1.为什么要进行数据降维?
在实际的机器学习项目中,特征选择/降维是必须进行的,因为在数据中存在以下几个方面的问题:
- 数据的多重共线性:特征属性之间存在着相互关联关系。多重共线性会导致解的空间不稳定, 从而导致模型的泛化能力弱;
- 高纬空间样本具有稀疏性,导致模型比较难找到数据特征;
- 过多的变量会妨碍模型查找规律;
- 仅仅考虑单个变量对于目标属性的影响可能忽略变量之间的潜在关系。
通过特征选择/降维的目的是:
- 减少特征属性的个数
- 确保特征属性之间是相互独立的
当然有时候也存在特征矩阵过大, 导致计算量比较大,训练时间长的问题
降维的好处:
- 减小数据维度和需要的存储空间
- 节约模型训练计算时间
- 去掉冗余变量,提高算法的准确度
- 有利于数据可视化
2.SelectFromModel
这里举个鸢尾花的例子,鸢尾花有四个特征,但是并不是每个特征都是重要的,所以筛选一下,看哪个特征更最要
1 # 导包 2 # 特征选择需要的包 3 from sklearn.feature_selection import SelectFromModel 4 # 一些模型 5 from sklearn.linear_model import LogisticRegression 6 from sklearn.tree import DecisionTreeClassifier 7 from sklearn.neighbors import KNeighborsClassifier 8 9 from sklearn import datasets 10 11 import numpy as np 12 13 import warnings 14 warnings.filterwarnings('ignore')
1 X,y = datasets.load_iris(True) 2 3 estimator=LogisticRegression() 4 # max_features保留几个特征 estimator模型 threshold 阈值 5 sfm=SelectFromModel(estimator=estimator,threshold=-np.inf,max_features=2) 6 X2=sfm.fit_transform(X,y) 7 X2[:10]
筛选出来的结果:

原结果:X[:10]

可以看出,第三个特征和第四歌特征被挑选出来,可见他们的重要性高
1 # 系数,相当于权重 2 np.abs(sfm.estimator_.coef_).mean(axis = 0)
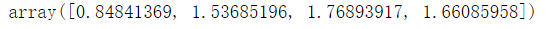
运行结果可以看出来,3,4的权重大
1 # 特征的重要程度 2 sfm.estimator_.feature_importances_

1 # 方差 2 from sklearn.feature_selection import VarianceThreshold 3 4 vt = VarianceThreshold(threshold=0.68) 5 X3 = vt.fit_transform(X,y) 6 X.var(axis = 0)

根据方差筛选的话,挑选出来的是1,3特征
3.SelectKBest
这个其实是统计学中的卡方验证
1 from sklearn.datasets import load_iris 2 from sklearn.feature_selection import SelectKBest 3 from sklearn.feature_selection import chi2 4 5 iris = load_iris() 6 X, y = iris.data, iris.target 7 8 # k=2 选择两个最高的分数对应的属性 9 # chi 是统计学中的卡方验证,测试随机变量之间的相关性 10 X_new = SelectKBest(chi2, k=2).fit_transform(X, y) 11 X_new.shape 12 13 X[:10] 14 X_new[:10]
根据卡方分布,挑选出来的依旧是3,4属性
验证一下:
1 chi2(X,y)

4.RFE 递归特征消除
1 from sklearn.feature_selection import RFE 2 from sklearn.tree import DecisionTreeClassifier 3 4 estimator=DecisionTreeClassifier() 5 rfe=RFE(estimator) 6 X2=rfe.fit_transform(X,y) 7 X2[:10] 8 9 model=rfe.estimator_ 10 model.feature_importances_ 11 12 estimator.fit(X,y) 13 estimator.feature_importances_
model.feature_importances_
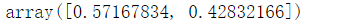
estimator.feature_importances_

5.补充一下卡方检验和卡方分布
卡方检验:
卡方检验是用途非常广的一种假设检验方法,它在分类资料统计推断中的应用,包括:两个率或两个构成比比较的卡方检验;多个率或多个构成比比较的卡方检验以及分类资料的相关分析等。
计算公式:

这里等博主学习后回来更新.......