Get Started
- 我们平常浏览的网页是否是应用
- 在操作系统中的应用是如何运行的
- 浏览器究竟是什么
- webkit和浏览器的关系
- 浏览器是如何呈现网页的
- 经典问题: 从浏览器的地址栏输入一个网站知道网页内容呈现完毕, 发生了哪些事情.
基本概念
浏览器
浏览器是用户访问互联网最重要的接口.
本质上, 浏览器是方便一般互联网用户通过界面解析和发送HTTP协议的软件
浏览器历史
- 1991年, 世界第一个浏览器WorldWideWeb(后改为Nexus), 功能简单, 不支持图片.
- 1993年, Mosaic浏览器出现, 可以显示图片, 为了区分浏览器是否能浏览图片, 出现了UserAgent
- 1994年, Mozilla浏览器出现, 也就是后来大名鼎鼎的网景浏览器, 他的UserAgent为Mozilla/1.0
- 1995年, IE浏览器出现, 为了抢夺市场, UserAgent为Mozilla/1.22
- 1998年, 网景公司浏览器失利, 成立Mozilla组织
- 2003年, 网景公司解散, Mozilla基金会成立, 这个组织推进了后来的Firefox
- 群雄并起, 众多公司的浏览器的UserAgent上都有Mozilla
- Mozilla开发了Geoko, 变成了Firefox, 它的UserAgentMozilla/5.0
- chrome和safar出现, 占有了很大份额
UserAgent用户代理
查看用户代理
- 打开chrome浏览器的控制台
- 在控制台输入navigater.userAgent
- 会发现类似字符串 Mozillz/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36
用户代理的作用
- 判断浏览器类型, 采用兼容方案
- 判断是否是移动端
- 表示H5容器, 方便调用H5容器特定接口
- 要注意userAgent伪装成本很低, 不要过于依赖
内核
对于操作系统来说, 内核 是操作系统的核心, 是第一层基于硬件的软件扩充, 提供最核心最基础的服务.
应用程序通过内核进行 系统调用 来使用计算机的硬件, 内核代码简洁高效, 并且基本没有bug, 由于是最底层的服务, 一点微小的错误也会造成整个系统的崩溃. 好处当然爷显而易见, 基于一个稳定的内核, 开发者可以构建适合不同场景的操作系统和应用软件.
对于浏览器来说, 同样存在 浏览器内核 , 与操作系统内核相似, 浏览器内核需要提供API供浏览器开发者使用, 同时提供最核心的功能, 如加载和渲染页面, 调用操作系统所提供的服务.
对于浏览器厂商来说, 高效使用和开发浏览器内核是核心问题, 对于web开发者来说, 理解浏览器内核的基本机制, 才能开发高性能的web应用
浏览器内核知识
浏览器内核的定义
我们可以初步认为浏览器中负责将表示页面的字符转变为可视化的图像的模块就是浏览器内核.
回到"从输入URL..."的问题
我们将输入URL到远程内容返回之前的阶段略过, 从"Response"开始:
使用Node.js的TCP模块来获取, 远程主机究竟给我们返回了什么:
远程主机响应
HTTP协议
请求报文格式:
- 起始行: [方法] [空格] [请求URL] [空格] [HTTP版本] [换行符]
- 首部: [首部名称] [:] [可选空格] [首部内容] [换行符]
- 首部结束: [换行符]
- 实体
响应报文格式:
- 起始行: [HTTP版本] [空格] [状态码] [空格] [原因短语] [换行符]
- 首部: [首部名称] [:] [可选空格] [首部内容] [换行符]
- 首部结束: [换行符]
- 实体
换行符:
网页内容的组成
- doctype: 提供浏览器html版本信息
- head: html头部
- meta: 元数据信息
- charset: 此特性声明当前文档所使用的字符编码
- http-equiv: 客户端行为, 如渲染模式, 缓存等
- name[keywords]: 搜索引擎使用
- name[description]: 搜索引擎使用
- name[viewport]: 浏览器视口设置
- link
- script: 需要在body前完成加载或运行的脚本
- meta: 元数据信息
- body: html实体
- script: 需要在body解析时加载或运行的脚本
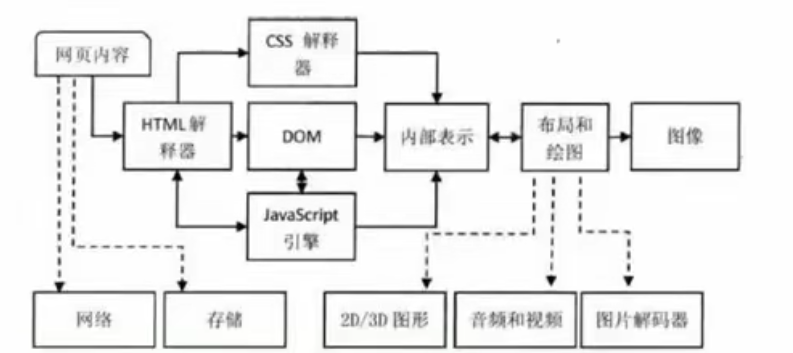
上图表示了渲染引擎的一般渲染过程, 虚线表示该阶段所依赖的外部模块(不属于渲染引擎)
重要组件:
- HTML解释器: 解释HTML文本的解释器, HTML文本 -> DOM树
- CSS解释器: 遇到级联样式时, 需要使用级联样式解释器, 为DOM对象计算出样式信息
- JavaScript引擎: 遇到JS代码时, 需要使用JavaScript解释器, 并使得JS代码调用DOM接口和CSSOM接口的能力
- 布局: 结合CSS, 计算出每个DOM对象的大小位置信息
- 绘图: 将经过布局计算的DOM节点绘制成图像
以上重要组件组成了渲染引擎

几个问题:
- 通过响应的内容, 我们可以到底内容中还存在许多外部资源, 浏览器是如何处理的?
- 著名的优化: "css放在头部, js放在body尾部", 为什么?
- 浏览器在渲染之前或之后还要做那些事情?
- 移动端的浏览器和PC端的浏览器是否相同?
- 不同的外联资源, webkit中有不同的资源加载器, 当浏览器解析到URL地址时, 调用特定的资源加载器, 如果不是特殊资源, 加载过程不会阻碍渲染过程
- 一般来说css资源不会阻碍渲染过程, 但javascript资源在浏览器中, 会阻碍渲染过程的进行, 如果放置在头部, 渲染过程会暂停, 造成"白屏", 但现代浏览器的优化已经做的很好了, 所以当浏览器被阻塞时, 浏览器会开启新的线程继续渲染.
- 渲染之前需要加载资源, 渲染之后再DOM或者CSS变化后, 重新进行计算和重绘操作
- 功能基本相同, 但所运行的操作系统不同, 渲染机制有差异
浏览器内核架构
内核架构
根据上面问题回答我们会发现, webkit仅仅包含渲染功能是不够的, 因为他需要获取网络资源, 支持不同的浏览器, 支持不同的操作系统, 同样还要包含调试工具.
所以我们应该给出一张更全的webkit架构图:
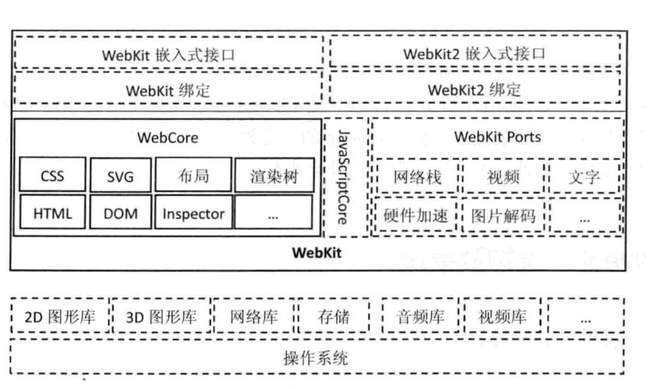
虚线框表示该部分模块在不同浏览器使用webkit的实现是不一样的, 实线框基本是一致的.
Chromium架构
基于webkit内核可以构建浏览器应用, 了解著名的chromium浏览器对我们的web开发者也有很多启发
几个问题:
- 除去webkit内核完成的功能, 浏览器的工作有哪些?
- 进程是什么?
- 进场同步是什么?
- 线程是什么?
- 线程同步是什么?
现代浏览器的工作
- 资源管理
- 多页面管理: 也就是多个标签页的管理
- 插件和扩展: 如flash, 油猴, chrome扩展程序
- 账户和同步
- 安全机制
- 多系统支持
进程和线程
- 进程: 对CPU, 主存, IO设备的抽象, 操作系统对一个正在进行的程序的抽象.
- 线程: 组成进程的执行单元
- 进程通信: 进程间传输数据(交换信息) 信号量
- 线程同步:
进程通讯的方式
线程同步的方式
Chromium的多进程架构
Chromium的模块:
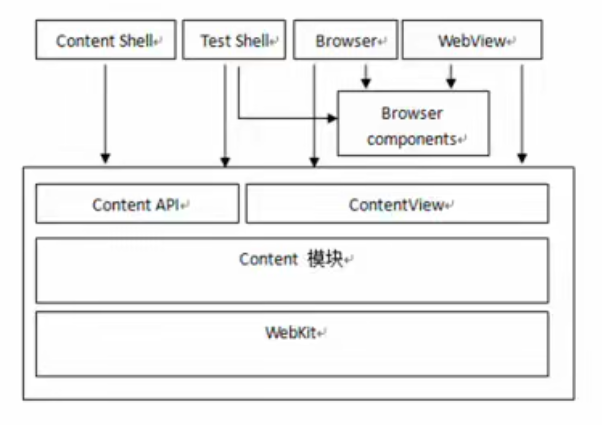
主要进程介绍:
- Browser进程: 主进程, 负责浏览器界面, 页面管理等, 有且只有一个.
- Render进程: 渲染进程.
- NPAPI插件进程
- GPU进程: 当GPU硬件加速打开时才会创建
多进程架构的目的所在:
- 职责分离, 故障范围小.
- 隔离性
- 性能
javascript中的进程和线程
浏览器渲染原理
加载
资源加载机制
资源加载器
分为三类
- 特定资源加载器: 针对每种资源类型的特定加载器, 仅加载某一种资源. 对应设计模式中的单例模式.
- 缓存资源加载器: 与常规的缓存逻辑相同, 特定加载器先通过缓存资源加载器来查找是否有缓存资源, 如果在资源缓存池中存在缓存资源, 则取出以便使用; 若不存在, 发送请求给网络模块.
- 通用资源加载器: 由于加载资源大多属于网络请求, 而网络请求的逻辑是可以被特定资源加载器所共享的, 所以通用资源加载器只负责通过网络获取目标资源的数据, 但不负责进一步解析.
资源缓存
- Page Cache: 页面缓存
- Memory Cache: 内存缓存
- Disk Cache: 磁盘缓存
流程
网络栈
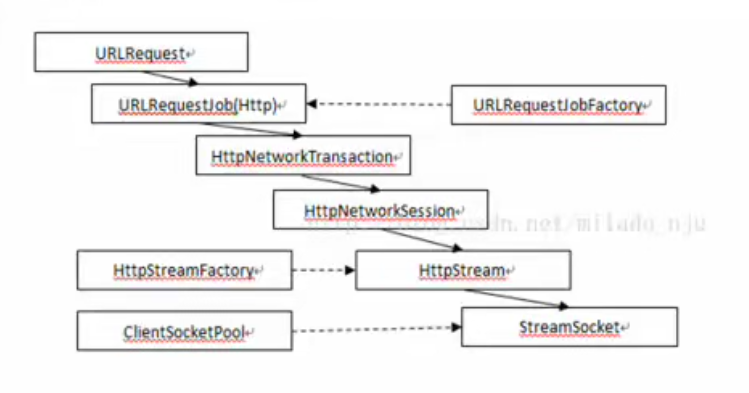
- 确定请求类型, 协议
- 判断是否需要建立网络连接
- 建立HTTP事务
- 建立TCP socket连接
- 套接字连接
预先加载
- DNS预取
- 资源获取
- TCP preconnect
TCP相关
如何提高加载速度
- 合并求情: nginx模块, sprite雪碧图
- 缓存 from cache(memory disk), localstorage, 本地缓存策略, HTTP缓存头(结合业务)
- TCP网络连接优化: TCP调优, HTTP/2, keep-alive
- 硬件: 加大带宽, 使用cdn(对象存储)
- 资源大小: gzip, webp, image压缩, cookie体积(只做身份操作)
- 预加载: 多个cnd域名, dns预取, 异步读取js
性能调优
渲染
HTML解释器
解释过程
- 字节流
- 字符流
- Tokens
- 节点
- DOM树
流程:
- 词法分析
- XSSAuditor
- 语法分析
- 生成DOM树
词法分析
通过HTMLTokenizer来进行词法分析
词法分析的任务是对输入字节流进行逐字扫描, 根据构词规则设别单词和符号, 分词
词法分析器的主要接口是nextToken()函数, 调用者只需要将字符串传入, 就会得到一个词语.
注意, 在这里并不涉及标签类型信息, 这是之后语法分析的工作
语法分析
主要任务是在词法分析的基础上,将单词序列组合成各类语法短语,如“程序”, “语句”,“表达式”
负责根据不同语言的语法规则来分析文档结构,最后构造出解析树。
词法分析器知道如何去除不相关的字符,比如空格和换行