循环神经网络
循环神经网络或RNN是一类用于处理序列数据的神经网络。就像卷积网络是专门用于处理网格化数据的神经网络。
神经网络中的参数共享
参数共享可以使得模型能够拓展到不同形式的样本(序列数据中指不同长度的样本)并进行泛化。
在处理网格化数据时(例如图像问题),卷积神经网络就是采用了参数共享的思想(卷积核),不但大大减少了参数量,而且提升了网络性能。在处理序列数据时,例如时延神经网络中,它在一维时间序列上使用卷积,每个时间步使用相同的卷积核。
循环神经网络以不同方式共享参数,输出的每一项是前一项的函数,输出的每一项对先前的输出应用相同的更新规则而产生。
循环神经网络的设计模式
循环神经网络中一些重要的设计模式包括以下几种:
1、每个时间步都有输出,并且隐藏单元之间有循环连接的循环网络
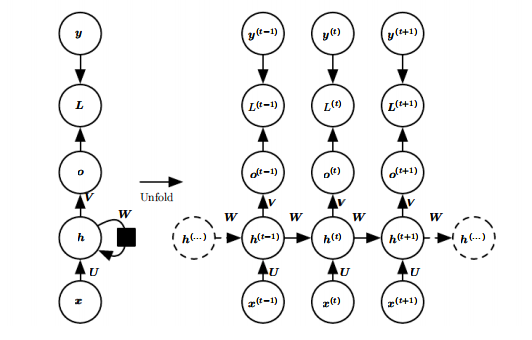
隐藏到隐藏的循环连接由权重矩阵 W 参数化。这里是当前时间步和上一时间步之间的信息传递。
输入到隐藏的循环连接由权重矩阵 U 参数化。这里是当前时间步的外部信号(外部输入)到隐藏单元(隐藏层的信号)的转换。
用公式来描述就是:
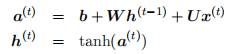
隐藏到输出的循环连接由权重矩阵 V 参数化。这里是当前时间步的隐藏单元到输出的转换。
用公式来描述就是:

损失 L 衡量输出 o 和训练目标 y 的距离,不同问题在一步采用的方式可能并不相同。
2、每个时间步都产生一个输出,只有当前时刻的输出到下个时刻的隐藏单元之间有循环连接的循环网络
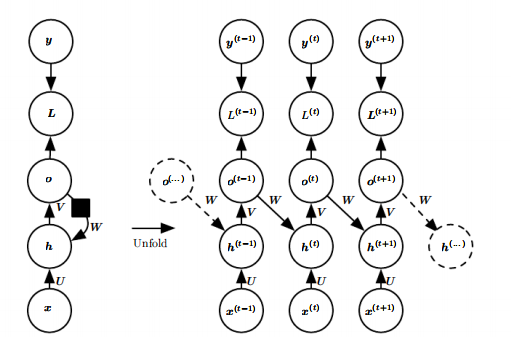
对比上图的结构,上图是将过去的隐藏表示 h 传播到未来,该图中是将输出值 o 传播到未来。o 可能会缺乏过去的重要信息,除非它是高维的且内容丰富。这种结构的RNN没有上个结构那么强大,但他更容易训练,因为每个时间步可以和其他时间步分离训练。消除隐藏到隐藏的循环的优点在于,任何基于比较时刻t的预测和时刻t的训练目标的损失函数中的时间步都解耦了。
时间步解耦:
第一种隐藏到隐藏的循环连接,我们在计算时刻t的损失函数时,需要用到h(t-1),即计算当前时刻t的损失必须先计算前一时刻的h,这使得隐藏单元之间存在循环的网络不能并行化,只能一前一后的计算,虽然这种结构更强大,但它的计算代价很大。
第二种由输出到隐藏的循环连接的模型可以通过导师驱动过程进行训练。导师驱动过程适用于输出与下一时间步的隐藏之间存在循环连接的RNN,在训练的时候我们不再是将输出 o 反馈到 h,而是将 已知的正确值y(label)反馈给 h,如图所示:
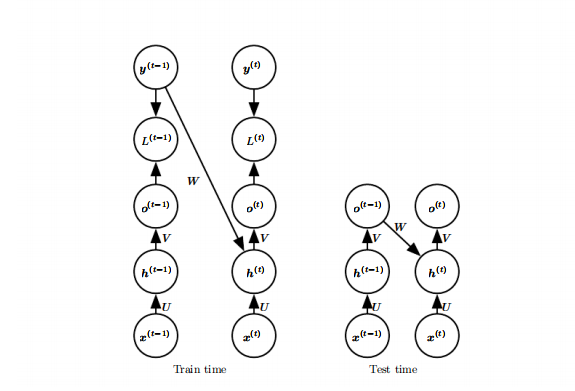
左图是训练过程,在时刻 t 接收时刻 t-1 的真实值y(t)作为输入。参考其他文章,解释的是我们的 o 其实就是拟合真实值 y 的,直接用 y 代替 o 作为输入,y是直接知道的,这样的话我们计算t时刻就不再依赖于t-1时刻的计算。
右图是测试过程,当模型部署好之后真实值 y 往往是未知的,在这种情况下还是用模型的输出 o 来近似真实值 y,并反馈给h。
模型中存在输出到隐藏的循环连接就可以使用导师驱动过程。
模型中存在隐藏到隐藏的循环连接就需要使用BPTT。
模型中同时存在上面两种结构就可以同时使用导师驱动过程和BPTT。
如果测试的时候采用的是右图的结构,即网络的输出反馈作为输入,只使用导师驱动过程就会产生问题,应当采用一些策略同时使用导师驱动过程和普通的(网络的输出反馈作为输入)的过程进行训练。
3、隐藏单元之间存在循环连接,但读取整个序列之后产生单个输出的循环网络

这样的网络可以用于概括序列并产生进一步处理的固定大小的表示。在结束处可能存在目标(如此处所示)【存在目标的意思可能就是计算损失的那部分】,或者通过更下游模块的反向传播来获得输出 o 上的梯度。
计算循环神经网络的梯度
通过时间反向传播(back-propagation through time,BPTT)。
RNN模型参数是U,W,V,b,c。这些在序列的各个位置是共享的,反向传播时每个时间步我们更新的是相同的参数。
首先最终的损失 (L) 为:
所有时刻的损失累积起来对应模型总的损失。其中V和c的梯度比较容易计算:
W,U,b的计算较为复杂,原因是上面提到过的公式:
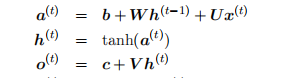
损失函数中包含的有关(h^{(t)})的部分其实是包含时间步的输出(o^{(t)})和下一时间步的(h^{(t+1)})的两部分。
定义时间步t的隐藏状态的梯度为:
从(delta^{(t+1)})递推(delta^{(t)}) 。
对于(delta^{( au)}),这里指的是最后一个时间步,它后面没有(h^{( au+1)}),所以它的梯度只和(o^{( au)})有关:
根据(delta^{(t)}),可以计算(W,U,b):
双向RNN
前面介绍的循环神经网络,在某时刻t的状态只能从过去的序列(x^{(1)}),...,(x^{(t-1)})以及当前的输入(x^{(t)})捕获信息。或者前面提及的从过去的y值(真实值)影响当前状态。但是在很多应用中,我们要输出的(y^{(t)})的预测可能依赖于整个输入序列,双向循环神经网络(双向RNN)就是为满足这种需求发明的。它在手写识别、语音识别、生物信息学等方面的取得广泛应用。
双向RNN结合时间上从序列起点开始移动的RNN和另一个时间上的从序列末尾开始移动的RNN。典型的双向RNN结构如下图所示:
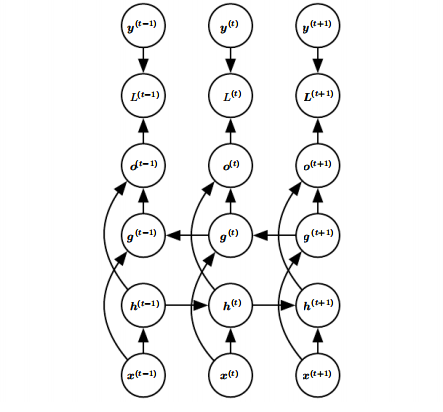
图中循环(g)的结构和循环(h)的结构只是方向不同。循环(g)在时间上向前传播信息,循环(h)在时间上向后传播信息。输出单元(o^{(t)})可以同时接受过去和未来的信息。
深度循环网络
多数RNN中的计算可以分解成三块参数及其相关的变换(W、U、V):
(1) 从输入到隐藏状态
(2) 从前一隐藏状态到下一个隐藏状态
(3) 从隐藏状态到输出
下图展示了三种将RNN加深的方式:
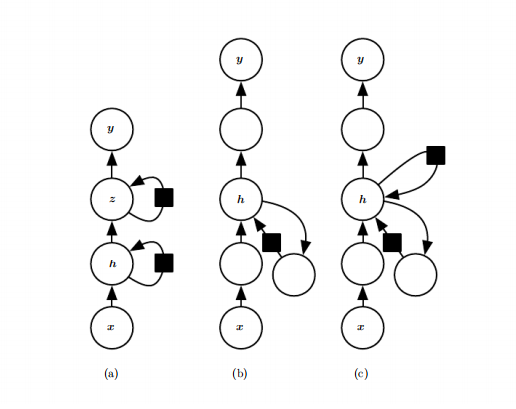
(a) a的结构就是视频中提到的深度RNN,如下图
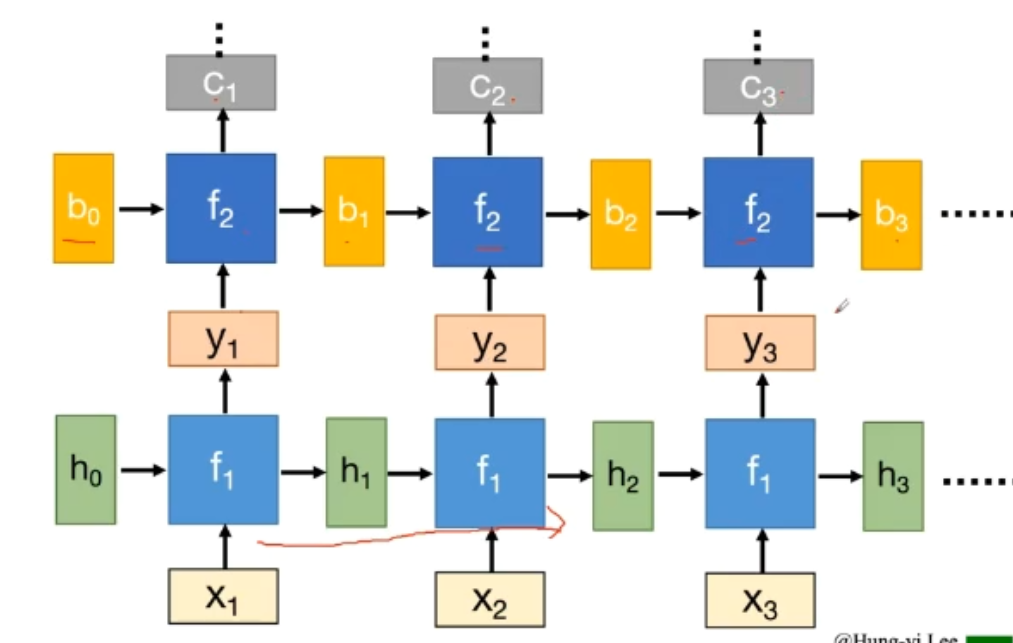
它相当于是有两层隐藏状态,可以认为这种结构中较低的层起到将原始输入转化为对更高层的隐藏状态更合适表示的作用。
(b) b的结构是在上述三个模块中各自添加一个MLP,MLP可以是深层的。可以看到图中就是在输入到隐藏、前一隐藏状态到下一个隐藏、隐藏状态到输出之间加了一个圆圈(MLP,多层感知机)。根据书中描述,从前一隐藏状态到下一个隐藏状态这一模块,应该是每两个时间步的隐藏状态之间都添加一个MLP。
(c) 增加深度可能会因为优化困难而损害学习效果(例如梯度弥散问题),c中加入了跳跃连接,来缓解因为增加深度而造成的不同时间步变量之间的最短路径增大问题(有点残差的感觉)。
长短期记忆单元(long short-term memory,LSTM)
是短期记忆单元,相比于普通RNN没有记忆功能来说,它的记忆算是长的,故命名为长短期记忆单元。
通过引入自循环的巧妙构思,以产生梯度长时间持续流动的路径是初始长短期记忆模型的核心贡献。其中一个关键扩展是使自循环的权重视上下文而定,而不是固定的。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示:
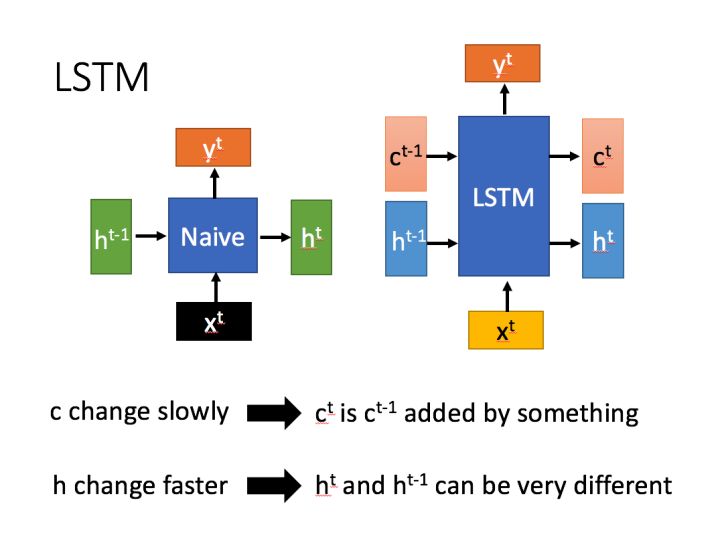
RNN只有一个传递状态(h^{t}),LSTM有两个传输状态,(c^{t})和(h^{t})。
LSTM单元的工作流程如图所示:
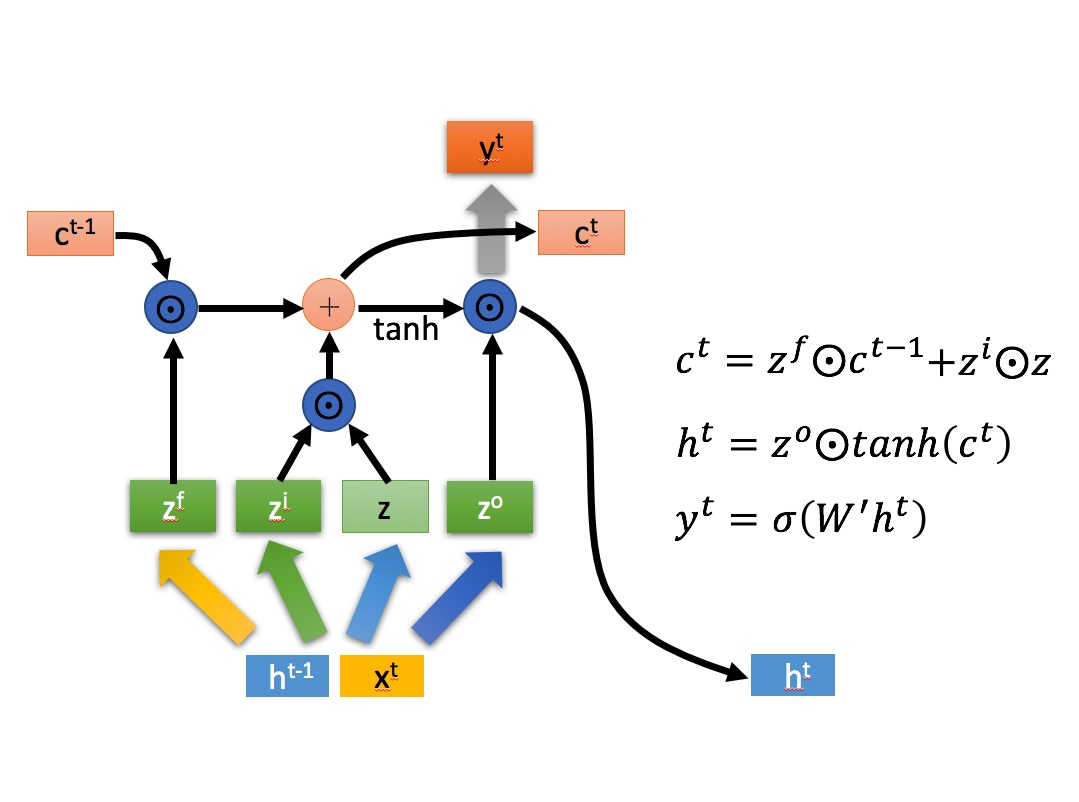
图中  是点乘,(+)就是矩阵相加。
是点乘,(+)就是矩阵相加。
LSTM块使用当前输入(s^{t})和上一个LSTM传来的(h^{t-1})组合得到四个状态:
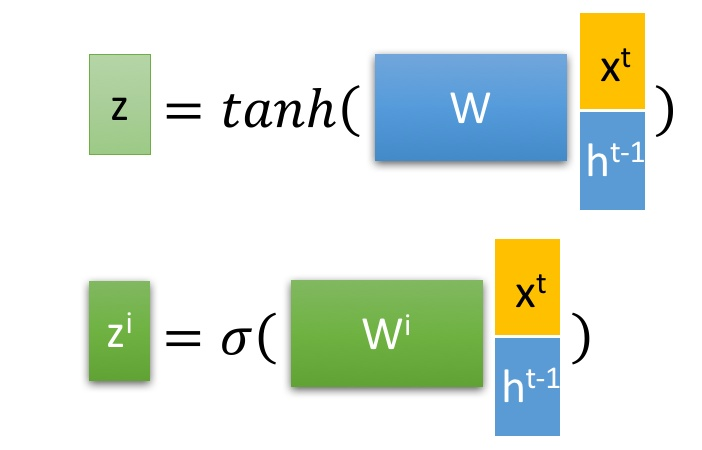
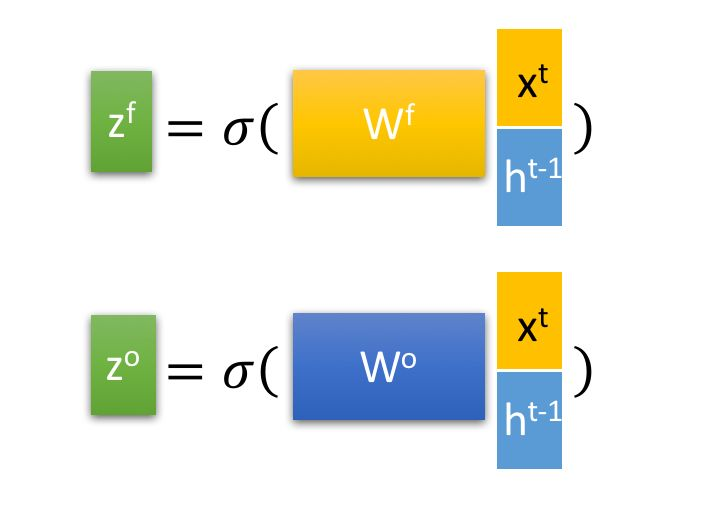
(z^{i})、(z^{f})、(z^{o})经过各自对应的U、W、b变换后再通过sigmoid函数得到一个0-1之间的值,作为一种门控状态,(z)是将其做为输入数据,而不是门控信号,使用tanh。LSTM单元工作流程如上所属,LSTM网络中LSTM单元彼此循环连接,代替一般循环网络中的普通隐藏单元。
门控循环单元(GRU)
GRU的输入输出结构和普通的RNN是一样的:
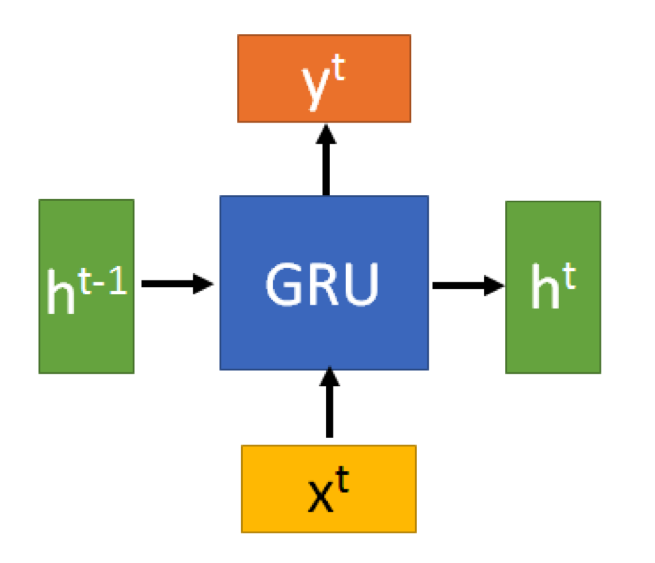
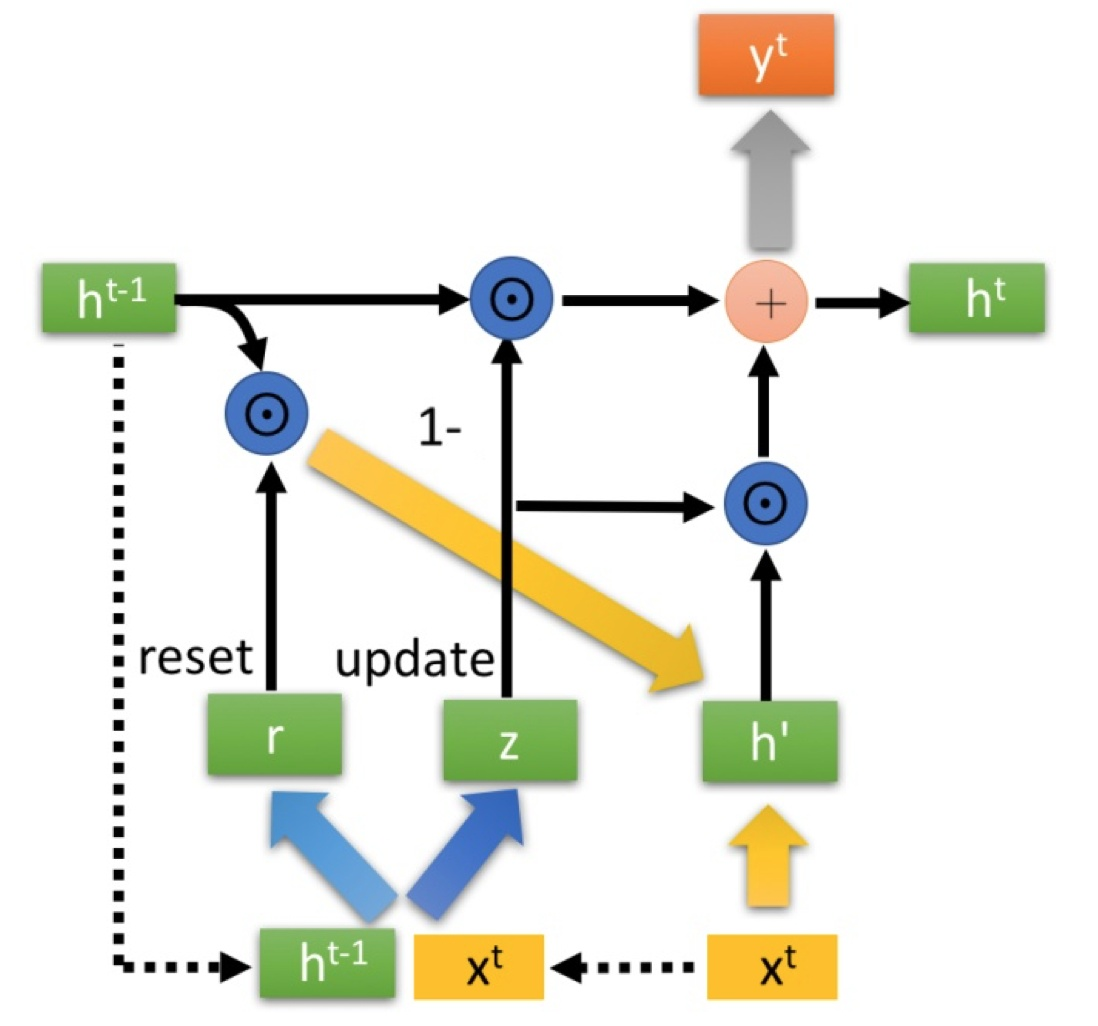
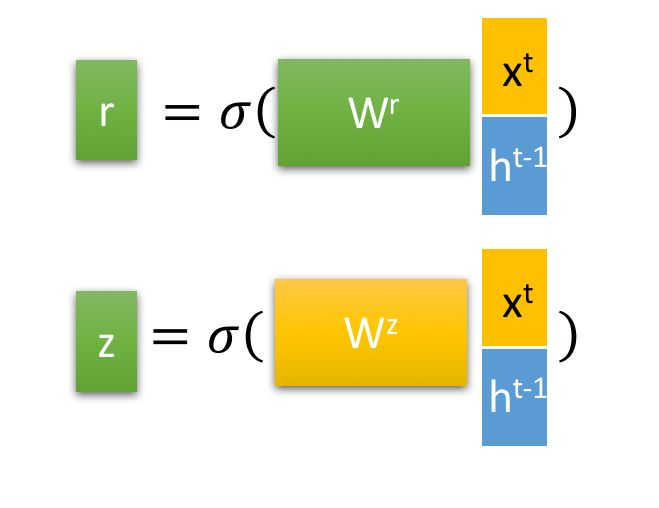
其中 (r) 复位门(reset gate), (x) 为更新门(update gate)
得到r、z后首先使用 r 得到复位之后的数据 ({h^{t-1}}'=h^{t-1}odot r),再将 ({h^{t-1}}')和(x^{t})进行组合得到(h^{'})
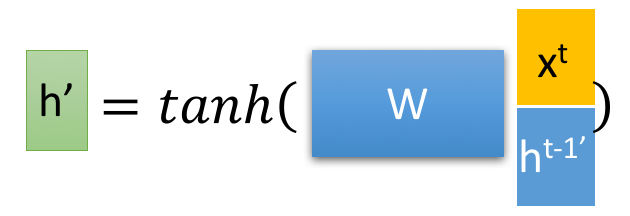
参考资料:
1、《Deep Learning》 book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
2、循环神经网络(RNN)模型与前向反向传播算法-刘建平Pinard
3、《Deep Learning》的学习笔记
4、人人都能看懂的GRU