python进程中的实例和json格式的字符串之间的映射关系是非常直接的,相当于同一个概念被编码成不同的表示:
stream in json form ----json.loads(str)-----> python object
stream in json form <----json.dumps(obj)----- python object
不过需注意类型的匹配,否则会报错。比如说json格式中大括号中的键值应当写成字符串。概念上json文本和python数据类型之间的对应关系是:
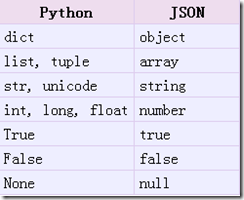
有没有觉得实在是太简单了!当然很重要的原因在于,json格式本身能很好的表达对象的概念。
PS: encode和decode这两个词的含义并没有明显的界限,都表示把同一个概念用不同的形式来表示。encode一般表示把概念在内存中的表示转换成在外存中的表示,decode则相反。
dumps()的参数
json.dumps()方法提供了很多好用的参数可供选择,比较常用的有sort_keys,separators,indent等参数。
参数值 sort_keys=True 表示对dict对象进行排序,我们知道默认dict是无序存放的。
参数值 indent=4 是缩进的意思,它可以使得数据存储的格式变得更加优雅,json格式的字符串的逗号后具有换行符,花括号和中括号中的内容有缩进。当然,输出的数据被格式化之后,变得可读性更强,但是却是通过增加一些冗余的空白格来进行填充的。json主要是作为一种数据通信的格式存在的,而网络通信是很在乎数据的大小的,无用的空格会占据很多通信带宽,所以适当时候也要对数据进行压缩。
参数值 separator=(",", ":") 的作用是数据压缩,去除冗余空白,减小网络通信量。该参数传递是一个元组,包含分割对象的字符串。
另一个比较有用的dumps参数是skipkeys,默认为False。 dumps方法存储dict对象时,key必须是str类型,如果出现了其他类型的话,那么会产生TypeError异常,如果开启该参数,设为True的话,则会比较优雅的过度。
不过还是要注意,处理外部输入输出的语句,尽量都写在 try: 语句块中。
自定义对象-json映射
需要自己实现函数。


class Person(object): def __init__(self,name,age): self.name = name self.age = age def __repr__(self): return 'Person Object name : %s , age : %d' % (self.name,self.age) if __name__ == '__main__': p = Person('Peter',22) print p import json p = Person.Person('Peter',22) def object2dict(obj): #convert object to a dict d = {} d['__class__'] = obj.__class__.__name__ d['__module__'] = obj.__module__ d.update(obj.__dict__) return d def dict2object(d): #convert dict to object if'__class__' in d: class_name = d.pop('__class__') module_name = d.pop('__module__') module = __import__(module_name) class_ = getattr(module,class_name) args = dict((key.encode('ascii'), value) for key, value in d.items()) #get args inst = class_(**args) #create new instance else: inst = d return inst d = object2dict(p) print d #{'age': 22, '__module__': 'Person', '__class__': 'Person', 'name': 'Peter'} o = dict2object(d) print type(o),o #<class 'Person.Person'> Person Object name : Peter , age : 22 dump = json.dumps(p,default=object2dict) print dump #{"age": 22, "__module__": "Person", "__class__": "Person", "name": "Peter"} load = json.loads(dump,object_hook = dict2object) print load #Person Object name : Peter , age : 22
直接实现文件的保存
dump(obj,fp) 和 obj=load(obj,fp)直接实现文件的保存,它们具有文件指针fp作为参数,dump函数需要可写指针,load需要可读指针。
file pointer <--------------> python object
import json jsonobj = json.load(open('jsonsource.dat', 'r')) json.dump(jsonobj, open('newjsonfile.dat', 'w'))
python中还有的pickle模块的用法也是类似的。
下面在讲解一些其他python细节知识。
python异常处理
为什么要用异常处理?因为当出现异常的时候,如果直接退出程序会导致程序太容易崩溃,如果只是简单打印调试信息又会导致运行时不能发现准确发现错误,所以在正式的开发中需要异常的引发和捕获。
异常处理包括异常的引发和捕获。很多错误是可以预料的,比如处理非法的输入,比如通信错误等等,我们常常需要在一些基础服务函数中引发异常,让上层代码捕获,而不是简答的打印错误信息或者简单的退出程序。
python使用 raise Exception("info") 来引发异常,用 try: except Exception, e: 来捕获在语句块中出现的任何异常:
try: a=2/0 b=a[2] except Exception,e: print Exception,":",e
如果仅仅是传递异常到更外层的代码,也就是不做任何其他处理,则只需单独使用 raise 关键字即可。
对异常的引发,要注意粒度的选择,要不然不知道到底是哪里出了问题。
对于异常的捕获,else 关键字基本上不需要用太多,直接在try中完成任务就可以了。
python字符串处理
ps:在 python中用正则表达式处理文本的编码范式是 : regex = re.compile(oldstring) ,然后 re.__( regex[, newstring], subject) 或者 regex.__([newstring,] subject)
re是一个模块,regex是正则表达式实例(概念上,regex和oldstring是同义词),subject是目标字符串。.subn 和 .sub表示替换,.split 表示分隔,.match 表示匹配
如果不用正则表达式,则只能用字符串类中定义的对应函数 subject.__(oldstring, newstring)
字符串编码与unicode类型
首先需要明确:
(1)在python中 str 和 unicode 是两种不同的对象类型,它们两者可以相互转换,但两个概念没有依赖关系。
(2)一个 str 类型的对象,用不同的编码方法可以有不同的二进制表示。unicode 对象常常作为转换 str 对象编码方式的中间角色。
(3)python进程会把引号 ' ' 解释为创建 str 实例的操作,把字符u后面跟引号 u' ' 解释为创建 unicode 实例的操作。
实验一下str对象和unicode对象的相互转换:
str转unicode,也就是 str ----decode()----> unicode:
>>> s ="u6d66u53d1u94f6u884c"
>>> s.decode('unicode_escape')
u'u6d66u53d1u94f6u884c'
>>> print s.decode('unicode_escape')
浦发银行
>>>
相反做法就是 str <----encode()---- unicode :
u'浦发银行'.encode('unicode_escape')