安装selenium和下载webdriver
安装selenium
- pip install selenium
- pip install selenium -U (判断是否有最新版本)
下载driver
Google: http://npm.taobao.org/mirrors/chromedriver/ 或者是 https://chromedriver.storage.googleapis.com/index.html 打开找到对应的浏览器驱动下载
firefox:https://github.com/mozilla/geckodriver/releases打开找到对应的浏览器驱动下载
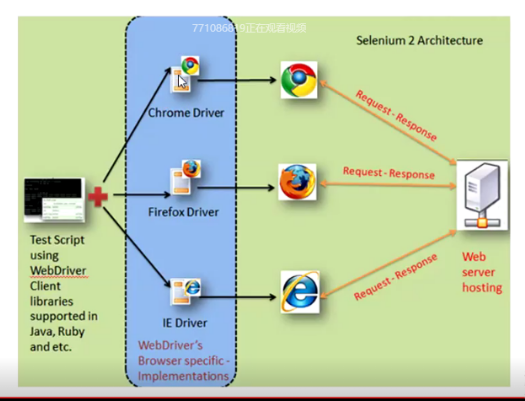
一个百度小demo
#!/usr/bin/env python # -*- coding: utf-8 -*- """ __title__ = __Time__ = 2020/6/17 13:48 __Author__ = xinhua __Blog__ = https://www.cnblogs.com/xinhua/ """ import time from selenium import webdriver # 加载浏览器驱动 driver = webdriver.Chrome(r"C:python3.6chromedriver.exe") # 访问网址 driver.get("http://www.baidu.com") # 找到搜索框 inputElement = driver.find_element_by_id("kw") # 输入搜索内容 inputElement.send_keys("xinhua19") # 找到搜索按钮 searchElement = driver.find_element_by_id("su") # 点击搜索按钮 searchElement.click() time.sleep(5) # 释放资源, 退出浏览器 driver.quit()
总结
可以看到,流水账式写Web自动化测试代码的顺序就是:加载驱动 - 访问链接 - 页面操作
元素定位八种方式
首先我们可以搭建1个禅道,后续演示可以使用禅道,禅道地址是IP:port/zentao,禅道搭建方法可以参考我的另外一篇博客https://www.cnblogs.com/xinhua19/p/13151296.html
方法一 :通过元素id定位
1 # 找到id=account的元素 2 username = driver.find_element_by_id("account") 3 # 输入值 4 username.send_keys("admin")
知识点:在前端,一般id是唯一的,只属于1个元素,通过id定位到的元素是唯一的
方法二:通过元素的class
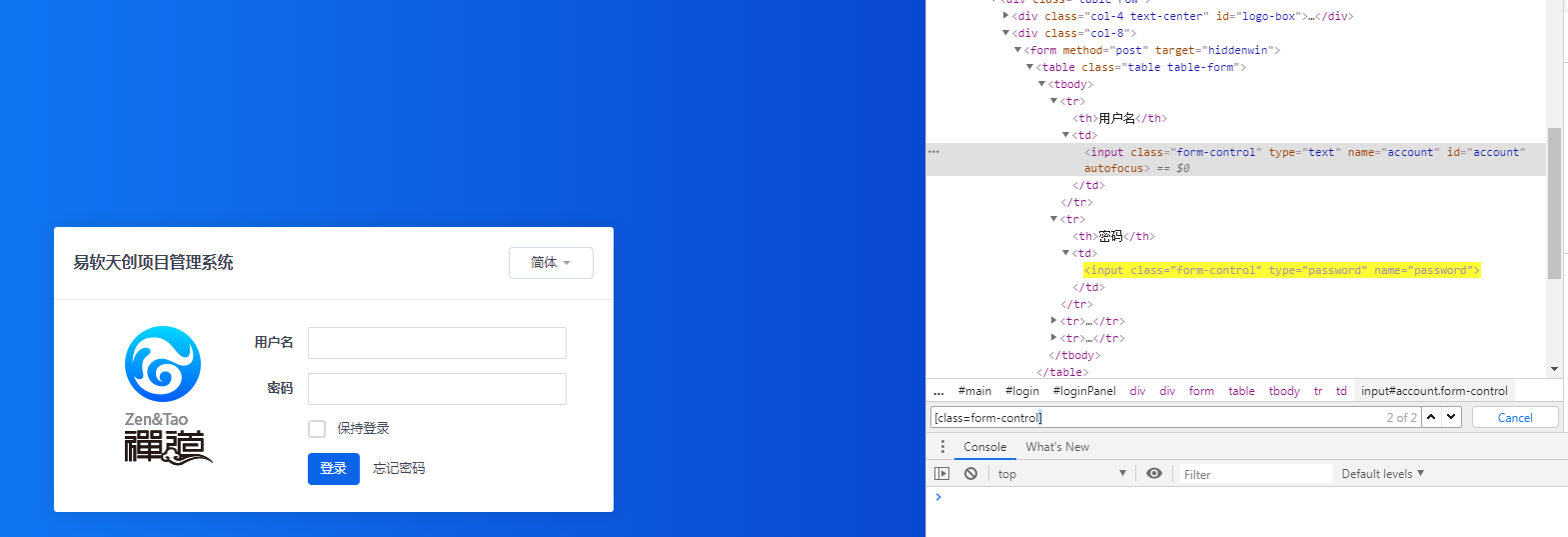
1 # 通过 元素Class查找(仅返回匹配到的第一个) 2 username = driver.find_element_by_class_name("form-control") 3 username.send_keys("admin")
知识点
- 在前端,一般多个元素共用一个class
- 但 find_element_by_class_name 只返回第一个匹配到class的元素
- 坏处:当找不到元素则报错
- 如果想返回所有匹配到class的元素,可看下面代码
1 elements = driver.find_elements_by_class_name("form-control") 2 for i in elements: 3 print(i)
知识点
- 返回的是一个元素列表,若只匹配到一个也是列表
- 好处:当没有找到元素时不会报错,而是返回空列表 []
方法三:通过元素的name
1 # 通过 元素name查找元素(仅返回匹配到的第一个) 2 password = driver.find_element_by_name("password") 3 password.send_keys("123")
知识点
- 和class一样,也有可能有多个元素共用一个name
- 但 find_element_by_name 只返回第一个匹配到name的元素
- 想返回多个的话,和class一样,需要调用 find_elements_by_name 方法,这里不再赘述,写法和上面一致
方法四:通过元素标签tag_name
1 # =====通过 元素标签(仅返回匹配到的第一个)===== 2 p = driver.find_element_by_tag_name("th") 3 # 打印元素的文本值 4 print(p.text) 5 6 print("===分割线") 7 # =====通过 元素标签(返回匹配到的所有元素)===== 8 ps = driver.find_elements_by_tag_name("th") 9 for p in ps: 10 print(p.text)
执行结果
1 用户名 2 ===分割线 3 用户名 4 密码
知识点
- 多个元素同种HTML标签见怪不怪了
- 同样的, find_element_by_tag_name 返回第一个匹配到标签的元素
- find_elements_by_tag_name 可以返回所有匹配到标签的元素
方法五:通过超链接文本link_text(精确匹配)
atext = driver.find_element_by_link_text("创建账号")
- find_element_by_link_text 是精确匹配,需要文本完全相同才能匹配
- 若需要返回全部匹配到的元素,也需要用 find_elements_by_link_text
方法六:通过超链接文本(模糊匹配)
# =====通过 超链接的文本查找元素(支持模糊匹配)
atext = driver.find_element_by_partial_link_text("肺炎")
- find_element_by_partial_link_text 支持模糊匹配,包含文本则匹配成功
- 若需要返回全部匹配到的元素,也需要用 find_elements_by_partial_link_text
方法七:通过xpath(万能,重点)
1 # 通过xpath
2 lis = driver.find_element_by_xpath('//ul[@class="timeline timeline-sm"]/li/a[@href="/zentao/tutorial-index--createAccount.html"]')
方法八:通过CSS选择器(万能,重点)
1 # 通过css 2 lis = driver.find_element_by_css_selector('a[href="/zentao/tutorial-index--createAccount.html"]') 3 print(lis.text)
其中Xpath,CSS包含的知识点很多,后续再讲