作者:桂。
时间:2018-02-06 17:52:38
链接:http://www.cnblogs.com/xingshansi/p/8423457.html
前言
到目前为止,本文没有对滤波器实现进行梳理,FIR仿真验证的平台(基于FPGA实现)包括HLS、Systemgenerator,至于*.v 与*.sv可通过程序(如python实现)完成转化,FIR的零散记录到本篇告一段落,本文重点记录DSP48E的使用
一、DSP48E
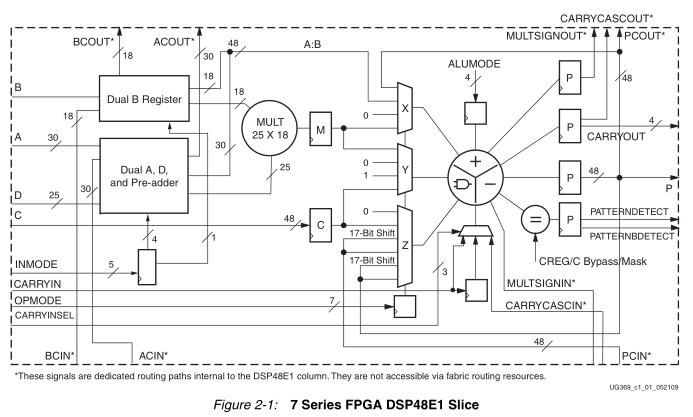
A-基本结构
主要参考UG479.pdf,DSP48E1结构:

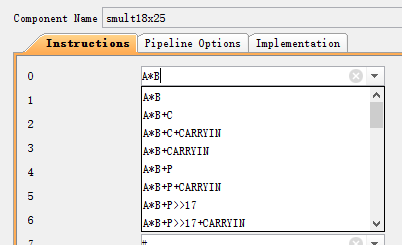
可以看出主要功能为:P = (A±D)×B±C。具体功能可参考IP核:
slice结构及位宽关系:
DSP48E在Xilinx内部的布局:
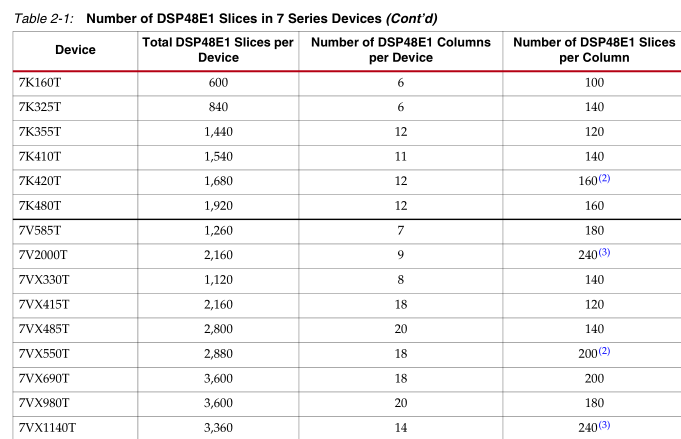
常用器件DSP48E资源:
B-原语调用
原语类似C语言的汇编,直接关联器件的底层结构,因此通常时序可以做的更好。
DSP48E支持原语调用,记录两个例子:
Ex1:
`timescale 1ns / 1ps
// m = b * (a + d)
// p = c+m or p+m
module dsp48_wrap_f
(
input clock,
input ce1,
input ce2,
input cem,
input cep,
input signed [24:0] a,
input signed [17:0] b,
input signed [47:0] c,
input signed [24:0] d, // this has two fewer pipe stages
// X+Y is usually the multiplier output (M)
// Z is either P, PCIN or C
// bit 1:0: 0: Z+X+Y 3:Z-(X+Y) 1: -Z + (X+Y) 2: -1*(Z+X+Y+1)
// bits 3:2, 0: Z=0, 1: Z=PCIN, 2: Z=P, 3: Z = C
// bit 4: sub in pre add
input [4:0] mode,
input signed [47:0] pcin,
output signed [47:0] pcout,
output signed [47-S:0] p);
parameter S = 0;
parameter USE_DPORT = "FALSE"; // enabling adds 1 reg to A path
parameter AREG = 1;
parameter BREG = 1; // 0 - 2
wire signed [47:0] dsp_p;
assign p = dsp_p[47:S];
DSP48E1
#(
.A_INPUT("DIRECT"), // "DIRECT" "CASCADE"
.B_INPUT("DIRECT"), // "DIRECT" "CASCADE"
.USE_DPORT(USE_DPORT),
.USE_MULT("MULTIPLY"),// "MULTIPLY" "DYNAMIC" "NONE"
.USE_SIMD("ONE48"), // "ONE48" "TWO24" "FOUR12"
// pattern detector - not used
.AUTORESET_PATDET("NO_RESET"), .MASK(48'h3fffffffffff),
.PATTERN(48'h000000000000), .SEL_MASK("MASK"),
.SEL_PATTERN("PATTERN"), .USE_PATTERN_DETECT("NO_PATDET"),
// register enables
.ACASCREG(1), // pipeline stages between A/ACIN and ACOUT (0, 1 or 2)
.ADREG(1), // pipeline stages for pre-adder (0 or 1)
.ALUMODEREG(1), // pipeline stages for ALUMODE (0 or 1)
.AREG(AREG), // pipeline stages for A (0, 1 or 2)
.BCASCREG(1), // pipeline stages between B/BCIN and BCOUT (0, 1 or 2)
.BREG(BREG), // pipeline stages for B (0, 1 or 2)
.CARRYINREG(1), // this and below are 0 or 1
.CARRYINSELREG(1),
.CREG(1),
.DREG(1),
.INMODEREG(1),
.MREG(1),
.OPMODEREG(1),
.PREG(1))
dsp48_i
(
// status
.OVERFLOW(),
.PATTERNDETECT(), .PATTERNBDETECT(),
.UNDERFLOW(),
// outs
.CARRYOUT(),
.P(dsp_p),
// control
.ALUMODE({2'd0, mode[1:0]}),
.CARRYINSEL(3'd0),
.CLK(clock),
.INMODE({1'b0,mode[4],3'b100}),
.OPMODE({1'b0,mode[3:2],4'b0101}),
// signal inputs
.A({5'd0,a}), // 30
.B(b), // 18
.C(c), // 48
.CARRYIN(1'b0),
.D(d), // 25
// cascade ports
.ACOUT(),
.BCOUT(),
.CARRYCASCOUT(),
.MULTSIGNOUT(),
.PCOUT(pcout),
.ACIN(30'h0),
.BCIN(18'h0),
.CARRYCASCIN(1'b0),
.MULTSIGNIN(1'b0),
.PCIN(pcin),
// clock enables
.CEA1(ce1), .CEA2(ce2),
.CEAD(1'b1),
.CEALUMODE(1'b1),
.CEB1(ce1), .CEB2(ce2),
.CEC(1'b1),
.CECARRYIN(1'b1),
.CECTRL(1'b1), // opmode
.CED(1'b1),
.CEINMODE(1'b1),
.CEM(cem), .CEP(cep),
.RSTA(1'b0),
.RSTALLCARRYIN(1'b0),
.RSTALUMODE(1'b0),
.RSTB(1'b0),
.RSTC(1'b0),
.RSTCTRL(1'b0),
.RSTD(1'b0),
.RSTINMODE(1'b0),
.RSTM(1'b0),
.RSTP(1'b0)
);
endmodule // dsp48_wrap_f
Ex2:
// p = c + b * a 3 cycles if r else p = p + b * a
module macc
(
input clock,
input [2:0] ce, // bit 0 = a, 1 = b , 2 = c
input r, // reset accumulator to c + a*b
input signed [24:0] a,
input signed [17:0] b,
input signed [47:0] c,
output signed [47-S:0] p);
parameter S = 0;
parameter AREG = 1; // 0 - 2
parameter BREG = 1; // 0 - 2
wire signed [47:0] dsp_p;
assign p = dsp_p[47:S];
// X+Y is usually the multiplier output (M)
// Z is either P, PCIN or C
// bit 1:0: 0: Z+X+Y 3:Z-(X+Y) 1: -Z + (X+Y) 2: -1*(Z+X+Y+1)
// bits 3:2, 0: Z=0, 1: Z=PCIN, 2: Z=P, 3: Z = C
// bit 4: sub in pre add
wire [4:0] mode = {1'b0, r ? 2'b11 : 2'b10, 2'b00};
DSP48E1
#(
.A_INPUT("DIRECT"), // "DIRECT" "CASCADE"
.B_INPUT("DIRECT"), // "DIRECT" "CASCADE"
.USE_DPORT("FALSE"),
.USE_MULT("MULTIPLY"),// "MULTIPLY" "DYNAMIC" "NONE"
.USE_SIMD("ONE48"), // "ONE48" "TWO24" "FOUR12"
// pattern detector - not used
.AUTORESET_PATDET("NO_RESET"), .MASK(48'h3fffffffffff),
.PATTERN(48'h000000000000), .SEL_MASK("MASK"),
.SEL_PATTERN("PATTERN"), .USE_PATTERN_DETECT("NO_PATDET"),
// register enables
.ACASCREG(1), // pipeline stages between A/ACIN and ACOUT (0, 1 or 2)
.ADREG(1), // pipeline stages for pre-adder (0 or 1)
.ALUMODEREG(1), // pipeline stages for ALUMODE (0 or 1)
.AREG(AREG), // pipeline stages for A (0, 1 or 2)
.BCASCREG(1), // pipeline stages between B/BCIN and BCOUT (0, 1 or 2)
.BREG(BREG), // pipeline stages for B (0, 1 or 2)
.CARRYINREG(1), // this and below are 0 or 1
.CARRYINSELREG(1),
.CREG(1),
.DREG(1),
.INMODEREG(1),
.MREG(1),
.OPMODEREG(1),
.PREG(1))
dsp48_i
(
// status
.OVERFLOW(),
.PATTERNDETECT(), .PATTERNBDETECT(),
.UNDERFLOW(),
// outs
.CARRYOUT(),
.P(dsp_p),
// control
.ALUMODE({2'd0, mode[1:0]}),
.CARRYINSEL(3'd0),
.CLK(clock),
.INMODE({1'b0,mode[4],3'b100}),
.OPMODE({1'b0,mode[3:2],4'b0101}),
// signal inputs
.A({5'd0,a}), // 30
.B(b), // 18
.C(c), // 48
.CARRYIN(1'b0),
.D(25'd0), // 25
// cascade ports
.ACOUT(),
.BCOUT(),
.CARRYCASCOUT(),
.MULTSIGNOUT(),
.PCOUT(),
.ACIN(30'h0),
.BCIN(18'h0),
.CARRYCASCIN(1'b0),
.MULTSIGNIN(1'b0),
.PCIN(48'h0),
// clock enables
.CEA1(1'b1), .CEA2(ce[0]),
.CEAD(1'b1),
.CEALUMODE(1'b1),
.CEB1(1'b1), .CEB2(ce[1]),
.CEC(ce[2]),
.CECARRYIN(1'b1),
.CECTRL(1'b1), // opmode
.CED(1'b1),
.CEINMODE(1'b1),
.CEM(1'b1), .CEP(1'b1),
.RSTA(1'b0),
.RSTALLCARRYIN(1'b0),
.RSTALUMODE(1'b0),
.RSTB(1'b0),
.RSTC(1'b0),
.RSTCTRL(1'b0),
.RSTD(1'b0),
.RSTINMODE(1'b0),
.RSTM(1'b0),
.RSTP(1'b0)
);
endmodule
二、FIR实现思路
考虑到调用DSP48E,首先分析DSP48E乘法/乘加的时序特性:
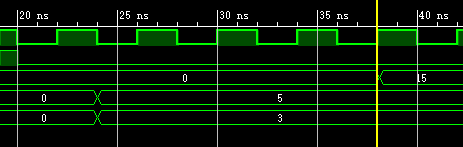
可以看出输出相比输入,延迟4拍,仿真3*5,结果与理论一致:
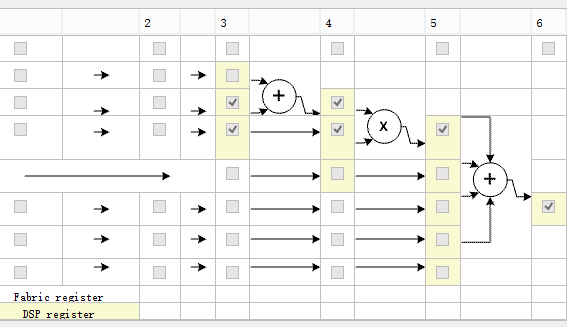
以N-1(不失一般性,N=6)阶FIR为例,由于乘法可支持25*18,假设数据18(bit),滤波器系数25(bit)。滤波器系数个数为6:
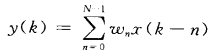
因此可得FIR实现的基本流程:
- Step1:对于t时刻,输入数据与滤波器系数相乘,得到y(t)[N-1:0]
- Step2:更新数据流:data_chain(t) = y(t)[N-1:0] + [data_chain(t-1) [N-2:0],0]
- Step3:输出滤波结果:output = data_chain(t) [N-1]
根据算法流程,设计FPGA数据流:
1)参数位宽定义
- 输入数据:parameter indatwidth = 18;
- 滤波器系数:parameter coefwidth = 25;
- DSP48核输出位宽:localparam multoutwidth = coefwidth + indatwidth;
- 输出数据(自定义):parameter outdatwidth = 18;
- 数据流(截断位宽自定义):这里 localparam chainwidth 用multoutwidth替代;
2)数据运算拆解
结合上文Step2的特性,细节上:a)可针对coef0单独用乘法运算、其他coef利用乘加运算,b)也可以对datachain补零,这里采用后一种思路。
- 输入输出
input [indatwidth-1:0] datin;
input [5:0][coefwidth-1:0] coef;
input clk,rst;
output signed [outdatwidth-1:0] datout;
- DSP48的乘加操作
genvar ii;
generate
for(ii = 0; ii < N; ii++)
begin
multiplus mpu(
.CLK(clk),
.A(coef[ii]),
.B(datin),
.C(dti[ii]),
.P(mres[ii])
);
end
endgenerate
- 关于截位
对数据进行截位,例如对x截位,通常不是直接舍去其他位数,而是对x进行4舍5入,转化到FPGA就是:
x1 <= x[起始位置 -: 有效位数] + 1;
result <= (x1>>>1);
这里仅论证实现思路,截位的细节操作不再添加。
- 乘法器的延拍
genvar ii;
generate
for(ii = 1; ii < N; ii++)
begin
always @(posedge clk) begin
dtchain[ii][fixdelay-1:1] <= dtchain[ii][fixdelay-2:0];
dtchain[ii][0] <= mres[ii-1][multoutwidth-1:0];
end
end
endgenerate
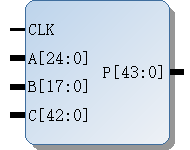
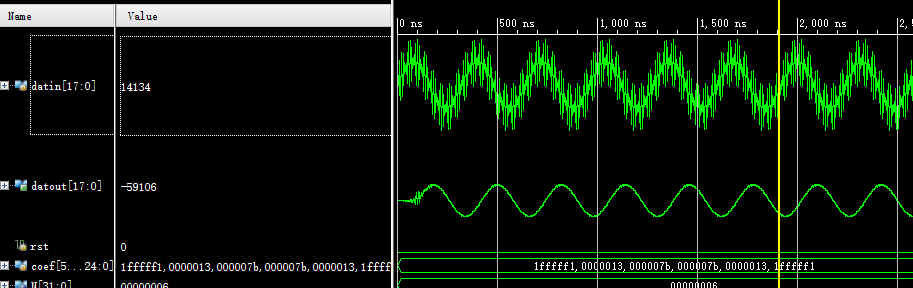
三、仿真验证
首先MATLAB仿真验证上述步骤的有效性:
%FIR功能验证
clc;clear all;close all;
coef = [-15,19,123,123,19,-15];
datin = [3,13,17,21,24,28,31];
%main
%不考虑延拍,datachain不必引入
N = 6;
mres = zeros(1,N);
dto = zeros(1,N);
result = [];
for i = 1:length(datin)
dto(2:N) = mres(1:N-1);
mres = datin(i)*coef + dto;
result = [result,mres(N)];
end
%compare
conv_res = conv(datin,coef);
[result;conv_res(1:length(datin))]
算法运算结果与理论一致:
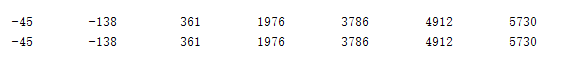
编写测试模块及testbench:
winfilter.sv
`timescale 1ns / 1ps
module winfilter(coef, datin, clk, rst, datout);
//parameter
parameter indatwidth = 18;
parameter outdatwidth = 18;
parameter coefwidth = 25;
localparam multoutwidth = coefwidth + indatwidth;
localparam N = 6;
localparam fixdelay = 4;//smultplus delay
//port
input [indatwidth-1:0] datin;
input [N-1:0][coefwidth-1:0] coef;
input clk,rst;
output [outdatwidth-1:0] datout;
//define
reg signed [outdatwidth-1:0] datout;
reg [N-1:0][fixdelay-1:0][multoutwidth-1:0] dtchain;
wire [N-1:0][multout0] mres;
//initial
initial
begin
dtchain <= 0;
datout <= 0;
end
//main
genvar ii;
generate
for(ii = 1; ii < N; ii++)
begin
always @(posedge clk) begin
dtchain[ii][fixdelay-1:1] <= dtchain[ii][fixdelay-2:0];
dtchain[ii][0] <= mres[ii-1][multoutwidth-1:0];
end
end
endgenerate
generate
for(ii = 0; ii < N; ii++)
begin
multiplus multp_inst(
.CLK(clk),
.A(coef[ii]),
.B(datin),
.C(dtchain[ii][fixdelay-1]),
.P(mres[ii])
);
end
endgenerate
//output
always @(posedge clk)
begin
if(rst)
begin
datout <= 0;
end
else
begin
datout <= mres[N-1][multoutwidth-19 -: outdatwidth];
//datout <= mres[N-1][multoutwidth-2 -: outdatwidth];
end
end
endmodule
tb
`timescale 1ns / 1ps
module tb();
logic [17:0] datin;
logic clk,rst;
logic [5:0][24:0] coef;
logic [17:0] datout;
//-------------------------------------//
parameter data_num = 32'd1024;
reg [17:0] data_men[1:data_num];
initial begin
$readmemb("D:/PRJ/vivado/simulation_ding/009_lpf6tap/matlab/sin_data.txt",data_men);
end
integer i = 1;
always @(posedge clk) begin
datin <= data_men[i];
i <= i + 8'd1;
end
initial begin
clk <= 0;
rst <= 0;
datin <= 0;
coef <= 0;
#4
coef <= {-25'd15,25'd19,25'd123,25'd123,25'd19,-25'd15};
#6000
$stop;
end
always #2 clk = ~clk;
winfilter wininst(
.coef(coef),
.datin(datin),
.clk(clk),
.rst(rst),
.datout(datout)
);
endmodule
其中dsp48参数设置:
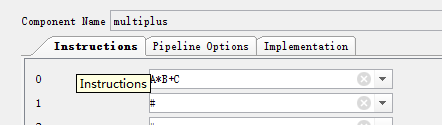
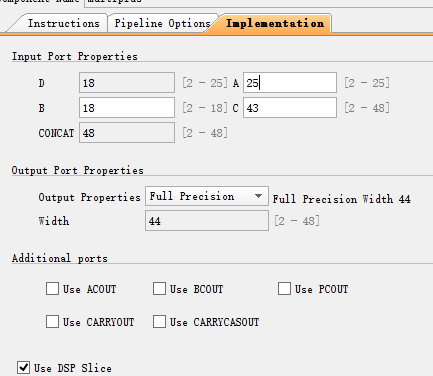
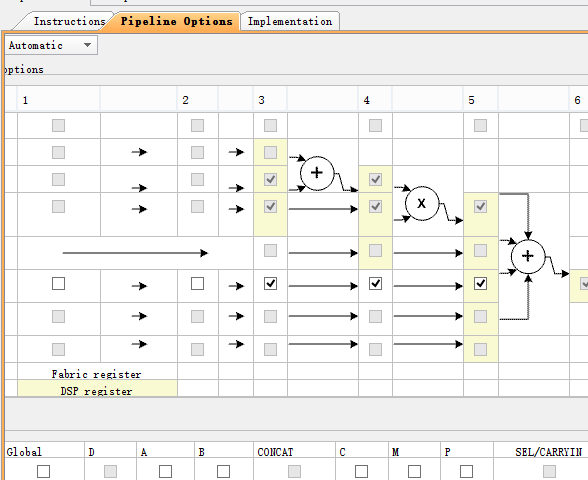
仿真结果: