据库,它不像MongoDB,它侧重于对存储的数据进行搜索。因此要注意到它不是实时读写的的,这也就意味着,刚刚存储的数据,并不能马上查询到。ES也是支持集群的,通过配置一个集群的名字(不建议使用默认名称),只要环境能联通,启动的时候,凡是集群是这个名字的,都会默认加入到一个集群中。你不需要做任何操作,选举或者管理都是自动完成的。
环境安装
ES是一个基于Lucene的分布式搜索引擎,需要一个java jdk的运行环境支撑(java环境下载),具体安装步骤就不再多说,环境安装问题应该都不大;
java jdk环境安装好了以后,可以开开始安装ES了;下载ES(https://www.elastic.co/downloads/elasticsearch),然后解压到目的目录;
配置ES 的配置文件/config/elasticsearch.yml(我这儿下载的是elasticsearch-5.6.4):
node节点配置
cluster.name: my-application : ES的集群名称,ES会自动发现在同一网段下的ES,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。上面说了,不建议使用默认的名称,所以,改一个靠谱一点的名称吧!
node.name: node-1: ES的节点名称, 一个节点是集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的;节点默认名称是一个随机的,所以,为了找到那台服务器对于那个节点,还是老老实实的配置一个节点名称吧(不建议使用默认的节点名称)!
node.master: true: 指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master(此配置项可以不用再修改)。
node.data: true: 指定该节点是否存储索引数据,默认为true(此配置项可以不用再修改)。
path路径配置
path.data: /path/to/data: 存储路径配置;默认是ES根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:path.data: /path/to/data1,/path/to/data2
path.logs: /path/to/logs: 日志文件存储路径;默认是ES根目录下的logs文件夹
path.conf: /path/to/conf: 设置配置文件的存储路径;默认是ES根目录下的config文件夹
path.plugins: /path/to/plugins: 设置插件的存放路径;默认是ES根目录下的plugins文件夹
Index配置
index.number_of_shards:5 设置默认索引分片个数,默认为5片
index.number_of_replicas:1 设置默认索引副本个数,默认为1个副本
其他配置
network.host: 192.168.0.1:设置其它节点和该节点交互的ip地址必须配置
http.port: 9200 :设置节点间交互的tcp端口,默认是9200
http.max_content_length: 100mb 设置内容的最大容量,默认100mb
http.enabled: false:是否使用http协议对外提供服务,默认为true,开启。
在这,也就列举了一些常见的配置,而其他的一些配置也就不在详细的说了,如果需要,可以自行查询资料。
开始运行
好了,配置也保存,到了这一步,就可以开始测试运行了,cmd窗口打开运行 /bin/elasticsearch.bat或者直接双击运行 elasticsearch.bat
如下图,
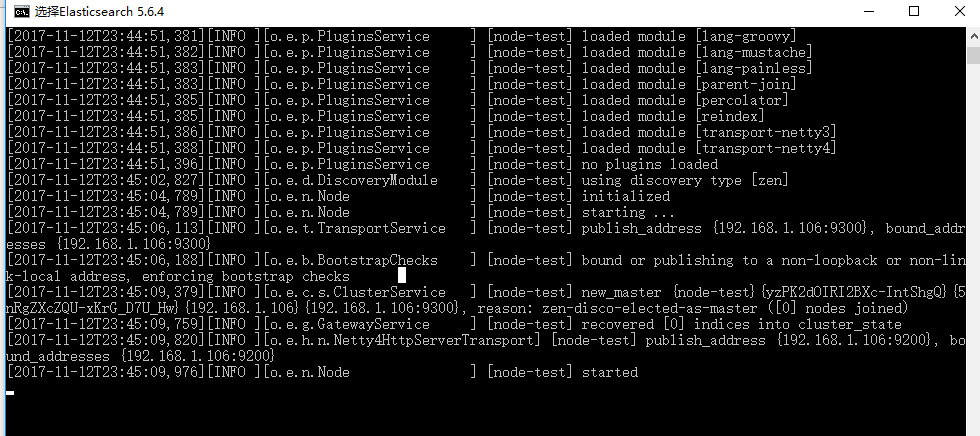
然后浏览器输入你设置的network.host:http:port (例如: http://192.168.0.1:9200) 如下图
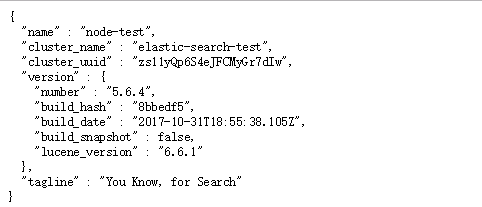
这样就ok了;好了,第一阶段就到了!下次有时间,再写接下来的实践操作!