全球各种大数据技术涌现的今天,为了充分利用大量数据获得竞争优势,企业需要高性能的数据分析平台,可靠并及时地提供对海量数据的分析见解。对于数据驱动型企业,在海量数据上交互式分析的能力是非常重要的能力之一。本测试侧重在多维分析场景,对比Spark SQL 与 Kyligence 产品在大规模数据集上的查询响应的性能差异和特点。
测试产品介绍
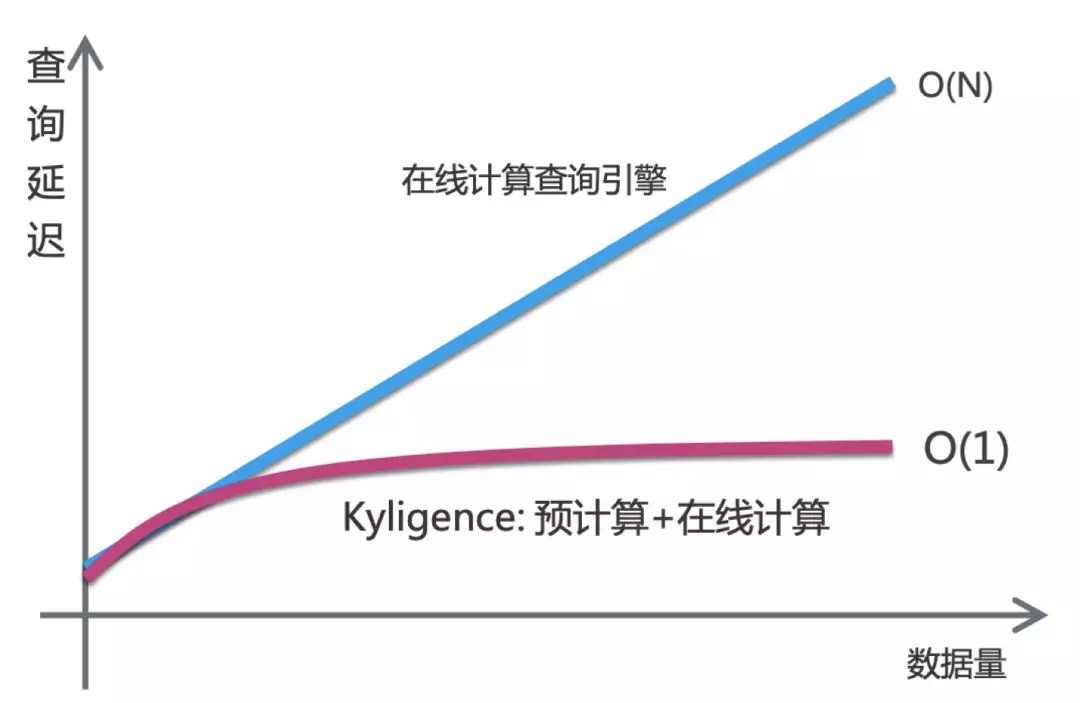
Spark SQL 本质上是基于 DAG 的 MPP,提供 SQL 或类 SQL 的查询接口,通过将 SQL 查询请求转换成逻辑计划、物理执行,然后进行分布式的执行。在查询执行的过程中,充分利用完全基于内存的并行计算做到低延迟查询(通常是秒级到分钟级,数据量越大查询响应越慢)。
Kyligence Enterprise 是企业级智能大数据OLAP,基本思路是对数据作多维索引,查询时只扫描索引而不访问原始数据达到提速。作为充分利用了预计算技术的产品,Kyligence Enterprise 擅长提供多维分析的亚秒级响应能力。特别是在数据量呈倍数增长时,查询性能依然具有很显著的优势。
 本次测试的产品是Kyligence Enterprise 4.0,对照的大数据分析引擎Spark SQL 2.4.1。
本次测试的产品是Kyligence Enterprise 4.0,对照的大数据分析引擎Spark SQL 2.4.1。
确定测试基准
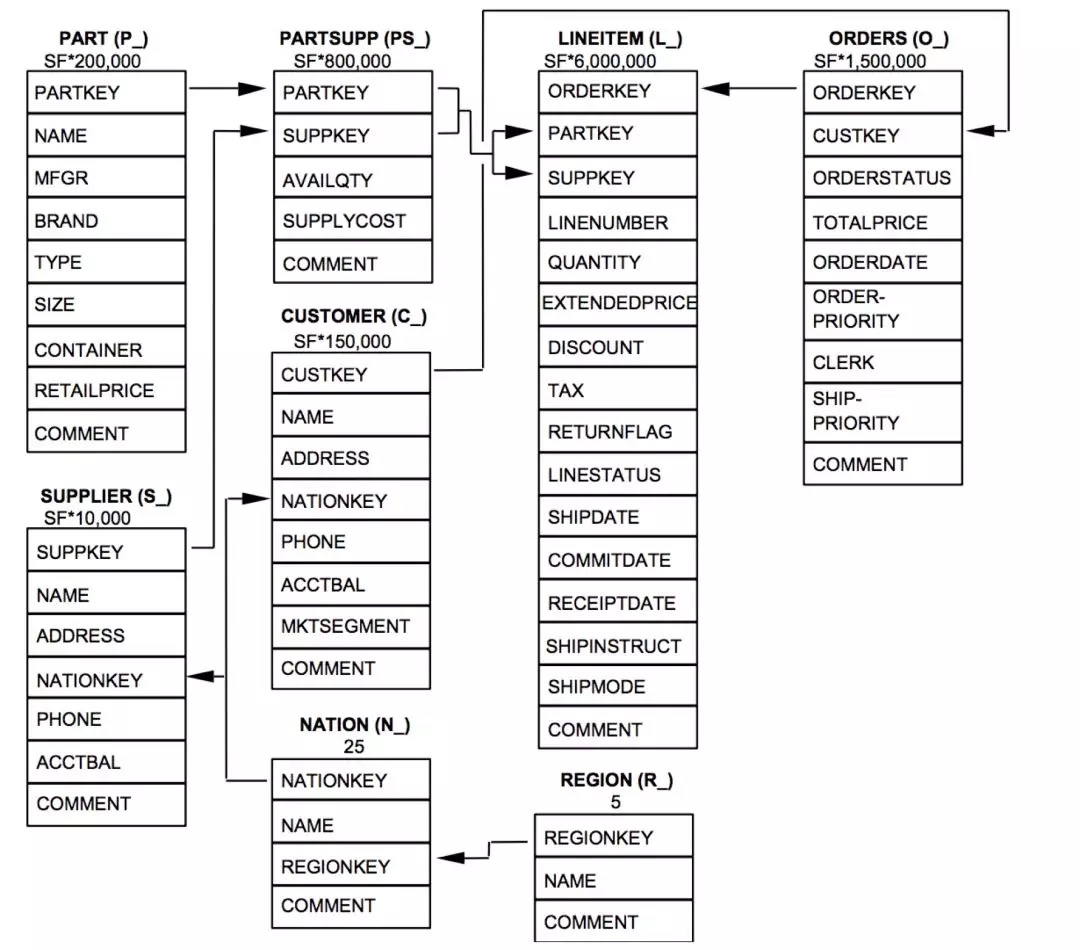
在测试基准的选择上,我们考虑了实际用户的分析场景和查询特征,最终决定根据TPC-H基准进行测试。TPC-H是一个抽象了商品销售场景的决策支持系统测试基准,它定义了8张表、22条查询。测试查询普遍比较复杂,良好地代表了广泛的业务场景中,最常见的分析主题,比如定价和促销分析、供应流量和销售渠道分析、营收和利润分析、客户满意度分析、市场份额分析等。
- 查询集中的Query 1,总结了已经开票的、寄出的、退回的业务交易量。

- 查询Query 3,分析了具有最高价值的n个未发货交易单。

- 查询Query 4,确定了订单排序系统的工作情况,并评估了客户满意度。

更多查询和数据集的信息,可以了解TCP-HBenchmark标准。
准备测试数据和环境
我们使用TPC-H数据工具生成了不同规模的测试数据集,在20台物理机中使用一个资源队列进行测试。
测试查询前,KyligenceEnterprise产品通过预计算生成了不同大小的 TPC-H 数据文件,以 parquet 格式存储在安装节点的 HDFS 上供查询测试使用。每条查询都执行了多次,最终取其平均值作为实验结果。整个测试过程中,关闭了KyligenceEnterprise 4.0 的查询缓存机制。
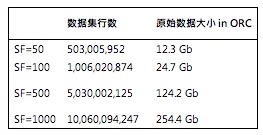
数据集
以下为每个测试数据集中,各个表的行数。

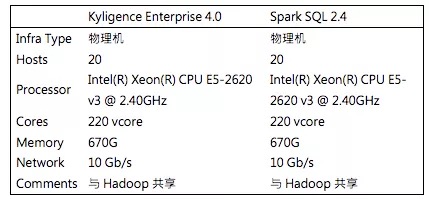
硬件环境
测试集群的硬件配置。
测试结果和解读
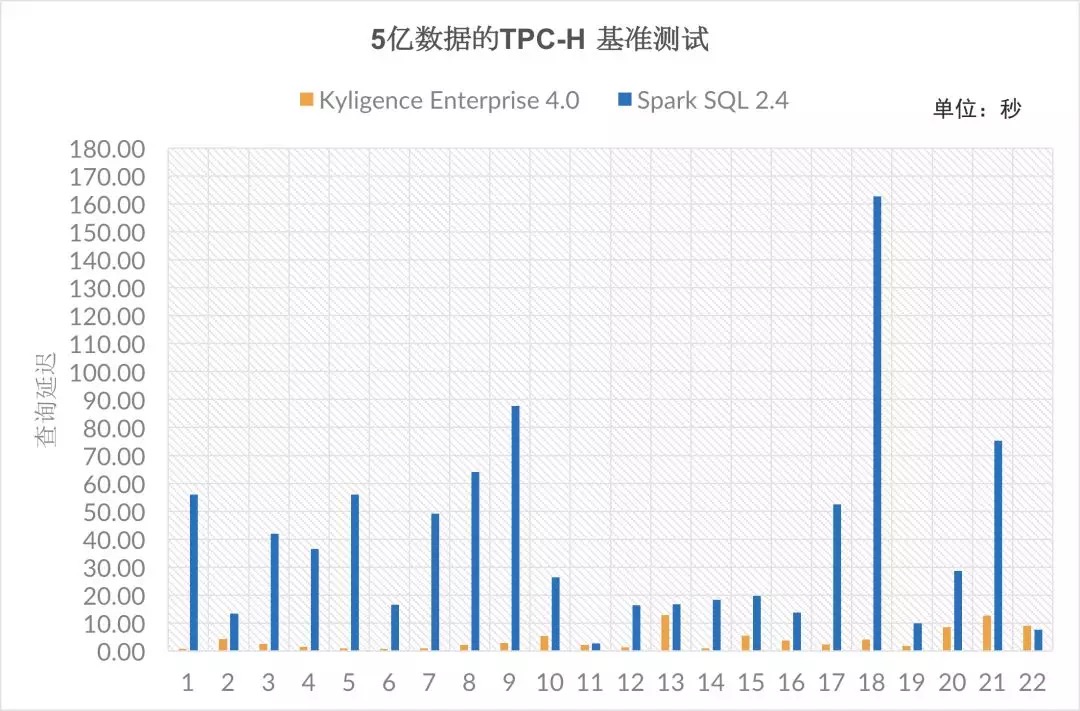
在5亿数据的TPC-H 数据集上,Kyligence Enterprise 4.0的查询性能普遍优于Spark SQL 2.4。22条测试查询中,Kyligence 产品支持60% 查询在3秒以内返回结果,90% 查询可以在10秒以内返回结果,最大查询延迟也只有12.81秒。这些数据反映了,在亿级大数据上, Kyligence产品能够支持秒级的的交互式分析场景。
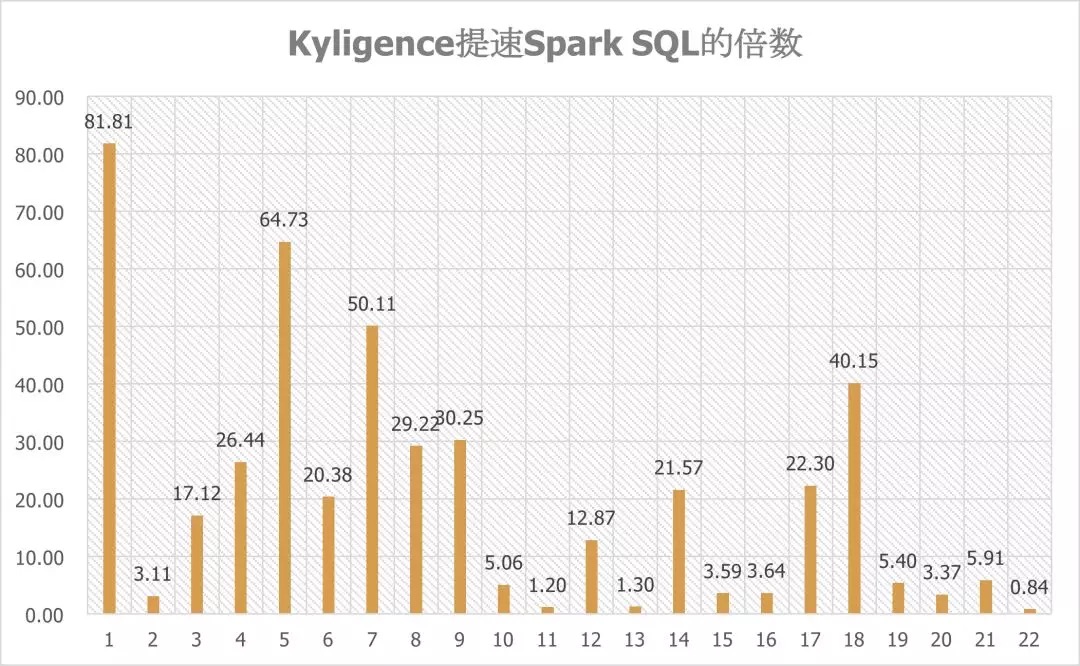
对比来看,Kyligence Enterprise 4.0 的查询性能明显优于 Spark SQL 2.4,其中有55% 的查询提升在10倍以上,96% 查询有提升 (query 22稍慢于Spark SQL 2.4,但性能相差不足1秒),性能优势非常明显,单条查询的性能最大提升81.81倍(query 1);单条查询时间最多缩短150秒(query 18)。
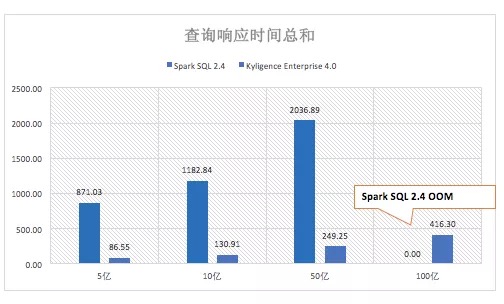
当数据集继续增加到 10亿、50亿、100亿时,即使集群资源不扩充,Kyligence Enterprise 4.0的查询延迟的总时间相对平稳。面对数据量倍数增长到100亿时,Spark SQL 作为在内存中完成数据中间处理过程的分析引擎,需要的资源也需要相应增长,否则就如图展现出由于内存资源不足导致查询报错。
结论和展望
通过本次TPC-H 查询性能的基准测试,我们可以得出Kyligence产品在多维分析场景下更有性能优势:
- 在5亿数据集上, Kyligence Enterprise4.0的查询性能远远优于Spark SQL 2.4。测试的22条查询中,60% 查询可以在3秒以内返回结果,90%查询可以在10秒以内返回结果,平均查询性能为Spark SQL2.4的24.47倍。
- 当数据集继续增加到 10亿、50亿、100亿时,即使集群资源不扩充,KyligenceEnterprise 4.0的查询总延迟时间相对平稳,平均每条查询的延迟时间保持在秒级。
根据上述结论,我们容易看出 Kyligence 产品非常擅长满足海量数据上的多维分析的场景,并且具有交互式和高性价比的特点。当企业的信息生态系统中数据持续增长时,选择 Kyligence 产品更是确保了技术投入的持续可用,不会因为数据量增长而导致 TCO 不断增长。SparkSQL作为 Spark 的一个处理结构化数据的程序模块,更适合抽取部分数据、周期性的转换数据,对部分数据进行灵活的简单分析。
转载自:https://kyligence.io/zh/blog/kyligence-vs-spark-sql/