目的:学习使用JavaScript完成一些数据结构和常规算法的实现。(本书也是基于ES6标准的)
内容:
注:关于本博客的相关数据结构与算法的基本实例JS代码在我的其他博客上。欢迎一起讨论:)
所有源码在我的Github上(如果觉得不错记得给星鼓励我哦):JavaScript数据结构与算法
第一阶段:前言
1、第一章:JavaScript简介。JS的环境搭建和调试工具IDE及JS基础。(如果之前看过红宝书或者是有JS基础的,这个部分可以快速阅读)JS的ES6环境要配置好。此外,里面有提到一个Web服务器http-server,它是一种命令行 http服务器,用于本地测试和开发,建议安装使用,很有意思。
2、第二章:ECMAScript和TypeScipt的概述。主要说的是ES6的JS和ES6转码为ES5的Babel转码器;ES6的新特性。(如果之前有看过《ES6标准入门》等ES6书籍,以上部分可以快速阅读;如果没有还是得细看,毕竟本书是基于ES6一些新特性去写JS的)TypeScipt,TS是一个渐进式包含类型的JS的超集,建议安装,非常有用,例如它的tsc命令可以把.ts文件编译为.js文件,并且在编译进行了类型和错误检测,对我们开发写JS很有帮助。在常规使用JS在编译时在第一行加上//@ts-check可以进行错误检测。此外,ES6模块导入的配置环境和方法要弄清楚。
第二阶段:数据结构
1、第三章,数组。数组的构建,操作方法(在收、尾、任意数组位置进行添加、删除元素等),像fibonacci函数、多维数组的构建与访问的实现可以动手练习一下。此外,数组在ES6新添的方法也要好好理解,还有数组的排序、搜索。
2、第四章,栈。栈stack可以当作为一种具有特殊行为的数组。栈是遵循后进先出(FILO)原则,新添或删除元素都是在栈顶完成。(相对地,另一端就叫做栈底)本章要掌握对栈的操作,如push,pop,对栈顶元素的操作,清空栈等。此外,如何让自己的Stack类的用户只能访问我们在类中暴露的方法是要用JS实现私有属性的方法,例如在第八章说到的WeakMap类型(Map),但是其可读性不强,在扩展该类时无法继承私有属性。
3、第五章,队列。队列queue是遵循先进先出(FIFO)原则的一组有序的项。同样要掌握以该原则下的对队列的操作,例如增加新元素在队尾,删除元素在队头等。双端队列deque,是一种允许同时从前端和后端增加和删除元素的特殊队列。由于双端队列同时遵守了先进先出和后进先出原则,可以说它是把队列和栈结合的一种数据结构。队列的应用有:循环队列(击鼓传花游戏),回文检查器,JavaScript任务队列,例如当我们在浏览器中打开新标签时,就会创建一个任务队列,因为每个标签都是单线程处理的所有任务,即事件循环。
4、第六章,链表。链表存储有序的元素集合,与数组不同,链表中的元素在内存中并不是连续放置的,每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(指针或链接)组成。对链表的基本操作有增加元素,指定位置插入元素,删除元素,返回某元素的索引,查找某元素等。链表最后一个节点的下一个元素始终是undefined或null。链表的变体还有双向链表,循环链表,有序链表。双向链表是每两个节点间,链接不是单向,而是双向的:一个链向下一个元素,另一个链向上一个元素。循环链表可以由链表或者是双向链表扩展,它最后一个元素指向下一个元素的指针不是引用undefined,而是指向第一个元素。有序链表是指保持元素有序的链表结构。我们可以使用链表类及其变种作为内部的数据结构来创建其他数据结构,例如栈、队列、双向队列。当我们需要添加和移除很多元素时,最好的选择就是链表,而不是数组。
5、第七章,集合。集合是由一组无序且唯一(即不能重复)的项组成的。在ES6也提供了原生的Set类,但也懂其构建数据集合的数据结构(即基于ES5下,构建自己的Set类)。对Set的操作:添加、移除元素,判断元素是否在集合里,元素个数等和Set之间的交、并、差、子集等。ES6中的原生的Set没有交、并、差运算,需要我们自己写。同时,我们可以结合使用扩展运算符,把集合转为为数组,再对数组进行运算,再转回集合。注意一种多重集的概念。
6、第八章,字典和散列表。字典和散列表也是存储唯一值的数据结构。在集合中,我们感兴趣的是每个值本身(相当于[值,值]存储)。在字典(或映射)中,我们用[键,值]对的形式来存储数据。散列表也是一样,但两者的实现方式略有不同,例如字典中的每个键只能有一个值。字典也称作映射、符号表或关联数组。与Set类相似,ES6同样包含了一个Map类的实现,即我们所说的字典。由于JavaScript不是强类型的语言,不能保证键一定是字符串,所以需要把所有键名的传入的对象转换为字符串,使得Dictionary类中搜索和获取值更简单。字典类的操作:添加元素(覆盖之前同键名的元素),移除,获取,清除全体,返回所有键名,返回所有键值,返回所有键值对,迭代字典中所有的键值对。散列表,HashTable类或HashMap类,它是Dictionary类的一种散列表实现方式。散列算法的作用是尽可能快地在数据结构中找到一个值。(而不是像之前的数据结构,需要迭代整个数据结构)散列函数的作用是给定一个键值,然后返回在表中的地址。常用的应用就是对数据库进行索引和使用散列表来表示对象。JavaScript语言内部就是使用散列表来表示每个对象,此时,对象的每个属性和方法(成员)被存储为key对象类型,每个key指向对应的对象成员。有时候,一些键会有相同的散列值,不同的值在散列表中对应相同位置的时候,称为冲突。(冲突会导致散列表只保存最新的值,旧的值会被覆盖)解决冲突的几个方法是:分离链接、线性探查和双散列法。
7、第九章,递归。递归会使得操作树和图数据结构变得更简单。递归是一种解决问题的方法,它从解决问题的各个小部分开始,直到解决最初的大问题。递归通常涉及函数调用自身。每个递归函数都必须有基线条件,即一个不再递归调用的条件(停止点),以防无线递归。使用递归时,要找到原始问题和子问题是什么。例如阶乘的factorial(5)=5*factorial(4)。每当一个函数被一个算法调用时,该函数会进入调用栈(call stack)的顶部。当使用递归的时候,每个函数调用都会堆叠在调用栈的顶部,这是因为每个调用都可能依赖前一个调用的结果。如果忘记使用基线条件,递归并不会无限地执行下去,浏览器会抛出栈溢出错误(stack overflow error),每个浏览器都有自己的上限。ES6中有尾调用优化,如果函数内的最后一个操作是调用函数,会通过“跳转指令”(jump)而不是“子程序调用”(subroutine call)来控制,所以在ES6中,某些递归代码是一直执行下去,因此,停止递归的基线条件非常重要。斐波那契数列是另一个可以用递归解决的问题。
8、第十章,树。树也是一种非顺序数据结构,它对于存储需要快速查找的数据非常有用。数是一种分层数据的抽象模型。数的相关概念:节点,父子关系的节点(父节点和子节点),根节点,叶节点(外部节点),内部节点,树,子树,一个节点可以有祖先和后代(关系)。节点的一个属性叫深度,取决于它的祖先节点的数量。树的高度取决于所有节点深度的最大值。根节点在第0层。二叉树中的节点最多只能有两个子节点(左侧子节点和右侧子节点)。二叉搜索树(BST)是二叉树的一种,只允许在左侧节点存储(比父节点)小的值,在右侧节点存储(比父节点)大的值。树中,通过指针(引用)来表示节点之间的关系(称为“边”)。树的每个节点也是有两个指针,一个指向左侧子节点,一个指向右侧子节点。键是树相关的术语中对节点的称呼。对树的操作,插入新的键,查找一个键,遍历(中序,先序和后序),找树中键值最大最小值,移除某个键。中序遍历的一种应用就是对数进行排序操作,先序遍历的一种应用就是打印一个结构化的文档,后序遍历的一种应用是计算一个目录及其子目录中所有文件所占空间的大小。BST存在一个问题:取决于我们添加的节点数,数的一条边可能会非常深。这会在需要在某条边上添加、移除和搜索某个节点时引起的一些性能问题。为解决这个问题,有一种树叫Adelson-Velskii-Landi树(AVL树)。AVL树是一种自平衡的二叉搜索树(任何一个节点左右两侧子树的高度之差最多为1)。此外,红黑树也是一个自平衡二叉搜索树(如果需要一个包含多次插入和删除的自平衡树,红黑树要优于AVL树)。
9、第十一章,二叉堆和堆排序。二叉堆是一种特殊的二叉树,其有两个特性:结构特性和堆特性。结构特性是指它是一颗完全的二叉树(树的每一层都有左侧和右侧子节点(除了最后一层的叶节点),并且最后一层的叶节点尽可能都是左侧子节点)。堆特性是指二叉堆不是最小堆就是最大堆(最小堆可以快速导出树的最小值,最大堆可以快速导出树的最大值),所有的节点都大于等于(最大堆)或者小于等于(最小堆)每个它的子节点。二叉堆常被应用于优先队列,也被用于著名的堆排序算法中。堆排序算法不是一个稳定的排序算法,如果数组没有排好序,可能会得到不一样的结果。
10、第十二章,图。图也是一种非线性数据结构。图是一组由边连接的节点(或顶点)。任何二元关系都可以用图来表示。图的相关术语(顶点;边;相邻顶点;顶点的度;路径;简单路径;环;无环;连通;有向图;无向图;强连通;加权;未加权)。图存在多种表示方式,图的正确表示法取决于待解决问题和图的类型(邻接矩阵;邻接表;关联矩阵)。图的遍历:广度优先搜索BFS和深度优先搜索DFS。图遍历可以用来寻找特定的顶点或寻找两个顶点之间的路径,检查图是否连通,检查图是否含有环等。图遍历算法的思想是必须追踪每个第一次访问的节点,并且追踪有哪些节点还没有被完全探索(需要明确指出第一个被访问的顶点)。完全探索一个顶点要求我们查看该顶点的每一条边。对于每一条边所连接的没有被访问过得顶点,将其标注为被发现的,并将其加进待访问顶点列表中。为保证算法的效率,务必访问每个顶点至多两次,连通图中每条边和顶点都会被访问到。BFS和DFS本质基本相同,不同在于待访问顶点列表的数据结构:BFS(栈),FBS(队列)。广度优先搜索算法会从指定的第一个顶点开始遍历图,先访问其所有的邻点(相邻顶点),就像一次访问图的一层(先宽后深地访问顶点)。使用BFS寻找最短路径(给定一个图G和源顶点v,找出每个顶点u和v之间最短路径的距离(以边的数量计))。上述的最短路径算法中,图不是加权的。如果要计算加权图中的最短路径,广度优先搜索未必合适,要考虑使用Dijkstra算法(解决单源最短路径问题)、Bellman-Ford算法(解决边权值为负的单源最短路径问题)、A*搜索算法(解决求仅一对顶点间的最短路径问题,用经验法则来加速搜索过程)、Floyd-Warshell算法(解决求所有顶点对之间的最短路径问题)。深度优先搜索算法将会从一个指定的顶点开始遍历图,沿着路径直到这条路径最后一个顶点被访问了,接着原路回退并探索下一条路径(先深度后广度地访问顶点)。对于给定的图G,我们希望深度优先搜索算法遍历图G的所有节点,构建“森林”(有根树的一个集合)以及一组源顶点(根),并输出两个数组:发现时间和完成探索时间。最小生成树(Prim算法、Kruskal算法)。
第三阶段:算法
1、第十三章,排序和搜索算法。冒泡排序比较所有相邻的两个项,如果第一个比第二个大,则交换他们。元素项向上移动至正确的顺序,就好像气泡升至表面一样。其复杂度是O(n2)。选择排序算法是一种原址比较排序算法。选择排序大致的思路是找到数据结构中的最小值并将其放置在第一位,接着找到第二小的值并将其放置在第二位,以此类推。插入排序每次排一个数组项,以此方式构建最后的排序数组。假定第一项已经排序了。接着,它和第二项进行比较--第二项是应该待在原位还是插入到第一项之前呢?这样,头两项就已正确排序,接着和第三项比较(它是该插入到第一、第二还是第三的位置呢),以此类推。其复杂度是O(n2)。归并排序是一种分而治之算法,其思想是将原始数组切分较小的数组,直到每个小数组只有一个位置,接着讲小数组归并成较大的数组,直到最后只有一个排序完毕的大数组。归并排序是第一个可以实际使用的排序算法,归并排序性能不错(比上三种排序好),其复杂度为O(nlogn)。快速排序也许是最常用的排序算法了,它的复杂度为O(nlog(n)),且性能通常比其他复杂度为O(nlog(n))的排序算法好。快速排序也是使用分而治之的思想,将原始数组分为较小的数组(但它没有像归并排序那样将它们分割开)。思路:选择主元(pivot);划分(partition)操作;对划分后的小数组重复前两步操作,直至数组已完全排序。计数排序是一个分布式排序,使用已经组织好的辅助数据结构(称为桶),然后进行合并,得到排好序的数组。计数排序使用一个用来存储每个元素在原始数组中出现次数的临时数组。在所有元素都计数完成后,临时数组已拍好序并可迭代以构建排序后的结果数组。它是一个优秀的整数排序算法,时间复杂度为O(n+k),其中k是临时计数数组的大小;但是它确实需要更多的内存来存放临时数组。桶排序(箱排序)也是分布式排序算法,它将元素分为不同的桶(较小的数组),再使用一个简单的排序算法,例如插入排序,来对每个桶进行排序。然后,它将所有的桶合并为结果数组。基数排序是一个分布式排序算法,它根据数字的有效位或者基数将整数分布到桶中。基数是基于数组中值的记数制的。顺序或线性搜索是最基本的搜索算法。它的机制是将每一个数据结构中的元素和我们要找的元素作比较(最低效)。二分搜索要求被搜索的数组已排序。步骤:1、选择数组中间值;2、如果选中值是待搜索值,那么算法执行完毕;如果带搜索值比选中值要小,则返回步骤1并在选中值左边的子数组中寻找(较小);4、 如果带搜索值比选中值要大,则返回步骤1并在选中值右边的子数组中寻找(较大)。 内插搜索是改良版的二分搜索。步骤:1、使用position公式选中一个值;2、如果选中值是待搜索值,那么算法执行完毕;如果带搜索值比选中值要小,则返回步骤1并在选中值左边的子数组中寻找(较小);4、 如果带搜索值比选中值要大,则返回步骤1并在选中值右边的子数组中寻找(较大)。随机算法就是将一个数组中的值进行随机排序,如Fisher-Yaters随机算法。
2、第十四章,算法设计与技巧。主要的算法思想有:分而治之,动态规划,贪心算法,回溯算法等。分而治之算法可以分为三个部分。1、分解原问题为多个子问题(原问题的多个小实例);2、解决子问题,用返回解决子问题的方式的递归算法。递归算法的基本情形可以用来解决子问题;3、组合这些子问题的解决方式,得到原问题的解。动态规划(dynamic programming,DP)是一种将复杂问题分解成更小的子问题来解决的优化技术(分而治之方法是把问题分解成相互独立的子问题,然后组合它们的答案;而动态规划是将问题分解成相互依赖的子问题)。用动态规划解决问题时,要遵循三个重要步骤:1、定义子问题;2、实现要反复执行来解决子问题的部分(考虑递归);3、识别并求解出基线条件。动态规划能解决一些著名算法问题:背包问题, 最长公共子序列,矩阵链相乘,硬币找零, 图的全源最短路径。本书之前用的编程范式都是命令式编程,ES6也有一种新的范式,叫做函数式编程(FP)。函数式编程的主要目标是描述数据,以及要对数据应用的转换;在函数式编程中,程序执行顺序的重要性很低,而在命令式编程中,步骤和顺序时非常重要的;函数和数据集合是函数式编程的核心;在函数式编程中,我们可以使用和滥用函数和递归,而在命令式编程中,则使用循环、赋值、条件和函数;在函数式编程中,要避免副作用和可变数据,意味着我们不会修改传入函数的数据。
3、第十五章,算法复杂度。大O表示法将算法按照消耗的时间进行分类,依据随着输入增大所需要的空间/内存。当讨论大O表示法时,一般考虑的是CPU时间占用。复杂度比较如下图所示。NP完全理论。一般来说,如果一个算法的复杂度为O(n^k),其中k是常数,我们就可以认为这个算法是高效的,这就是多项式算法。对于给定的问题,如果存在多项式算法,则计为P(polynomial,多项式)。如果一个问题可以在多项式时间内验证解是否正确,则记为NP(nondeterministic polynomial,非确定性多项式)。如果一个问题存在多项式算法,自然可以在多项式时间内验证其解,所以的P都是NP,然而P=NP是否成立,仍然不得而知。NP问题中最难的是NP完全问题。如果满足以下两个条件,则称决策问题L是NP完全的:L是NP问题,即可以在多项式时间内验证解,但还没有找到多项式算法;所有的NP问题都能在多项式时间内归约为L。为了理解问题的归约,考虑两个决策问题L和M。假设算法A可以解决问题L,算法B可以验证输入y是否为M的解。目标是找到一个把L转化为M的方法,使得算法B可以用于构造算法A。还有一类问题,只需要满足NP完全问题的第二个条件,称为NP困难问题。不可解问题与启发式算法。
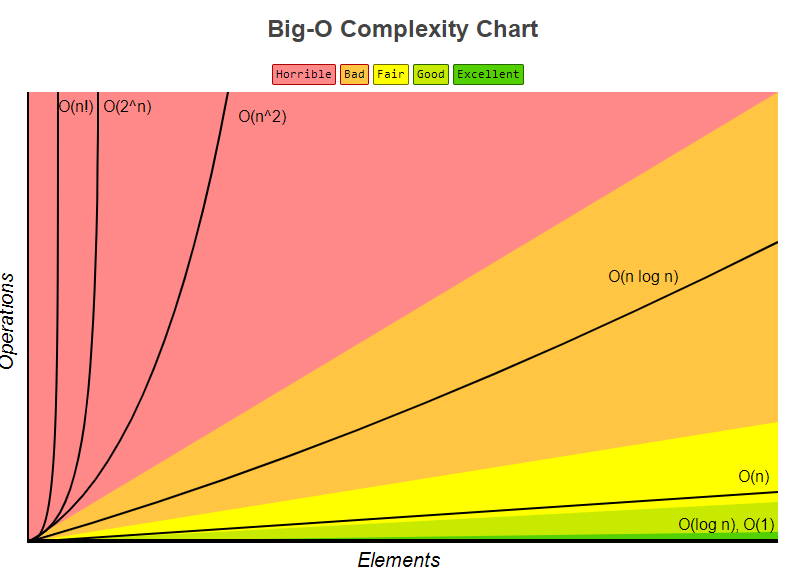
(大O图from https://www.bigocheatsheet.com/)