本文首发于:行者AI
随着二次元文化的发展,虚拟偶像越发火热。
虚拟偶像技术主要包含歌唱合成和舞蹈生成,即能唱和能跳。
本文针对舞蹈生成,选择发表在ICLR2021的《Dance Revolution: Long Sequence Dance Generation with Music via Curriculum Learning》予以介绍,该论文由复旦大学、微软、美团和Rinna AI合作完成。
1. 舞蹈生成
舞蹈生成(Dance Generation),输入一段音乐序列(往往是音频特征),得到一段同样时长有意义的动作序列,即给音乐配舞蹈。下面将简单介绍音频特征和动作序列。
1.1 音频特征
音频的数据文件,由巨量的采样点组成。1秒钟音频可以达到上万个采样点,给模型训练带来巨大的困难。在实际使用中,音频一般不作为直接的输入输出,而是取音频的特征作为输入输出。
音频的常见特征有:
MFCC
MFCC delta
constant-Q chromagram
tempogram
在实际使用中,不需要详细了解上述音频特征,只需知道上述音频特征将音频的时间序列长度缩小了近百倍。
1.2 动作序列

图1. 动作序列提取图
动作序列是指姿态估计(pose estimation)生成的关于动作的时序数据,每个时间步的数据由关键点组成,用来表征人的肢体动作。如图1,纯色的点组成了当前动作的关键点,其连线能很好表征当前人物的肢体运动。(详情参见https://github.com/CMU-Perceptual-Computing-Lab/openpose)
动作序列可以只提取人物肢体运动,排除人物、背景等干扰音素,提取舞蹈动作,因而用动作序列表示舞蹈。
舞蹈是一种节奏很强的动作,除了上述常见特征,作者将鼓点的独热编码也视作音频特征,用于模型训练。
1.3 舞蹈生成问题定义
在了解了音频特征和动作序列后,这里给出舞蹈生成问题的定义。
对于给定的音乐-舞蹈数据集D,D由成对的音乐和舞蹈动作序列片段组成,音乐和舞蹈动作一一对应,X为音乐片段,Y为舞蹈动作片段。用D训练一个模型g(·),使得g(X)=Y。
这种输入序列输出序列的问题,被定义为序列到序列(Sequence-to-Sequence,简写为seq2seq)。相较于机器翻译序列到序列问题,音乐可以配很多舞蹈,没有唯一性,音乐更像是一种风格(style)。作者从seq2seq问题出发,所做的优化思路也是来自于seq2seq问题。
1.4 背景和动机
通过研究当前舞蹈生成的方法,作者发现现有的舞蹈生成有两种主要方式:
第一种是拼接方法(将不同舞蹈动作拼接起来)
第二种是自回归模型(如lstm等模型)
第一种方法缺少自然度,而第二种会受限于自回归模型的错误累积,只能生成较短的动作序列,因而作者提出两种方法来解决:
课程学习
局部注意力
这两种方法将在模型结构中进行介绍。
2. 模型结构
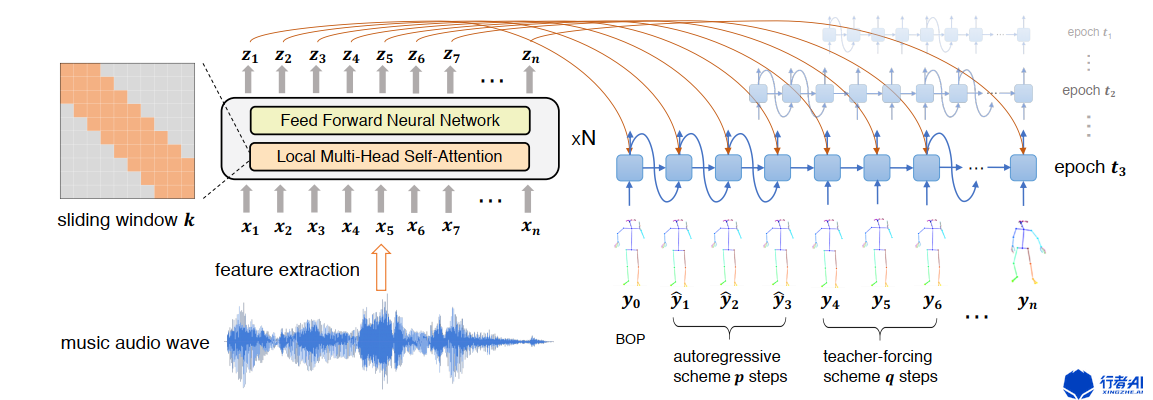
图2. 舞蹈生成模型结构图
如图2,该模型输入音频特征经过encoder和decoder得到动作序列。
下面将分别介绍encoder以及decoder。
2.1 encoder
encoder同一般的seq2seq问题,采用了类似transformer的架构,由N个transformer block组成,每个transformer block由multi-head self-attention和feed forward neural network串联组成。
局部注意力
音频是一个时间信号序列,相较于文本序列,音频的时间步更长,一句话最多上百字,但一个音频可以有百万个采样点,即使做了特征提取,音频的长度也在上千个左右。而transformer的multi-head self-attention模块计算复杂度为序列长度的平方,序列长度越长,计算所需资源越多。另一方面,音频满足短时不变性,对有意义的音频进行任意截取,截取的片段仍然有意义。因而,作者提出将全连接的self-attention变成局部的(local),如图2左上角,对每一个时间步的attention设置窗口大小,让模型只需计算前后k/2的数据。
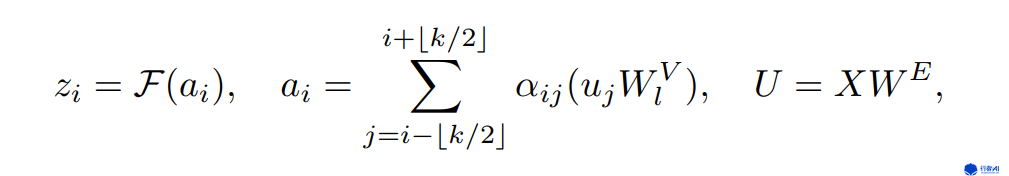
图3. 局部注意力公式
图3即为local multi-head self-attention的实现,相较于multi-head self-attention,local的实现只是在求和时加入范围限制,实际实现时只需要乘一个mask矩阵即可。
2.2 decoder
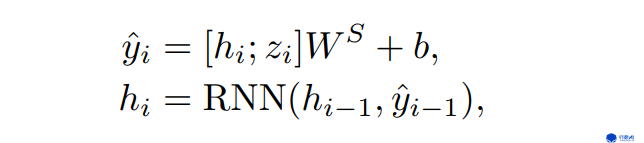
图4. decoder公式
图4为decoder的实现。decoder的backbone是普通的RNN网络,将上一个时间步的信息hi-1以及上一个RNN cell的隐状态yi-1作为输入,得到当前的RNN cell的隐状态hi,与encoder输出的当前时间步的隐状态zi拼接经过线性层得到最终输出yi。不同于机器翻译等自然语言问题,做推理时舞蹈生成不需要对当前时间步进行采样。
课程学习
课程式学习(curriculum learning)认为模型应当像人一样,学习应当从易到难。对于分类问题,课程学习应当先学习简单的样本,然后学习困难的样本;对于seq2seq问题,课程学习应当先学习短的序列,每次只去预测当前步的下一步(teach forceing),在模型训练到一定程度后,逐步开始增加后续预测的序列长度,比如增加到预测当前步的后两个时间步。paper作者对课程学习在舞蹈生成问题上做了改进,这里不作展开。
3. 评估标准
这篇paper提出的模型相较简单,亮点在于评估的标注标准。
舞蹈生成类似语音合成,常用的评估方法分为两类:客观评估和主观评估。
客观评估从测试数据角度,评估生成的舞蹈的真实性、风格一致性以及与配乐的匹配。
3.1 Fréchet Inception Distance
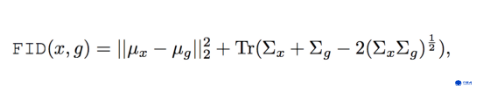
图5. FID计算公式
图5是Fréchet Inception Distance的计算公式。Fréchet Inception Distance简称FID,用于计算两个分布的相似度。原理是,假设两个高斯分布的矩阵,其均值和协方差越相近,则这两个矩阵越相似。如上图公式,μ是均值,∑是协方差,Tr 表示矩阵对角线上元素的总和。
在舞蹈生成中,FID用于和真实舞蹈整体的相似程度,即舞蹈的真实性。
3.2 ACC
用来评估舞蹈生成与音乐风格的一致程度。训练一个MLP(多层感知机)来对真实舞蹈进行分类(例如芭蕾、嘻哈、流行,类别来自于音乐分类),用MLP对生成的舞蹈进行分类,并评估是否与音乐的类别一致。
3.3 Beat Coverage
节拍覆盖度(Beat Coverage)为舞蹈动作节拍总数与音乐节拍总数的比率。节拍覆盖率越高,舞蹈的节奏型越强。
3.4 Beat Hit Rate
节拍命中率(Beat Hit Rate)为所有运动节拍中,命中音乐节拍数量占动作节拍总数的比率。命中率越高,舞蹈动作越契合音乐。
3.5 Diversity
多样性(Diversity ),在测试集上根据音乐生成一些舞蹈,评估这些舞蹈整体的多样性。
3.6 Multimodality
多态性(Multimodality),根据单个音乐生成多个舞蹈,评估这些舞蹈整体的多样性。
上述很多评估标准来自《Dancing to Music Neural Information Processing Systems》,如果想全面了解舞蹈生成领域,笔者建议阅读这篇paper。
3.7 主观评估标准
3.1至3.6介绍的标准均为客观评估标准。舞蹈好坏的很多方面是难以量化的,需要人工评估,即主观评估。主观评估:找多位专业舞者,播放提出模型生成的舞蹈、对比模型生成的舞蹈以及真实的舞蹈,并问如下三个问题,舞者进行打分。
- 真实性:抛开音乐而言,哪个舞蹈更真实?
- 丝滑性:抛开音乐而言,哪个舞蹈更丝滑?
- 匹配性:就风格而言,哪个舞蹈更与音乐相匹配?
组织者对每个音频三项指标的打分进行平均,得到最终评估结果。
4. 总结
这篇论文提出了一个SOTA的舞蹈生成模型,生成的舞蹈相较于前人研究,接近真人舞蹈。论文作者给出了示例视频:https://www.youtube.com/watch?v=lmE20MEheZ8
从这个视频我们也能看到目前舞蹈生成的不足:
- 生成的舞蹈可能违反人类生理结构:从视频中可以看到很多扭曲的手臂,是正常人无法做到的动作。
- 舞蹈生成帧率太低:本篇论文模型帧率为15 FPS ,远低于视频正常的帧率。
- 舞蹈生成没有实时性:由于模型生成速度慢,达不到实时生成的速度要求;模型多采用seq2seq架构,先对音乐整体编码,再逐步解码,没有考虑到实时性的需求。
- 生成质量有待提升:即使是业余的人,在看这篇论文的示例视频时,仍能看到很多不和谐的肢体动作。
舞蹈生成从去年开始进入热潮,生成的舞蹈质量一直在提高,近期谷歌发布了《Learn to Dance with AIST++》,慧夜科技发布了《DanceNet3D:DanceNet3D: Music Based Dance Generation with Parametric Motion Transformer》,舞蹈生成作为实现虚拟偶像的重要技术,备受重视。
通过关注当前舞蹈生成的研究,笔者也发现了舞蹈生成的热点:
- 更优质的数据集
- 3D舞蹈生成
- transformer base模型结构
- 更高帧率
舞蹈生成是行者AI虚拟偶像研究的一部分。笔者和其他研究者们在不断探索新的方法和评估标准,欢迎广大同行交流与合作,以及加入。
PS:更多技术干货,快关注【公众号 | xingzhe_ai】,与行者一起讨论吧!