初出茅庐----数据库的学习应用
一、SQList数据库的学习笔记
python3环境下,python自带SQList库,无需下载即可使用
1.数据库的使用流程

2.数据库的操作
(1)Connection对象
| 函数 | 描述 |
| sqlite3.Connection.execute() | 执行SQL语句 |
| sqlite3.Connection.cursor() | 返回游标对象 |
| sqlite3.Connection.commit() | 提交事务 |
| sqlite3.Connection.rollback() | 回滚事务 |
| sqlite3.Connection.close() | 关闭连接 |
(2)Cursor对象
| 函数 | 描述 |
| close(...) | 关闭游标 |
| execute(...) | 执行SQL语句 |
| executemany(...) | 重复执行多次SQL语句 |
| executescript(...) | 一次执行多条SQL语句 |
| fetchall(...) | 从结果集中返回所有行记录 |
| fetchmany(...) | 从结果集中返回多行记录 |
| fetchone(...) | 从结果集中返回一行记录 |
3.尝试使用
1 import sqlite3 #导入模块 2 def sql(): 3 connection=sqlite3.connect('example.db')#连接数据库 4 c=connection.cursor() 5 #创建表 6 c.execute('''CREATE TABLE t1 (date text, trans text, symbol text, qty real, price real)''') 7 #插入一条记录 8 c.execute("INSERT INTO t1 VALUES ('2006-01-05','BUY', 'RHAT', 100, 35.14)") 9 10 connection.commit()#提交当前事务,保存数据 11 for row in c.execute('SELECT * FROM stocks ORDER BY price'):#查找数据 12 print(row) 13 14 connection.close() 15 16 sql()
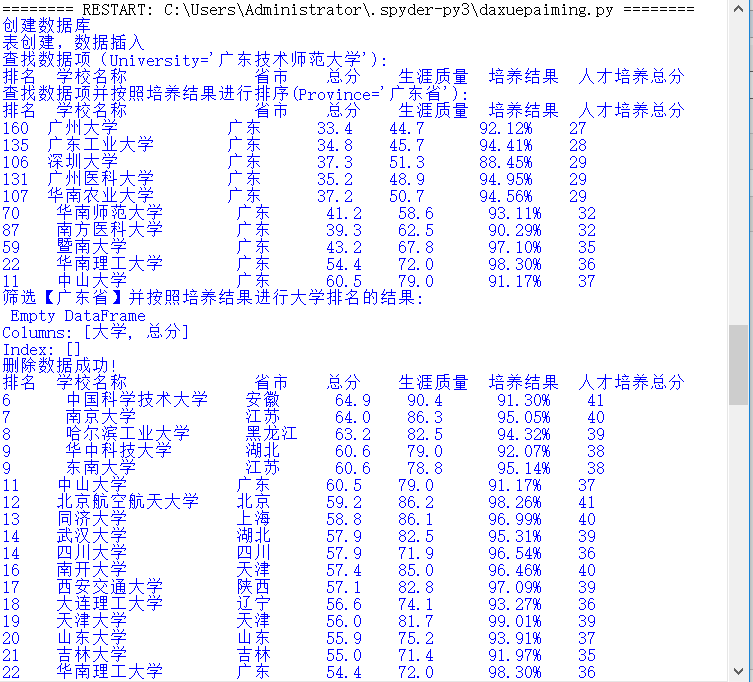
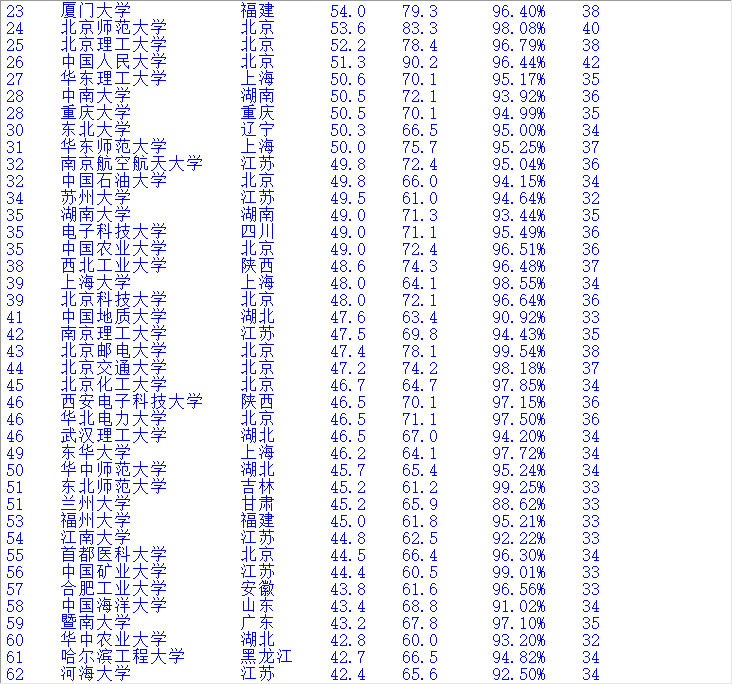
结果如图所示

二、爬取大学排名
代码实现如下
1 # -*- coding: utf-8 -*- 2 """ 3 @author: xiayiLL 4 """ 5 6 import sqlite3 7 from pandas import DataFrame 8 class function: 9 def __init__(s,dbName,tableName,data,e_columns,c_columns,Read_All=True): 10 s.dbName=dbName 11 s.tableName=tableName 12 s.data=data 13 s.e_columns=e_columns 14 s.c_columns=c_columns 15 s.Read_All=Read_All 16 17 def creattable(s): 18 connect=sqlite3.connect(s.dbName) 19 connect.execute("CREATE TABLE {}({})".format(s.tableName,s.e_columns)) 20 connect.commit() 21 connect.close() 22 23 def destroytable(s): 24 connect=sqlite3.connect(s.dbName) 25 connect.execute("DROP TABLE {}".format(s.tableName)) 26 connect.commit() 27 connect.close() 28 29 def getdata(s): 30 connect=sqlite3.connect(s.dbName) 31 cursor=connect.cursor() 32 cursor.execute("SELECT * FROM {}".format(s.tableName)) 33 dataList=cursor.fetchall() 34 connect.close() 35 return dataList 36 37 def inserDataS(s): 38 connect=sqlite3.connect(s.dbName) 39 connect.executemany("INSERT INTO {} VALUES(?,?,?,?,?,?,?)".format(s.tableName), s.data) 40 connect.commit() 41 connect.close() 42 43 def searchData(s,conditions,ifprint=True): 44 connect=sqlite3.connect(s.dbName) 45 cursor=connect.cursor() 46 cursor.execute("SELECT * FROM {} WHERE {}".format(s.tableName, conditions)) 47 data=cursor.fetchall() 48 cursor.close() 49 connect.close() 50 if ifprint: 51 s.printData(data) 52 return data 53 54 def deleteData(s,conditions): 55 connect=sqlite3.connect(s.dbName) 56 connect.execute("DELETE FROM {} WHERE {}".format(s.tableName,conditions)) 57 connect.commit() 58 connect.close() 59 60 def printData(s,data): 61 print("{1:{0}^3}{2:{0}<11}{3:{0}<4}{4:{0}<4}{5:{0}<5}{6:{0}<5}{7:{0}^5}".format(chr(12288),*s.c_columns)) 62 for i in range(len(data)): 63 print("{1:{0}<4.0f}{2:{0}<10}{3:{0}<5}{4:{0}<6}{5:{0}<7}{6:{0}<8}{7:{0}<7.0f}".format(chr(12288),*data[i])) 64 65 def run(s): 66 try: 67 s.creattable() 68 print("创建数据库") 69 s.inserDataS() 70 print("表创建,数据插入") 71 except Exception as e: 72 print("Error: ", e) 73 print("数据库已存在") 74 if s.Read_All: 75 s.printData(s.getdata()) 76 77 def get_Data(f_Name): 78 data=[] 79 f=open(f_Name,'r',encoding='utf-8') 80 for line in f.readlines(): 81 line=line.replace(' ','') 82 line=line.split(',') 83 for i in range(len(line)): 84 try: 85 if line[i]=='': 86 line[i]='0' 87 line[i]=eval(line[i]) 88 except: 89 continue 90 data.append(tuple(line)) 91 e_columns='Rank real,University text,Province text,Grade real,SourseQuality real,TrainingResult real,ResearchScale real' 92 c_columns=["排名","学校名称","省市","总分","生涯质量","培养结果","人才培养总分"] 93 return data[i:],e_columns,c_columns 94 95 def main(): 96 f_Name="E:\daxuepaiming_data.csv" 97 data,e_columns,c_columns=get_Data(f_Name) 98 dbName="E://university.db" 99 tableName="university" 100 SQL=function(dbName,tableName,data,e_columns,c_columns,False) 101 SQL.run() 102 print("查找数据项(University='广东技术师范大学'):") 103 SQL.searchData("University='广东技术师范大学'",True) 104 print("查找数据项并按照培养结果进行排序(Province='广东省'):") 105 SQL.searchData("Province='广东'ORDER BY ResearchScale",True) 106 Weight=[0.35,0.2,0.1,0.1,0.1,0.1,0.05] 107 value,sum=[],0 108 sample=SQL.searchData("Province='广东省'",False) 109 for i in range(len(sample)): 110 for j in range(len(Weight)): 111 sum+=sample[i][4+j]*Weight[j] 112 value.append(sum) 113 sum=0 114 university=[university[i] for university in sample] 115 uv,tmp=[],[] 116 for i in range(len(university)): 117 tmp.append(university[i]) 118 tmp.append(value(i)) 119 uv.append(tmp) 120 tmp=[] 121 df=DataFrame(uv,columns=list(("大学","总分"))) 122 df=df.sort_values('总分') 123 df.index=[i for i in range(1,len(uv)+1)] 124 print("筛选【广东省】并按照培养结果进行大学排名的结果: ",df) 125 SQL.deleteData("Province='北京市'") 126 SQL.deleteData("Province='广东省'") 127 SQL.deleteData("Province='山东省'") 128 SQL.deleteData("Province='山西省'") 129 SQL.deleteData("Province='江西省'") 130 SQL.deleteData("Province='河南省'") 131 print("删除数据成功!") 132 SQL.printData(SQL.getdata()) 133 SQL.destroytable() 134 print("表删除成功!") 135 136 main() 137 138
结果如图所示