【插入图片,妹子图首页】
哈,只敢放到这个地步了。
今天给直男们送点福利,通过今天的代码,可以把你的硬盘装的满满的~
下面就开始咯!
第一步:如何获取一张图片
假如我们知道某张图片的url,如何获取到这张图片呢?
先看一下最简单的方法:
【插入图片,单页url】
我们获取到图片的内容,通过二进制流写入到文件中,并保存起来。
这次偷懒啦,将所有图片都保存在当前目录下。
import requests
url='http://i.meizitu.net/2017/11/24a02.jpg'
pic=requests.get(url).content
pic_name=url.split(r'/')[-1]
with open(pic_name,'wb') as f:
f.write(pic)
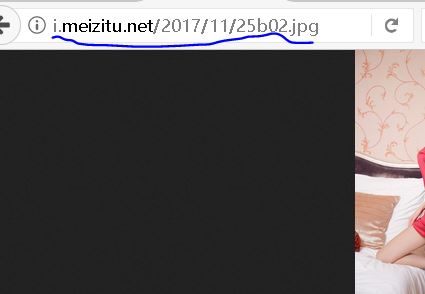
竟然出错了,得到的图片竟然是这样的:
【插入图片,反爬虫-防盗链】

看来现在各种网站都开始反爬虫了,我们尝试一下加入一些伪装信息。
估计是很多骚动青年都拿妹子图来练习爬虫了。。。
经过探索,加入referer头信息,才能继续下载,这个referer对应的内容是该图片的母地址,也就是存放这个图片的网页的地址。
可以啦,我们得到图片了,代码如下,做了一些修改,不直接打开图片地址了,而是打开单页图片所在的网页的地址。
import requests
import re
pic_parent='http://www.mzitu.com/109942/2'
def save_one_pic(pic_parent):
pic_path=pic_parent.split(r'/')[-2]
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
headers['Referer'] = pic_parent#新增属性,否则得不到图片
html=requests.get(pic_parent,headers=headers).text
pattern=re.compile(r'<img src="(h.*?)" alt')
pic_url=re.findall(pattern,html)[0]#匹配单页图片地址
pic = requests.get(pic_url, headers=headers).content
pic_name =pic_path+'_'+pic_url.split(r'/')[-1]
with open(pic_name, 'wb') as f:
f.write(pic)
if __name__=='__main__':
save_one_pic(pic_parent)
第二步:获取某模特的所有图片url并保存
第一步,我们学会了保存一页图片。
但是每个模特一般都会有几十张照片的,如果一次获取该模特的所有照片的?
【插入图片,模特多页】
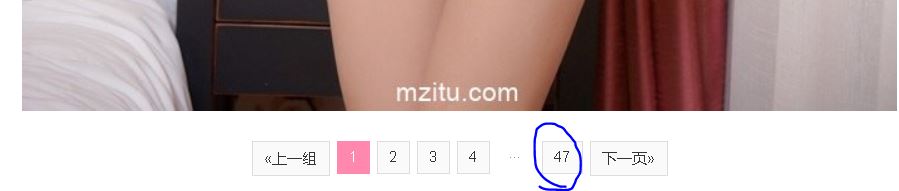
其实很方便,跟之前的项目一样,只要把url做一点修改就好了
http://www.mzitu.com/110107/3
最后一位更改一下就行啦。
当然,我们首先要获取到该模特图片的总数量,还是用正则匹配出来。
代码如下:
def get_one_volume_pic(pic_volume_url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
html = requests.get(pic_volume_url, headers=headers).text
pattern=re.compile(r"(.*)<span>(d+?)</span></a><a href='(.*?)'><span>下一页")
max_no=int(re.findall(pattern,html)[0][-2])#对list进行操作,可以百度一下用法
first_name=pic_volume_url.split('/')[-1]
#print(first_name)
#print(max_no)
print('--开始保存:',first_name)
p=Pool()
p.map(save_one_pic,[pic_volume_url+'/'+str(i) for i in range(1,max_no+1)])
# for i in range(max_no+1):
# url=pic_volume_url+str(i)
# save_one_pic(url)
print('--',first_name,',保存完成')
第三步:获取某一页面上所有模特的照片
【插入图片,首页多页】

http://www.mzitu.com/page/2/
每一页中都有很多模特的图片集合,我们要获得这一页中每一位模特的url入口,才能使用第二步的方法来下载图片。
【插入图片,模特url入口】

#保存基本页面上的第pageNo页
def get_one_volume_all_pic(page_No):
url=base_url+str(page_No)
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
html = requests.get(url, headers=headers).text
pattern=re.compile(r'<li><a href="(.*?)" target')
url_list=re.findall(pattern,html)
#print(url_list)
print('开始保存第',page_No,'页!')
for url in url_list:
get_one_volume_pic(url)
第四步:获取主页中最大的页码数
由于图片数量巨大,我们尽量不要一次完全下载。
要想下载指定数量的页面,需要获取页面数量。
这个方法跟第二步中的方法差不多,请参考。
base_url='http://www.mzitu.com/page/'#需要加页码
def get_max_page(base_url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
html = requests.get(base_url+'1', headers=headers).text
#print(html)
pattern=re.compile(r"<a class='page-numbers'(.*?)</span>(d+?)<span class=(.*?)></span></a>")
max_no=re.findall(pattern,html)[-1][-2]
#print(max_no)
return max_no
全部代码
终于完成了,代码虽然不多,不断的在出错,调试,还是很费时间的。
目前所有的图片都保存在当前文件夹下面,后面要改进一下,每个volume都单独建一个文件夹 ,这样就好看一些了。
import requests
import re
from multiprocessing import Pool
base_url='http://www.mzitu.com/page/'#需要加页码
def save_one_pic(pic_parent):
pic_path=pic_parent.split(r'/')[-2]
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
html=requests.get(pic_parent,headers=headers).text
pattern=re.compile(r'<img src="(h.*?)" alt')
pic_url=re.findall(pattern,html)[0]
headers['Referer'] = pic_parent # 新增属性,否则得不到图片
pic = requests.get(pic_url, headers=headers).content
pic_name =pic_path+'_'+pic_url.split(r'/')[-1]
with open(pic_name, 'wb') as f:
f.write(pic)
print('------保存成功:',pic_name)
def get_one_volume_pic(pic_volume_url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
html = requests.get(pic_volume_url, headers=headers).text
pattern=re.compile(r"(.*)<span>(d+?)</span></a><a href='(.*?)'><span>下一页")
max_no=int(re.findall(pattern,html)[0][-2])
first_name=pic_volume_url.split('/')[-1]
#print(first_name)
#print(max_no)
print('--开始保存:',first_name)
p=Pool()
p.map(save_one_pic,[pic_volume_url+'/'+str(i) for i in range(1,max_no+1)])
# for i in range(max_no+1):
# url=pic_volume_url+str(i)
# save_one_pic(url)
print('--',first_name,',保存完成')
#保存基本页面上的第pageNo页
def get_one_volume_all_pic(page_No):
url=base_url+str(page_No)
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
html = requests.get(url, headers=headers).text
pattern=re.compile(r'<li><a href="(.*?)" target')
url_list=re.findall(pattern,html)
#print(url_list)
print('开始保存第',page_No,'页!')
for url in url_list:
get_one_volume_pic(url)
def get_max_page(base_url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
html = requests.get(base_url+'1', headers=headers).text
#print(html)
pattern=re.compile(r"<a class='page-numbers'(.*?)</span>(d+?)<span class=(.*?)></span></a>")
max_no=re.findall(pattern,html)[-1][-2]
#print(max_no)
return max_no
if __name__=='__main__':
max_no=get_max_page(base_url)
print('目前妹子图一共有{0}页!'.format(max_no))
No=int(input('请输入您想下载多少页的内容:'))
for i in range(1,No+1):
get_one_volume_all_pic(i)
看看结果哈!
【插入图片,结果】
内容比价劲爆,就不开预览了,直男们下载好python,试一试把,把你的硬盘装满~~~
