一、简介
Spark SQL 提供了以下三大功能。
(1) Spark SQL 可以从各种结构化数据源(例如 JSON、Hive、Parquet 等)中读取数据。
(2) Spark SQL 不仅支持在 Spark 程序内使用 SQL 语句进行数据查询,也支持从类似商业智能软件 Tableau 这样的外部工具中通过标准数据库连接器(JDBC/ODBC)连接 SparkSQL 进行查询。
(3) 当在 Spark 程序内使用 Spark SQL 时,Spark SQL 支持 SQL 与常规的 Python/Java/Scala代码高度整合,包括连接 RDD 与 SQL 表、公开的自定义 SQL 函数接口等。这样一来,许多工作都更容易实现了。
二、Spark SQL基本示例

import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.SQLContext
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[4]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val hiveCtx = new HiveContext(sc)
val input = hiveCtx.jsonFile("tweets.json")
input.registerTempTable("tweets")
// hiveCtx.cacheTable("tweets") 缓存表
// input.printSchema() // 输出结构信息
val topTweets = hiveCtx.sql("SELECT user.name,text FROM tweets")
topTweets.collect().foreach(println)
}
}
三、SchemaRDD
读取数据和执行查询都会返回 SchemaRDD。SchemaRDD 和传统数据库中的表的概念类似。从内部机理来看,SchemaRDD 是一个由 Row 对象组成的 RDD,附带包含每列数据类型的结构信息。 Row 对象只是对基本数据类型(如整型和字符串型等)的数组的封装。在 Spark 1.3 版本以后,SchemaRDD 这个名字被改为 DataFrame。SchemaRDD 仍然是 RDD,所以你可以对其应用已有的 RDD 转化操作,比如 map() 和filter() 。
SchemaRDD 可以存储一些基本数据类型,也可以存储由这些类型组成的结构体和数组。


四、缓存
Spark SQL 的缓存机制与 Spark 中的稍有不同。由于我们知道每个列的类型信息,所以Spark 可以更加高效地存储数据。为了确保使用更节约内存的表示方式进行缓存而不是储存整个对象,应当使用专门的 hiveCtx.cacheTable("tableName") 方法。当缓存数据表时,Spark SQL 使用一种列式存储格式在内存中表示数据。这些缓存下来的表只会在驱动器程序的生命周期里保留在内存中,所以如果驱动器进程退出,就需要重新缓存数据。和缓存RDD 时的动机一样,如果想在同样的数据上多次运行任务或查询时,就应把这些数据表缓存起来。
五、读取和存储数据
1、 Apache Hive
当从 Hive 中读取数据时,Spark SQL 支持任何 Hive 支持的存储格式,包括文本文件、RCFiles、ORC、Parquet、Avro,以及 Protocol Buffer。要把 Spark SQL 连接到已经部署好的 Hive 上,你需要提供一份 Hive 配置。你只需要把你的 hive-site.xml 文件复制到 Spark 的 ./conf/ 目录下即可。如果你只是想探索一下 Spark SQL而没有配置 hive-site.xml 文件,那么 Spark SQL 则会使用本地的 Hive 元数据仓,并且同样可以轻松地将数据读取到 Hive 表中进行查询。
// 使用 Scala 从 Hive 读取
val hiveCtx = new HiveContext(sc)
val rows = hiveCtx.sql("SELECT key, value FROM mytable")
val keys = rows.map(row => row.getInt(0))
2、Parquet
Parquet(http://parquet.apache.org/)是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。Parquet 格式经常在 Hadoop 生态圈中被使用,它也支持 Spark SQL 的全部数据类型。Spark SQL 提供了直接读取和存储 Parquet 格式文件的方法。可以通过 HiveContext.parquetFile 或者 SQLContext.parquetFile 来读取数据。
3、JSON
要读取 JSON 数据,只要调用 hiveCtx 中的 jsonFile() 方法即可。如果你想获得从数据中推断出来的结构信息,可以在生成的 SchemaRDD 上调用printSchema 方法。
4、基于RDD
除了读取数据,也可以基于 RDD 创建 DataFrame。
/**SQLContext 创建 DataFrame **/
def createDtaFrame(sparkCtx:SparkContext,sqlCtx:SQLContext):Unit = {
val rowRDD = sparkCtx.textFile("D://TxtData/studentInfo.txt").map(_.split(",")).map(p => Row(p(0),p(1).toInt,p(2)))
val schema = StructType(
Seq(
StructField("name",StringType,true),
StructField("age",IntegerType,true),
StructField("studentNo",StringType,true)
)
)
val dataDF = sqlCtx.createDataFrame(rowRDD,schema)
//df注册到内存表
dataDF.registerTempTable("Student")
val result = sqlCtx.sql("select * from Student")
result.show()
// dataDF.select("name").show()
// dataDF.filter(dataDF("age") <14).show()
// dataDF.where("age <> ''").show()
}
5、Spark SQL UDF
用户自定义函数,也叫 UDF,可以让我们使用 Python/Java/Scala 注册自定义函数,并在 SQL中调用。这种方法很常用,通常用来给机构内的 SQL 用户们提供高级功能支持,这样这些用户就可以直接调用注册的函数而无需自己去通过编程来实现了。在 Spark SQL 中,编写UDF 尤为简单。Spark SQL 不仅有自己的 UDF 接口,也支持已有的 Apache Hive UDF。
// 写一个求字符串长度的UDF 原书代码会报错,查阅官方文档得知
hiveCtx.udf.register("strLenScala", (_: String).length)
val tweetLength = hiveCtx.sql("SELECT strLenScala('tweet') FROM tweets LIMIT 10")
注意:因为Spark版本的原因,原书的代码会报错,有一个好的解决方式,就是查阅官方文档。

六、Spark SQL性能
Spark SQL 提供的高级查询语言及附加的类型信息可以使 SparkSQL 数据查询更加高效。
Spark SQL 的性能调优选项如下表所示
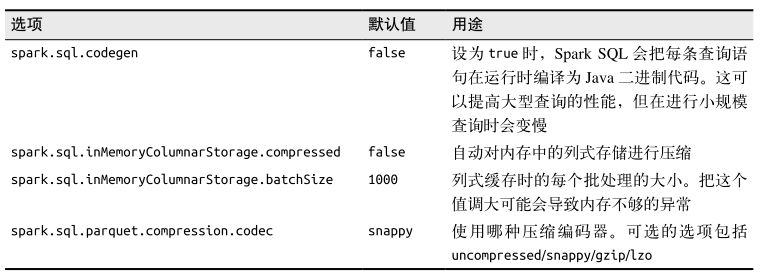
在一个传统的 Spark SQL 应用中,可以在 Spark 配置中设置这些 Spark 属性。
// 在 Scala 中打开 codegen 选项的代码
conf.set("spark.sql.codegen", "true")
这篇博文主要来自《Spark快速大数据分析》这本书里面的第九章,内容有删减,还有本书的一些代码的实验结果。还要注意一点,在以后的学习中要养成查阅官方文档的习惯。