李宏毅-ELMO, BERT, GPT
参考资料
引言
One-of-Hot: 词汇鸿沟
Word-embedding: 语义相近的词在向量空间上也比较近
同一个词汇也会有不同的意思:
Have you paid that money to the bank yet ?
It is safest to deposit your money in the bank.
The victim was found lying dead on the river bank.
They stood on the riverbankto fish.The hospital has its own blood bank.
bank: 四个token, 相同的word type,有一模一样的embedding, 但事实上不是。
希望不同意思的token,也会有不同embedding。
Contextualized Word Embedding
- Each word token has its own embedding (even though it has the same word type)
- The embeddings of word tokens also depend on its context.
Embeddings from Language Model(ELMO)
https://arxiv.org/abs/1802.05365
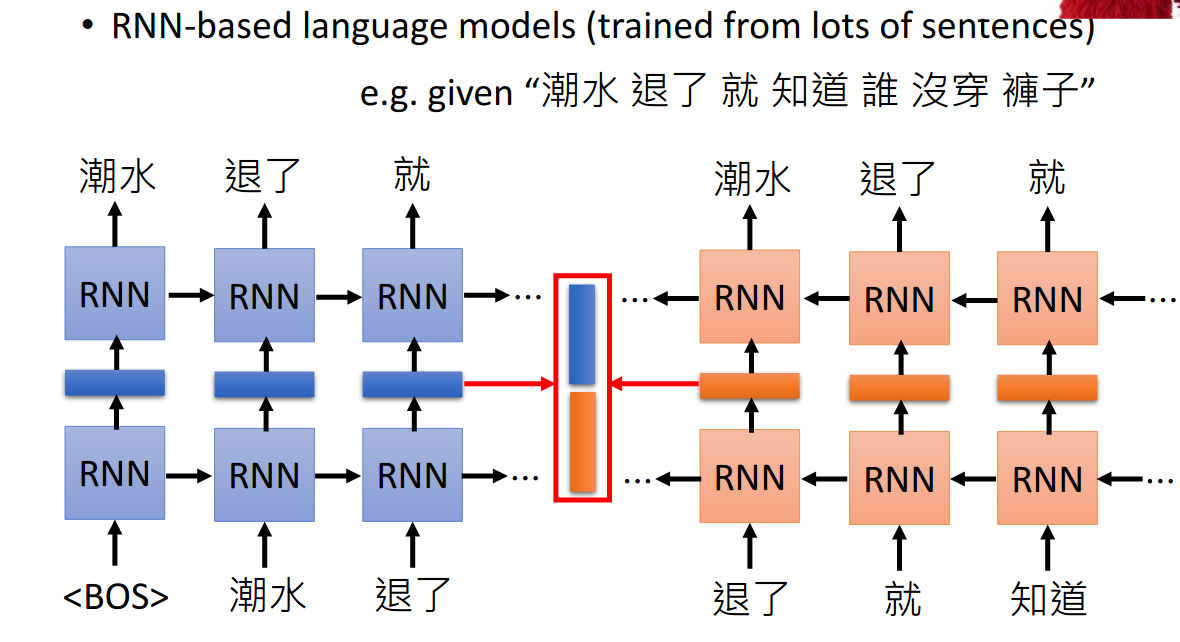
- 给他很多句子,所做的事情就是预测下一个token会是什么
- RNN的hidden layser就是token embedding,由于RNN hidden layer与之前看过的token有关,所以不同的上下文会有不同的hidden layer,这就实现了不同的token有不同的embedding
- 比如为了得到“退了”这个token的embedding,可以把前向和后向RNN得到的hidden layer concat起来:
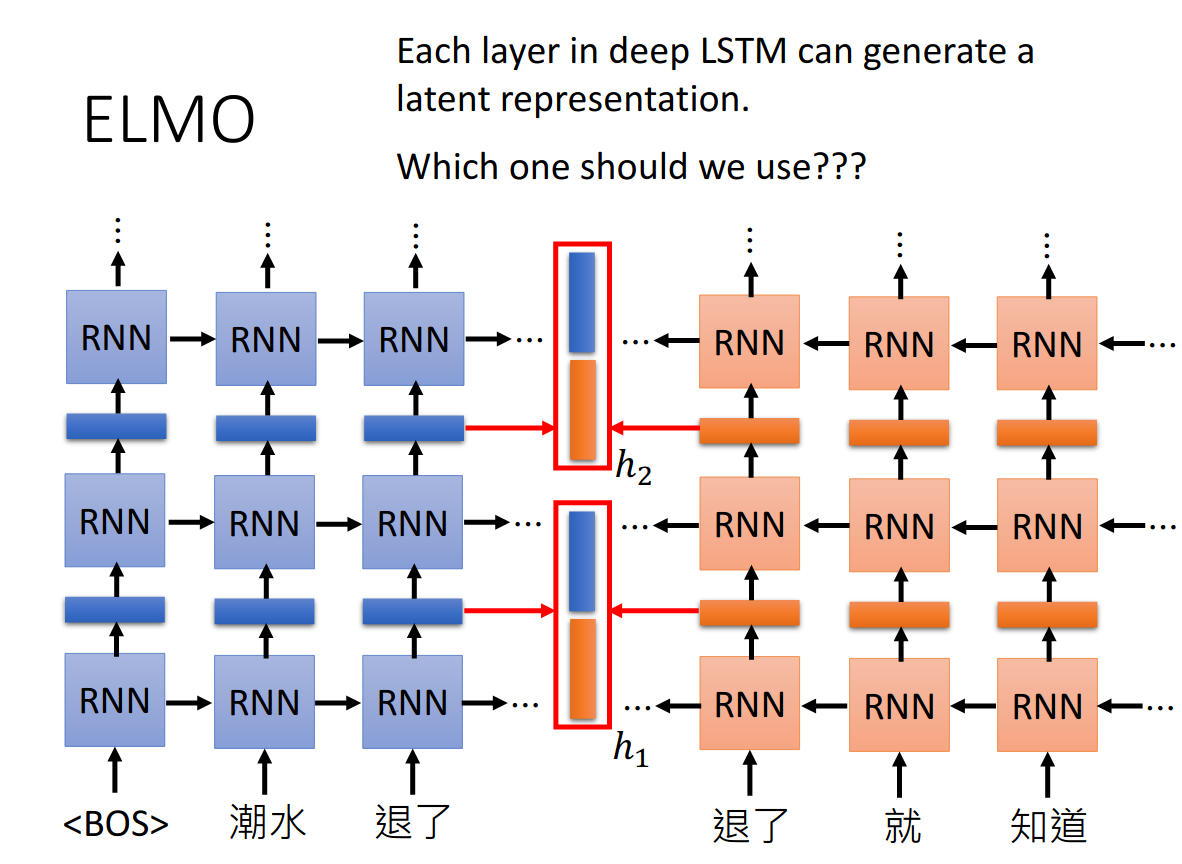
但是deep LSTM有好多层,每一层都会有latent representation, 用哪一层的呢?
ELMO是使用的weighted sum。
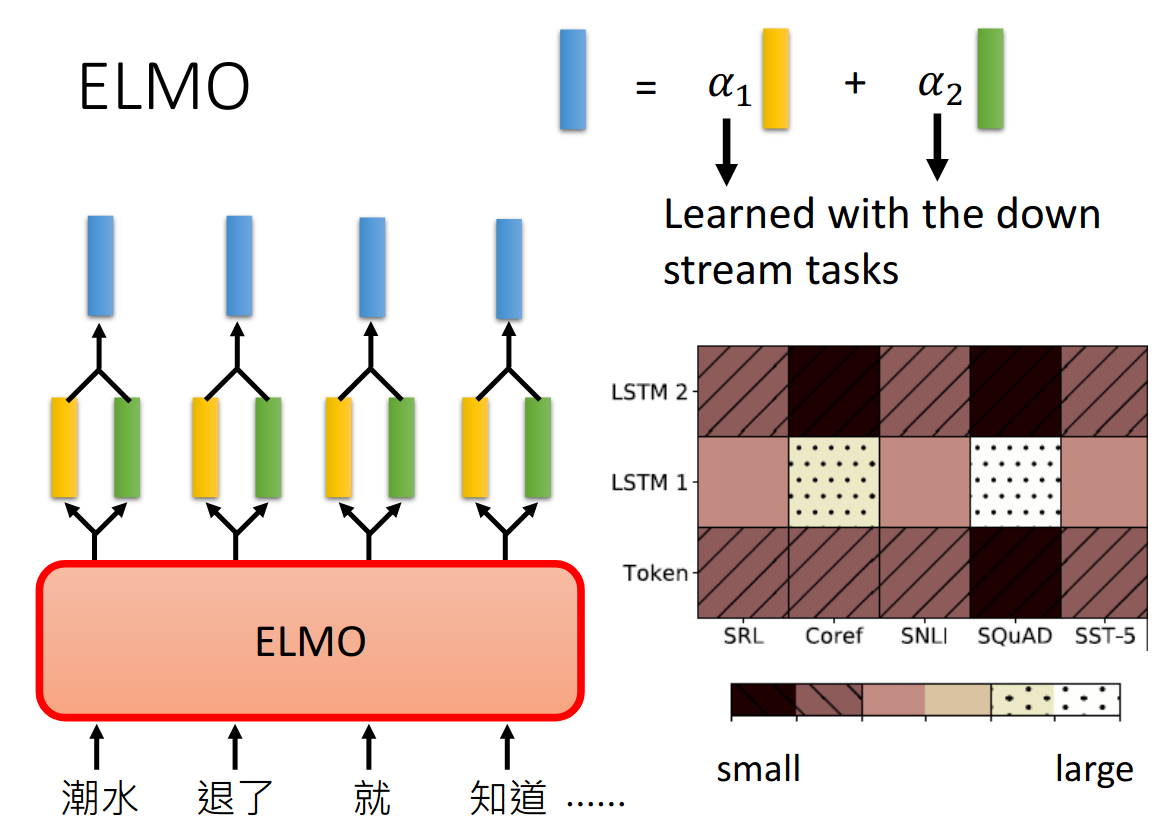
而权重(alpha)则是通过下游的任务学习得到, 最终的embedding有三个来源:
- token: 没有contextualized的word embedding
- LSTM1: 第一层得到的
- LSTM2: 第二层得到的
这三部分分别权重由不同的任务学到。
Bidirectional Encoder Representations from Transformers (BERT)
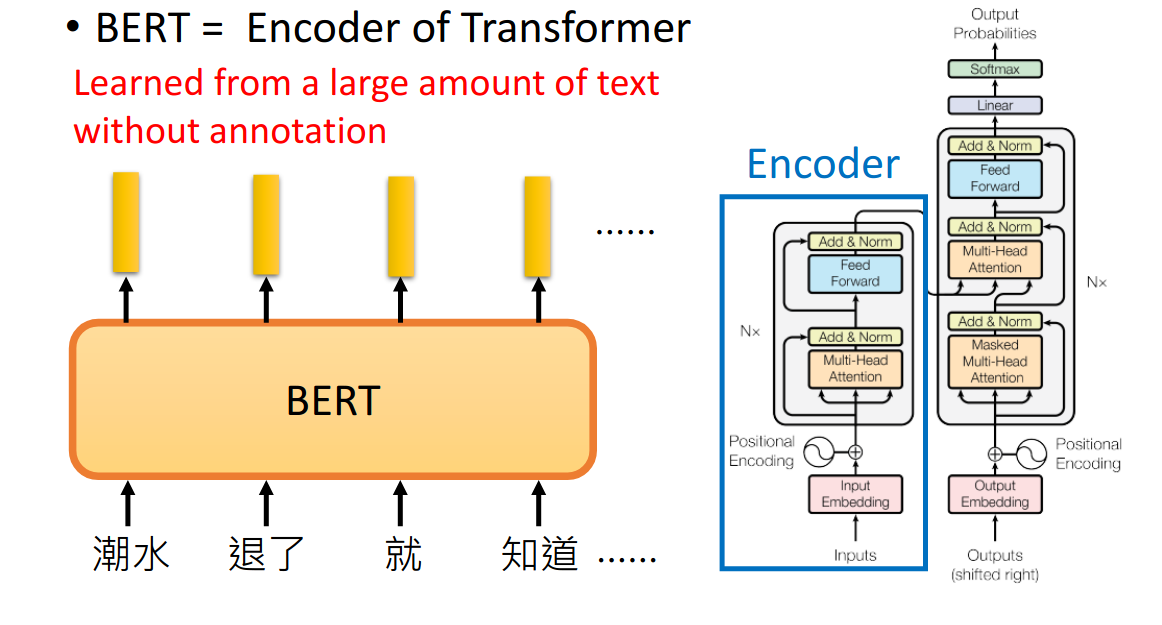
- BERT = Encoder of Transformer
- 把一个句子丢进去给Bert, 输出每个token 的embedding
- 其内部架构是Transformer的encoder部分
Training of BERT
-
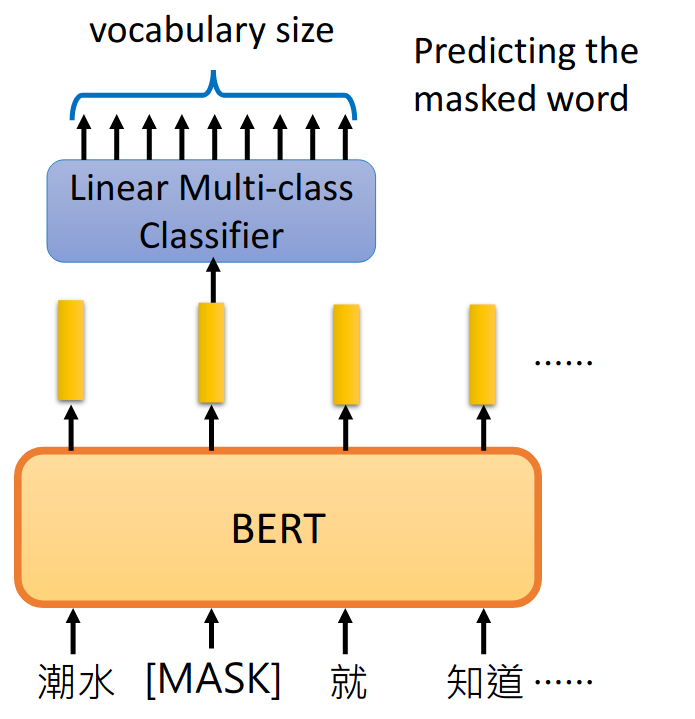
Approach 1: Masked LM
Predicting the masked word
以一定的概率盖掉一个句子里的token,bert做的就是填回这些被挖空的词:
怎么做?会将masked的词的embedding输入到一个线性的分类器中,预测出这个被masked的词汇。因为线性的分类器能力是比较弱的,这就要求embedding表达力比较强。
如果两个词汇填在同一个地方没有违和感,那他们就有类似的embedding。
-
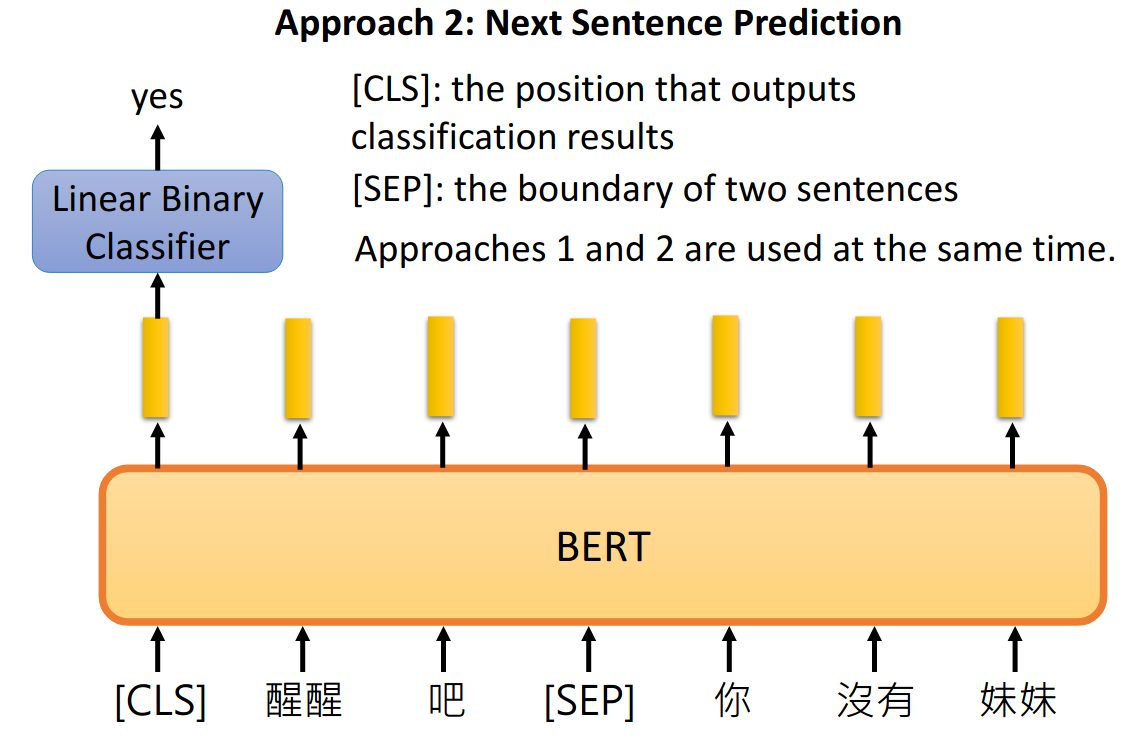
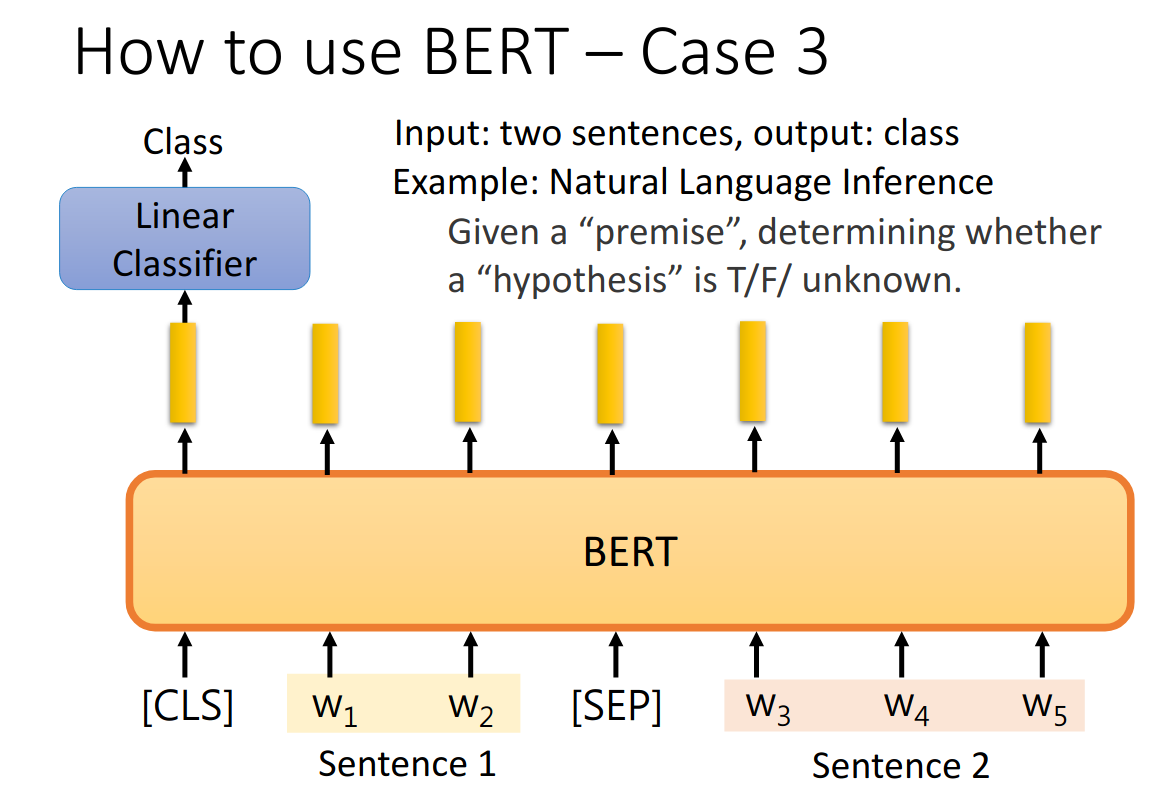
Approach 2: Next Sentence Prediction
给bert两个句子,[SEP]作为两个句子的分隔符,bert预测两个句子是不是接在一起的。[CLS]表示在这个位置需要去做预测,其输出的emebdding会输入到一个binary分类器中,去预测是还是否。
实际中,两种方法是同时使用的。
在Bert中,Bert是和下游任务一起训练的。
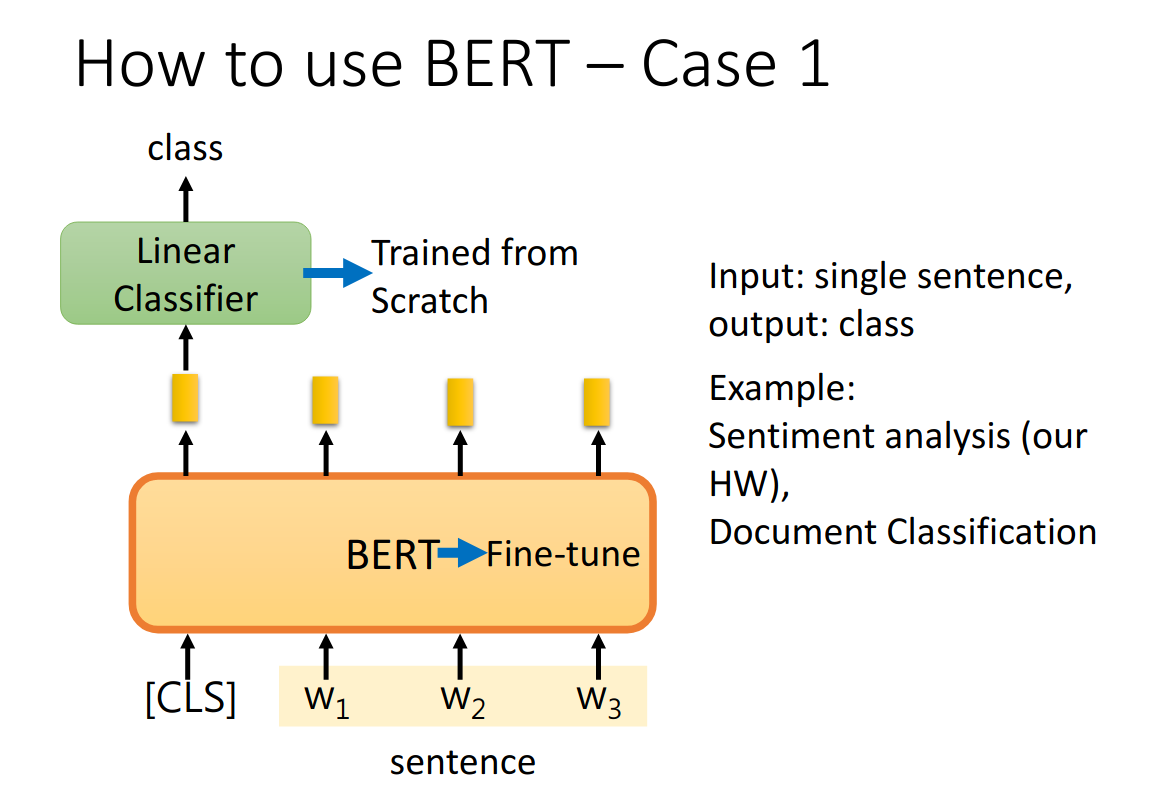
**How to use BERT **
- 句子分类
- 单词分类
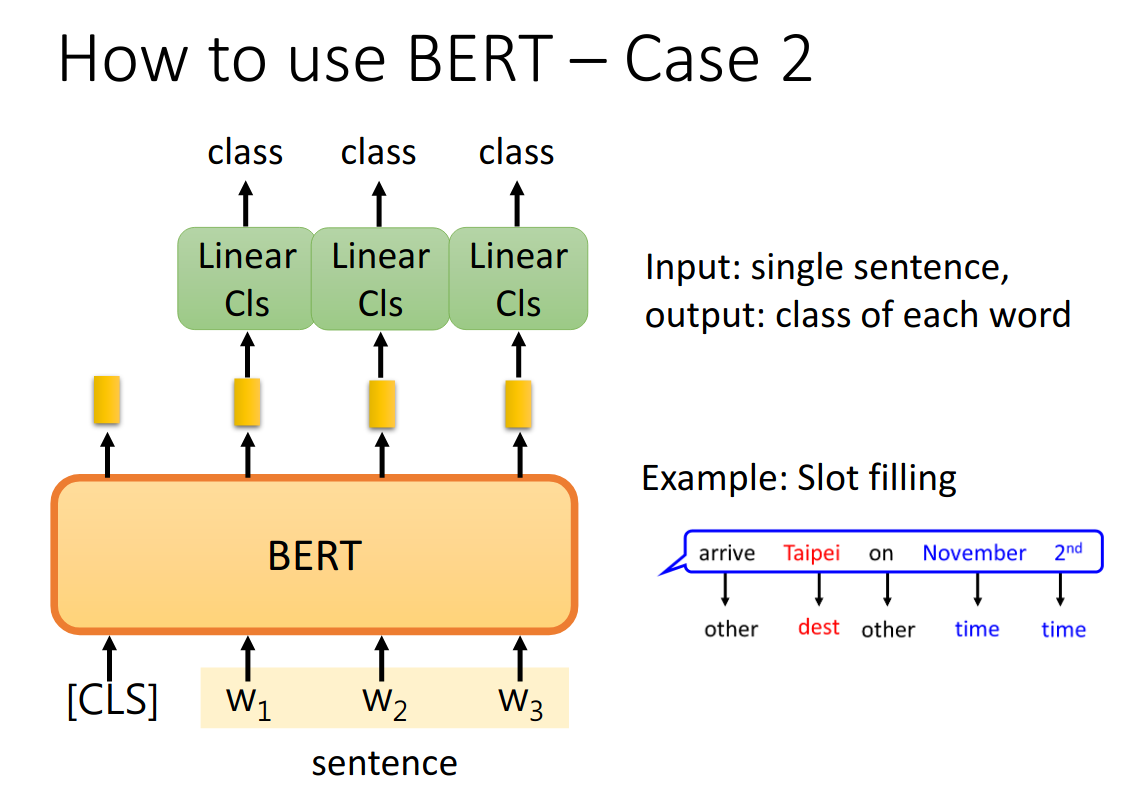
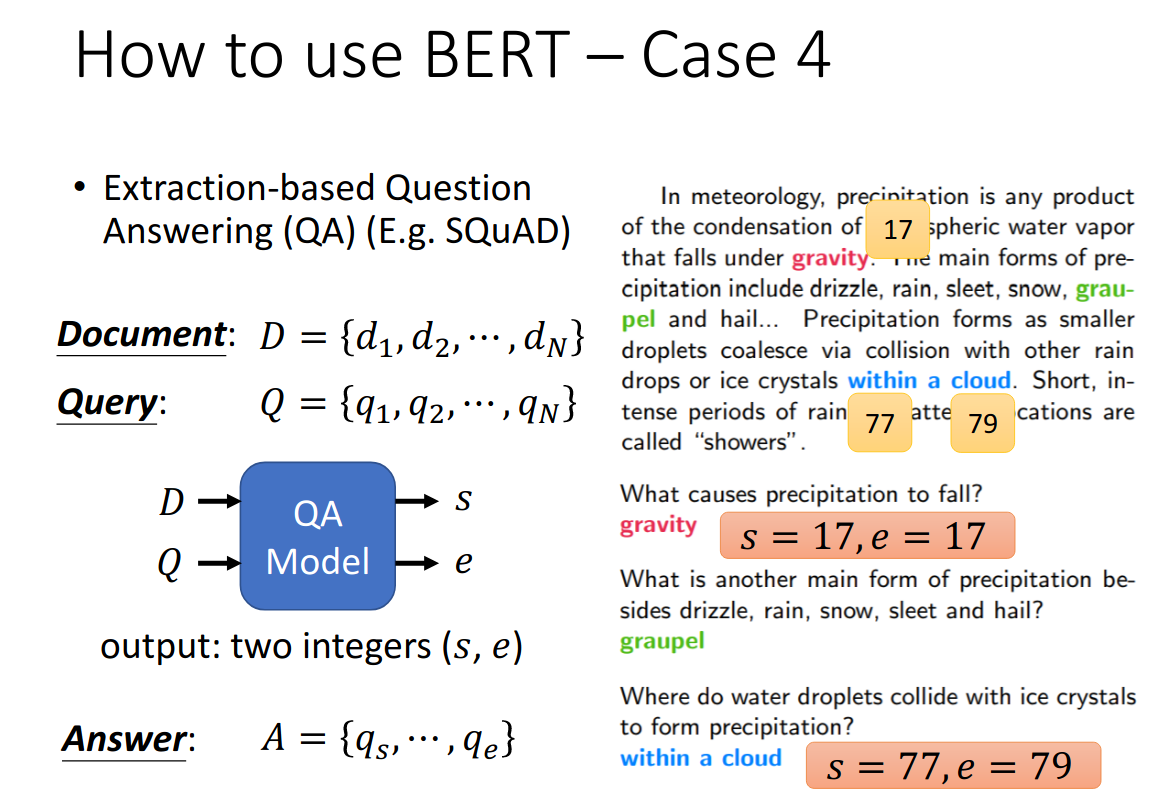
- Extraction-based QA: 问题的答案出现在原文中
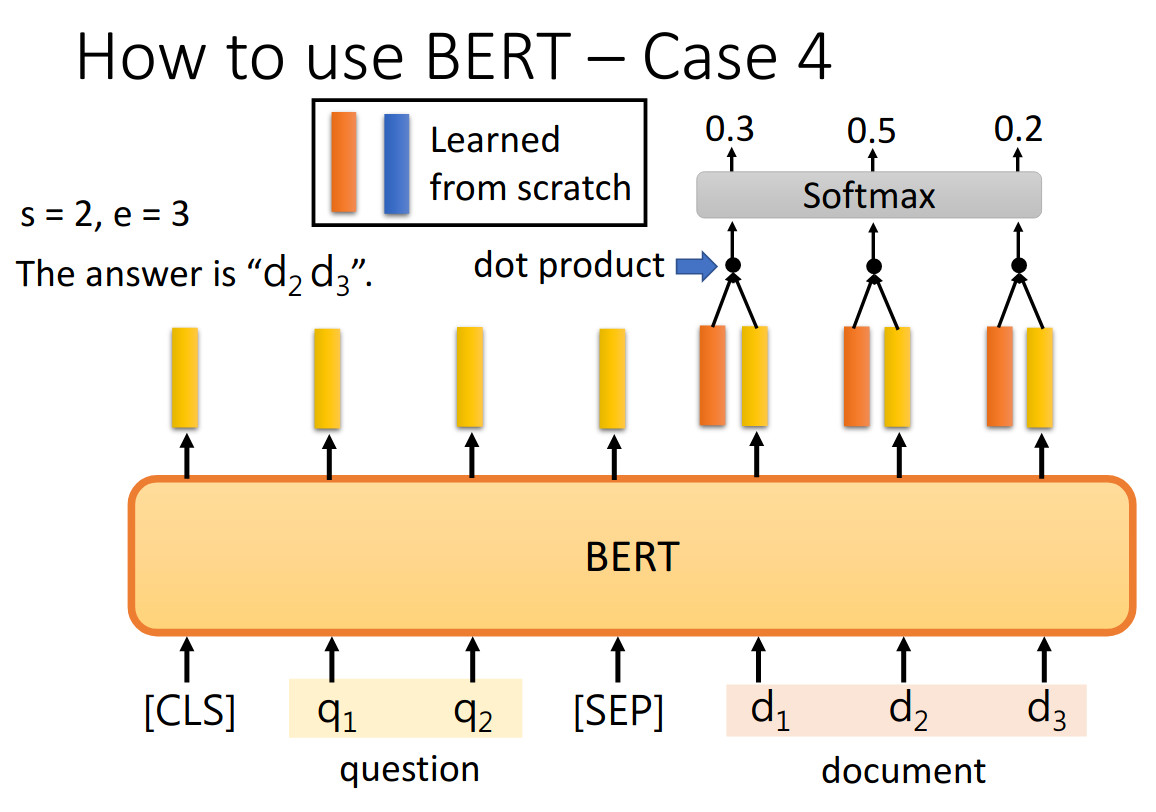
把问题-分隔符-原文输入到Bert中,每个单词输出一个黄色的embedding,然后还需要学习两个(一个橙色和一个蓝色)的向量,这两个向量分别与原文中的每个单词对一个的embedding进行点乘,经过softmax之后得到最高的位置。

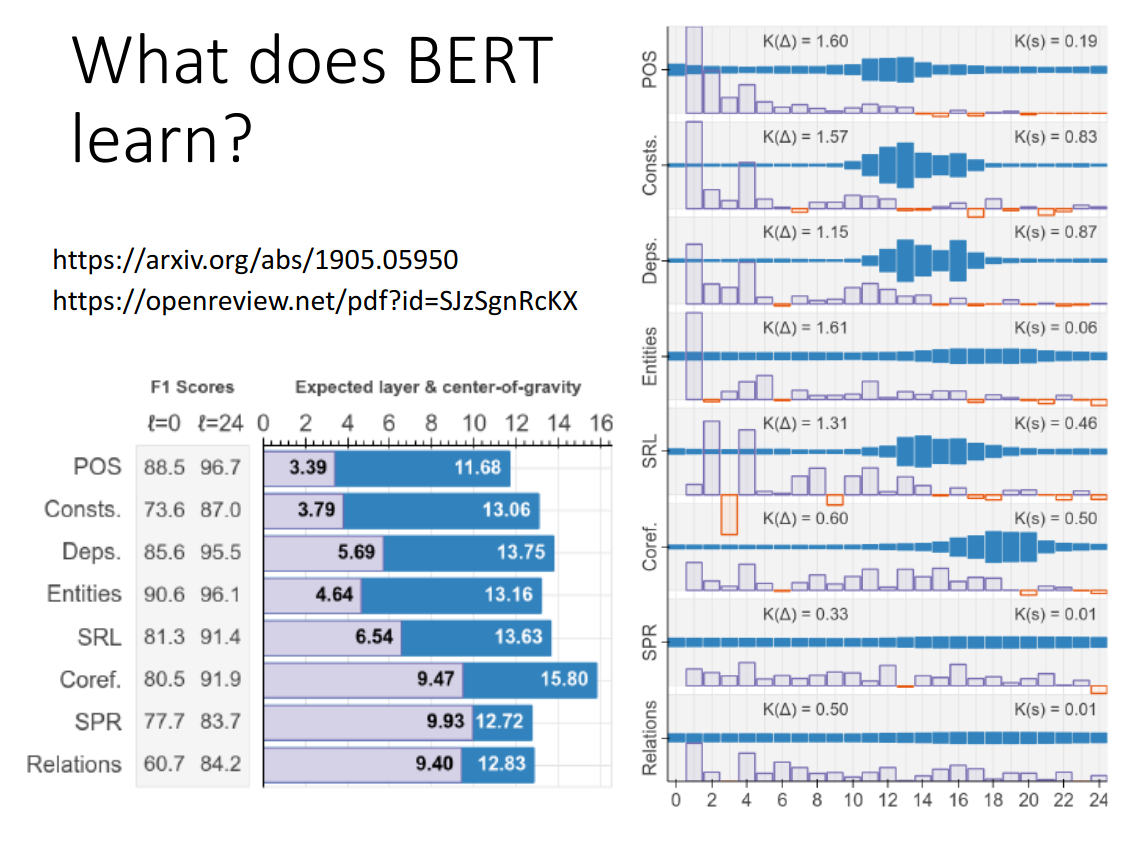
What does BERT learn?
https://arxiv.org/abs/1905.05950
https://openreview.net/pdf?id=SJzSgnRcKX
Bert深层的latent representation对于比较复杂的任务更有用。
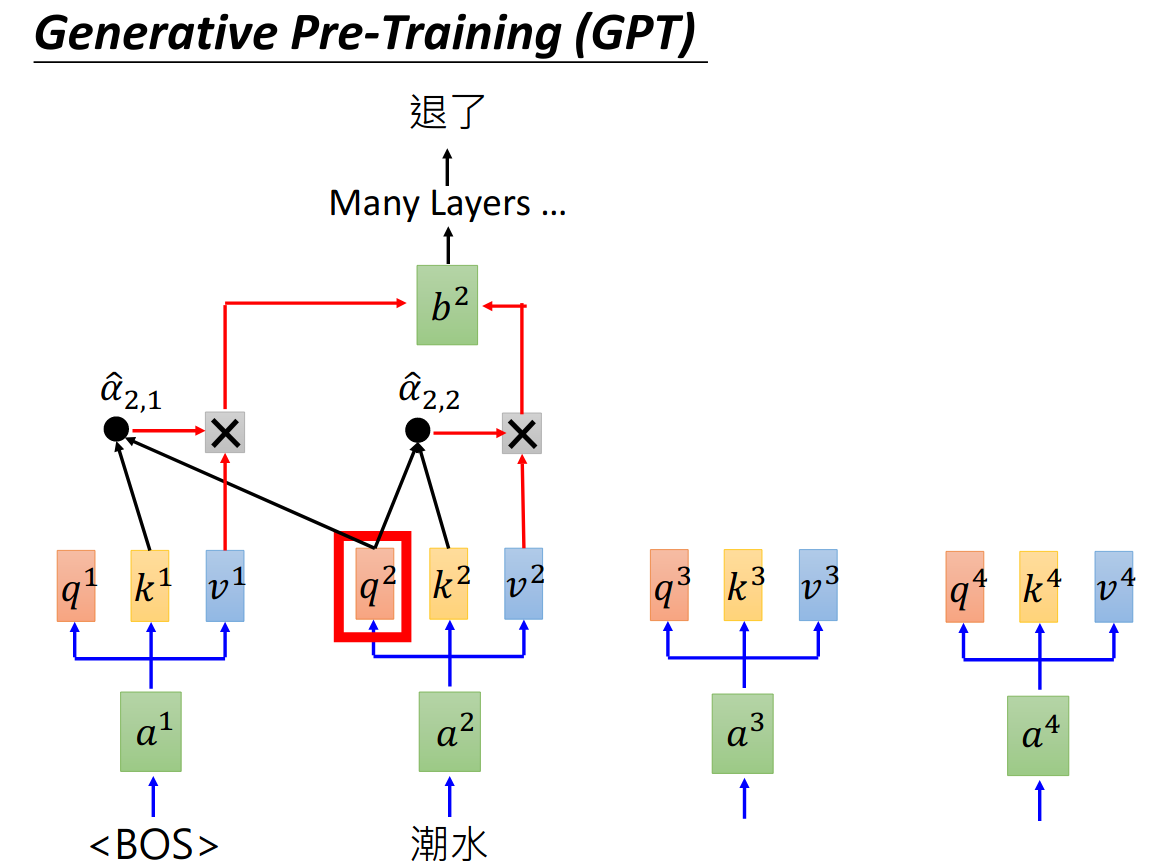
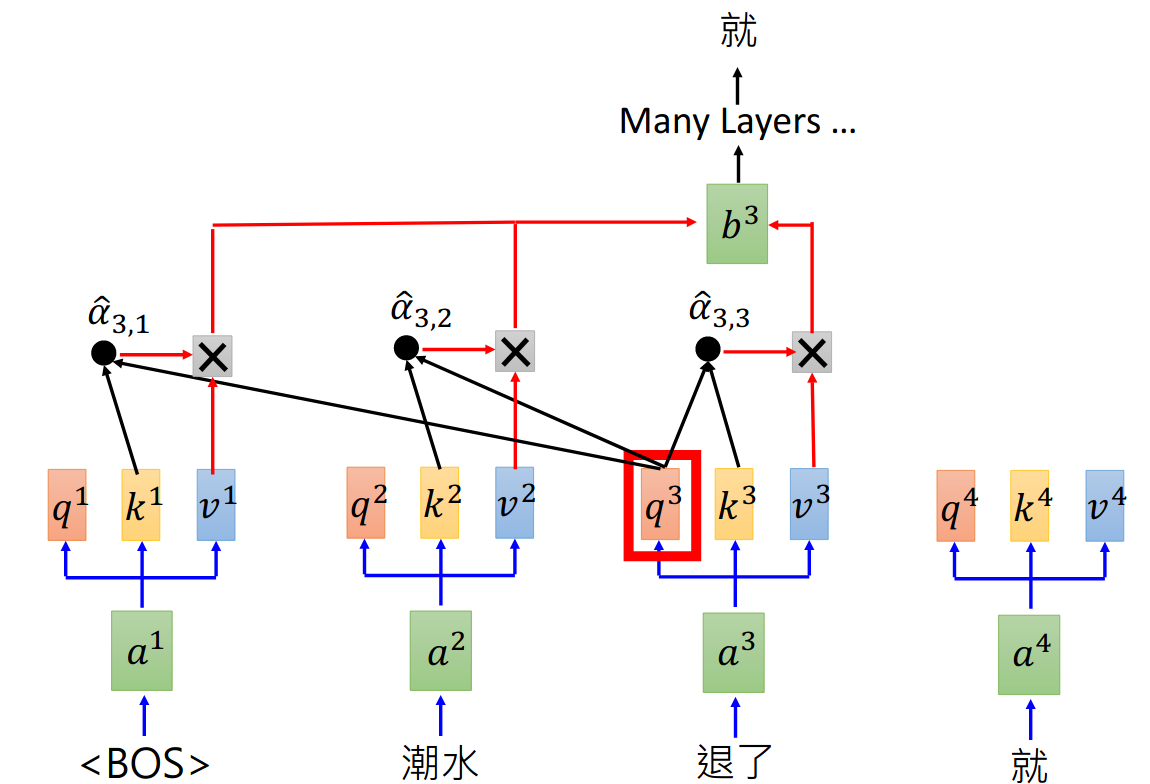
Generative Pre-Training (GPT)
ELMO: 94M参数
BERT: 340M参数
GPT-2: 1542M参数
GPT其实是Transformer的decoder,输入一个句子中的一个词,模型去预测句子中的下一个词。
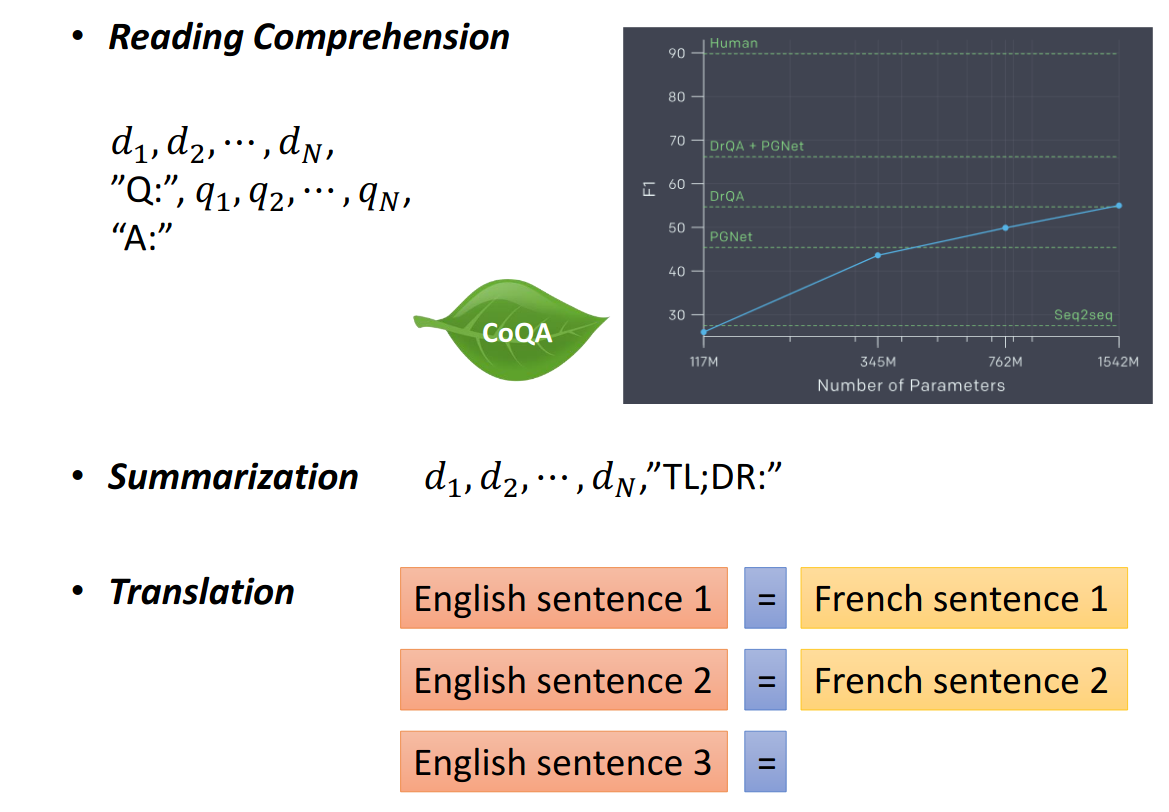
由于GPT-2模型非常巨大,它有很多神奇的结果,甚至可以做到zero-shot learning,(模型的迁移能力好), 比如阅读理解,在没有任何阅读理解训练集的情况下,输入一个A:,就可以输出答案。