一、前言
网络编程里一个经典的问题,select,poll和epoll的区别?这个问题刚学习编程时就接触了,当时看了材料很不明白,许多概念和思想没有体会,现在在这个阶段,再重新回头看这个问题,有一种豁然开朗的感觉,
把目前我所能理解到的记录下来。
参考资料:https://www.cnblogs.com/zingp/p/6863170.html
http://blog.csdn.net/a837199685/article/details/45954349
https://www.zhihu.com/question/32163005
http://shmilyaw-hotmail-com.iteye.com/blog/1896683
http://www.cnblogs.com/my_life/articles/3968782.html
https://www.cnblogs.com/Anker/p/3265058.html
二、从操作系统开始谈起
有几个以后一直谈到的概念,有必要先了解,以前就是这个步骤没做,学习的时候一脸懵逼。
1. 用户空间和内核空间
目前操作系统寻址模式为虚拟寻址,即处理器产生虚拟地址,之后翻译成物理地址,总线到物理地址处理,处理器拿到处理后的数据
操作系统 的核心为内核,可以访问受保护的内存空间,可以访问底层硬件设施,可以做任何事情。所以为了系统的稳定,讲道理内核应该被保护起来。
所以虚拟空间被分为内核空间和用户空间。内核空间在最高的1G中,用户空间在剩下的内存中。
多数我们所用的进程在用户空间处理,把请求发给内核,在内核空间中操作硬件。
2. 进程上下文切换(进程切换)
挂起当前进程,恢复某个进程,大家都知道这是个开销大的过程,那具体有哪些步骤呢?
首先,保存当前进程一些必要信息用以日后恢复,如描绘地址空间的页表,进程表,文件表等等。
然后切换页全局目录,安装一个新的地址空间
最后回复目标进程的上下文
3. 文件描述符(fd)
计算机的一个术语,指向文件对象的一个抽象表示。形式上是一个非负整数的索引值,指向文件表中的文件
当程序打开或创建一个文件时,内核向进程返回一个文件描述符,代表该文件。
通过操作文件描述符,我们实现真实操作文件的目的
4. 进程阻塞(process block)
当某个进程等待一个执行结果时,自身阻塞(不干事),直到得到结果,再继续往下,
重点是:这个是进程自身行为,且阻塞时不占用cpu资源(cpu也不干事),
所以I/O请求最拉低性能,俗话说占着茅坑不拉屎,在计算机里也是存在的,所以人们设计了多线程,多进程等方案来解决这个问题。
5. I/O过程
一般有两种模式,直接 I/O,缓存 I/O(默认),
缓存 I/O:
进程发起系统调用(通知系统我要读写了!)
写: 进程(数据) -------》 进程缓冲池 ------------》 内核缓冲池 ----------》存储设备
读: 存储设备(数据)---------》内核缓冲池 ----------》进程缓冲池 ---------》进程
直接 I/O(进程缓存池消失了!):
进程发起系统调用(通知系统我要读写了!)
写: 进程(数据) ------------》 内核缓冲池 ----------》存储设备
读: 存储设备(数据)---------》内核缓冲池 ---------》进程
以上每个步骤之间都是有可能进程会有阻塞(block)发生,根据不同位置的阻塞,就产生了多种网络模式,以适应于不同场景。
三、 I/O模式(以读为例)
1. block I/O
过程 :
进程发起系统调用(通知系统我要读写了!)
读: 存储设备(数据)---------》内核缓冲池 ---------》进程------------》内核通知进程ok,进程解除阻塞
进程阻塞 进程阻塞
解释:
进程一直等文件准备好,再继续下一步。
应用场景:
以上原理是一个用户连接的情况,很容易理解。
当一个服务器对接多个客户端的时候:
初级方案:开多进程(大数据或长时间任务、开销大,更安全)或多线程(很多连接,开销低,数据放一起不太安全)为每一个客户端建立一个连接来处理。
不足:高并发的情况就体现出开销大,性能低。一个是多线程切换,上下文切换的性能开销,另一个是多线程数量大,会占据大量系统资源
优化方案:采用线程池(减少创建和销毁线程的频率)或连接池(维持连接的缓存池,尽量重用已有的连接),降低系统开销
不足:降低开销还是有限度的,在这个时代,高并发大,很容易到达瓶颈。
2. non-block I/O
过程 :
发起系统调用(通知系统我要读写了!)
读: 存储设备(数据)-------------》内核缓冲池 -----------》进程-------------》内核通知进程ok,进程解除阻塞
非阻塞 阻塞
解释:
在内核准备数据阶段,立即返回一个error给进程,
因此进程知道内核还没准备好,
所以进程再问内核,内核再回error,直到内核准备好,被询问时返回准备好的信号,进程再接触阻塞,
应用场景:
连接量小,没差别,
当连接数大的时候,这个模式理论上可以用一个线程实现多个连接:
由于非阻塞,这个线程可以循环去询问所有连接目标有没有准备好,内核都是立马回复,error往下,准备好就交给进程,所以不会浪费时间,
但是,(凡事都有但是),这个简单的实现方案,效率还是很低的,毕竟从内核空间到用户空间还是block的,而且会极大推高cpu占用率。
特别是当响应事件(读取或者其他)庞大的时候,执行速度就会很缓慢。
下面的select等就是基于此想法的发展。
3. I/O multiplexing
目标:低开销,高效率得处理高并发请求
方案:select 、poll、epoll 三种实现方案
本质:用 select、poll、epoll 去监听所有 socket对象,当socket对象发生变化时,通知用户进程处理。
特征:
select(最早出现):多平台支持
通过轮询,效率较低
处理连接数量有限制,默认1024个,
大量用户态和内核态fd的拷贝,性能低,
返回的是所有句柄列表,没有告诉是哪一个发生变化,用户进程还得再次遍历。
poll(略微改进):改进了数量连接限制,做到了数量无限制
epoll(改进所有缺点):当socket变化时,通知进程哪一个完成了,
数量无限制(为系统最大打开文件数量)
fd句柄只拷贝一次,性能高
性能对比:
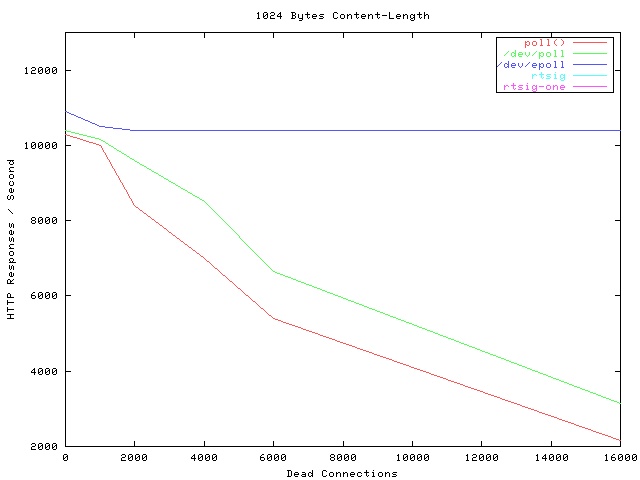
横坐标是连接数,Dead Connections 是软件命名的,纵坐标是此时处理连接数
可以看出 epoll 性能比较稳定,而且性能较优。
仔细过程讨论:
这里只讨论大致原理,具体实现不同语言有不同的差别。(不是因为我没做过,不是的)
首先。在多路复用模型中,对于每一个 socket,一般都设置成为 non-blocking,但是,整个用户的 process 其实是一直被 block 的
即用户进程被select、poll阻塞,但是select、poll是非阻塞的,他们不断轮询、挂起来完成工作。
select:
1. 从用户态拷贝 fd_set 至内核空间(告诉内核要监听的socket)
2..注册回调函数pollwait(将进程挂到等待队列中,当socket准备好后(执行mask状态码判断),再唤醒进程)
3. 内核遍历fd,调用每一个的poll方法(本质上是pollwait回调函数,返回值socket的mask状态掩码,即现在准备好了没,给fd_set赋值)
4. 当无可读写mask码(没有任何准备好的),select睡眠,等睡眠时间到,再次醒来轮询fd-set
5. 有值时返回fd_set(已经赋值完,例如可以读的value为1)、将其拷贝至用户空间
6. 用户进程循环fd_set,
分析:
每次循环都要执行上面流程,
一次循环两次拷贝fi_set,即每次监听都重新告诉内核要监听的事件,在用户量很大的时候是一个很大的开销
返回所有的fd_set,却没有告诉进程哪一个是完成的,进程还得循环判断,用户量很大(十万,百万)的时候,性能太低
因此,select只支持1024个连接。
这也解释了上图中为什么连接量越大,性能越低的现象,许多时间用来处理无活跃的连接、循环判断中,在高并发低活跃的场景中尤为如此。
poll:
将fd_set结构改为pollfd结构,可以不限数量,但是其他问题咩有解决。
epoll:
改进:
fd只拷贝一次(开始就告诉内核所有注册事件,监听对象)。
只返回包含所有变化的fd的链表。
连接无限制
epoll提供三个函数
epoll_create(句柄),开始是有size参数,说明fd数量,现在内核动态分配,
epoll_ctl(注册事件类型),注册监听事件
epoll_wait(等待事件发生),捕捉fd信号,
三者区别小结:
select、poll 孪生兄弟,有许多缺点,优点不多,应用场景也不多。是时代的产物
epoll 是进阶版,但是只有Linux有,
具体情况具体分析。
4. 异步io
解释:进程完全不阻塞,请求发完就去做其他事,等数据全部准备好,内核发消息给进程,进程接着处理,
实现:听说很复杂,没研究。
四、总结和挖坑
研究了一些操作系统的概念,研究了I/O模式,着重研究了select、poll、epoll 的区别,
有时间 具体实现和操作,实践出真知,许多细节可能还有谬误,待以后水平上升,再来修改。