距离上一篇文章,正好两个星期。 这篇文章9月15日 16:30 开始写。 可能几个小时后就写完了。
用一句粗俗的话说, “当你怀孕的时候,别人都知道你怀孕了, 但不知道你被日了多少回 ” ,纪念
这两周的熬夜,熬夜。 因为某些原因,文章发布的有点仓促,本来应该再整理实验和代码比较合适。
文章都是两个主要作用: 对自己的工作总结, 方便自己回顾和分享给有兴趣的朋友。
不说废话了, 进入正题。 本次的课题很简单, 深度神经网络(AI)来预测5日和22日后的走势。 (22日
尚未整理, 不表)。
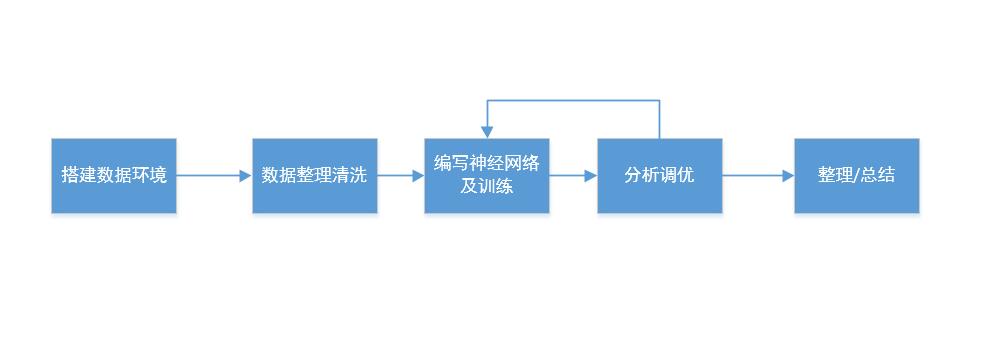
先上个工作流程图, 也基本上是本文章的脉络:
先说金融需求, 我很希望能预测股票5日后的情况或者22日后的情况。如果知道5日后能涨个10%,概率达到70%以上。
我想肯定会很受用。 因此我把5日后的收盘价格,作为我预测(分类)的目标。
在整个工作过程中, 搭建数据环境和数据整理清洗,耗费了我50%以上的时间。 而且还在我有有基本数据的基础上。
搭建数据环境,就是根据我的目标,提出所需的训练数据的需求。 然后整理基础数据,形成相关数据及数据调用的接口。方便我
很快的获得训练数据。 我所需要的数据包括:股票代码,日线数据,分红数据,等其它。 整理后的数据包括各项均线。 细节不表。
数据整理清洗,说一下我的处理:
1. 所有参加训练的数据均不包括分红相关,感觉前复权后复权太复杂,且与实际不符,直接过滤。
2. 数据我只包含2017年1月到7月数据。 有人会说数据太少,且对股市来说周期不全,会直接影响最后的使用。这个等下稍微
再做补充说明。
3. 所有数据训练前做归一化处理, 包括价格,成交量,成交金额,涨幅,均线等。
4. 所有数据训练前,做打乱处理。
5. 数据等量分布
(还有其它处理,想起来再做补充)
只有2017年的数据,我是这么想的, 上半年的基本面基本相同, 1~7月份的情况,应该可以适合 9,10月份。
股票是有周期性的, 快速上涨(疯狂), 和快速下跌,与平时状态是不一样。 所以有意识的分阶段预测有必要性。
自身原因: 机器性能有限,过量的数据训练,时间消耗太大。
当然,全数据(全金融周期)的训练,肯定会进行的。
说一下目标分类:
目标为 5日后的收盘价格, 预测数据是前21日的 o c h l, v ,amout, zf , 均线 等。
数据分为 5类 , 类0, 类1 , 类2, 类3, 类4
标准: ~-10 % , -10 %~-1 %, -1~2 %, 2 %~10 %, 10 %~
应该很好理解吧, 就是5日后收盘价 比今日收盘价低 10%以上为 0类, 如果是10%以上为 4类
接下去就是上主要代码了,发布主要代码。
建立LSTM神经网络:
def buildlstm():
# expected input data shape: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(nUnits, return_sequences=True, input_shape=(timesteps, data_dim)))
model.add(Dropout(0.2))
model.add(LSTM(nUnits, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(nUnits))
# model.add(Dense(128, activation='relu'))
# model.add(Dropout(0.2))
# model.add(Dense(64, activation='relu'))
# model.add(Dropout(0.2))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(5, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
print model.summary()
return model
pass
主流程:
def run():
if (os.path.exists(destfile) == True):
X = pd.read_hdf(destfile, 'data')
y = pd.read_hdf(destfile, 'label')
codedtlist = pd.read_hdf(destfile, 'codedt')
X = np.array(X)
y = np.array(y)
codedtlist = np.array(codedtlist)
else:
X, y, codedtlist = makedata()
df = pd.DataFrame(X)
df.to_hdf(destfile, 'data')
df = pd.DataFrame(y)
df.to_hdf(destfile, 'label')
df = pd.DataFrame(codedtlist)
df.to_hdf(destfile, 'codedt')
print 'read file:'
print codedtlist[:10]
print y[:10]
X, y, codedtlist = dataDoByYsite(X, y, codedtlist)
X, y, codedtlist = dataDaluan(X, y, codedtlist)
print 'ByYsite and Daluan :'
print codedtlist[:10]
print y[:10]
print len(X)
maxLen = len(X)
splen = maxLen * 90 / 100
X_train, X_test = X[:splen], X[splen:]
y_train, y_test = y[:splen], y[splen:]
codedt_train, codedt_test = codedtlist[:splen], codedtlist[splen:]
model = buildlstm()
TrainMode(X_train, y_train, model)
TestMode(X_test, y_test, model, codedt=codedt_test)
model.save_weights('Result/lstm_class5_2017_debug' + '_V1.2' + '.h5')
pass
训练预测前, 我们数据 类4, 是 5657 : 233000, 也就是说,你随机选,大概选 50 个股票会中一个5天内涨 10%的。
很多人想着急看到结果, 想看结果的到文章最后看吧。
下面开始说分析调优, 我认为这是量化交易最重要的工作之一, 另外一个之一就是构建更复杂的神经网络提高 准确率。
第一轮结果,我用全数据训练,达到大概 0.5xxx 的ACC 。 然后我把测试数据和预测数据做了对比,结果概率高达多 80%.
然后我去看数据, 一看,发现有问题了。 因为数据基本集中在 类2, 所以在训练的时候, AI( AI并不AI ), 就很聪明的
往类2 靠, 这样能很快提高准确率。 其实对我们有意义的是类4的预测。
第二轮训练测试, 我把所有分类,整成等量的,再做预测。 结果同样达到 达到大概 0.5xxx 的ACC, 同样能把测试数据和
预测数据做了对比,相似度最高的前20条, 高达90%。 吓了我一跳, 还好我也是见过世面的人, 马上稳定下来查问题。
因为我觉得这么高的成功率,我成神仙了, 或者说AI成神仙了。 所以说这数据是不符合现实的。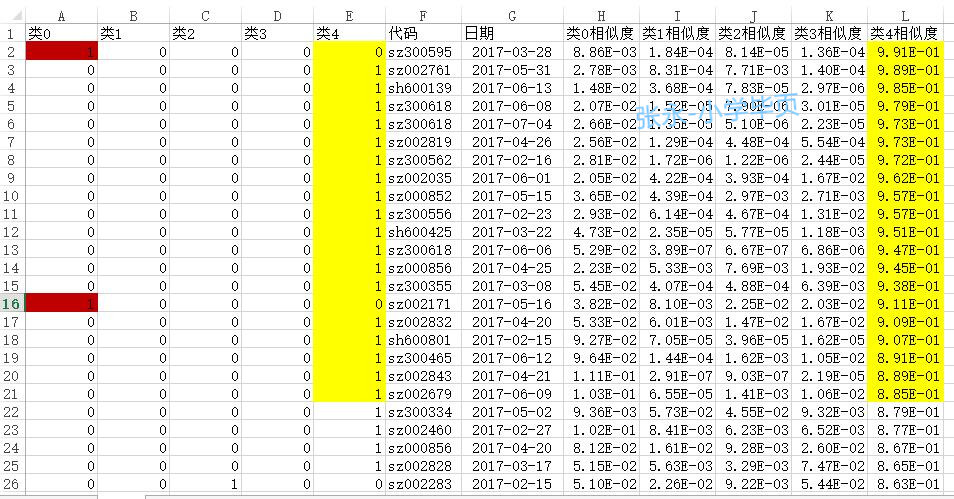
第三轮训练测试, 等量分类训练数据, 全量预测数据。
直接说重点 : 我把中奖率从 2% 提高到了 25%。 也就是 4个股票,其中有1个可以在未来5天内达到 10%。
实际与预测截图:
相似度大于 0.50 分(满分为1分) 准确率统计:

再做精细统计:
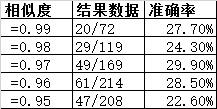
通俗的表达就是, 选相似度大于 95% 的 类4 预测, 就能达到 4个股票 有 1 个股票5天内能达到 10%。
有没价值, 金融领域的朋友可能比较清楚。
为了防范风险, 再做一个风险统计:

说明: 统计这个的目的是, 万一 我不是 4选1 ( 类4), 而是4选3了, 那我就成了另外的4类了。 踩地雷
的概率是多少呢? 这个表就是说明这个情况。
预测仅仅是量化的开始, 后面还有仓控,资金控制等。 一个好的入场会为后续管理提供更大的操作空间。
That is all ! 文章就此结束。
顺便说一下接下想做点什么事情:
1. 预测实盘, 我搭建的环境是一个研究环境, 所以做实盘环境,还得熬夜。(实盘很重要, 是狗是猫,总得拿出来遛遛 )
2. 再研究, 在此数据基础上, 再提升(方法一:提升网络模型, 方法二:根据预测数据 二次删选)
3. 我向往的强化学习
有对 金融程序化 和 深度学习结合有兴趣的可以加群 , 个人群: 杭州程序化交易群 375129936