参考:https://blog.csdn.net/qq_34106574/article/details/82016442
import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn.preprocessing import StandardScaler from sklearn.datasets import make_moons, make_circles, make_classification from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_split from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as QDA %matplotlib inline h = .02 # step size in the mesh #最近邻、线性支持向量机、RBF支持向量机、决策树、随机森林、AdaBoost、朴素贝叶斯、LDA、QDA names = ["Nearest Neighbors", "Linear SVM", "RBF SVM", "Decision Tree", "Random Forest", "AdaBoost", "Naive Bayes", "LDA", "QDA"] classifiers = [ KNeighborsClassifier(3), SVC(kernel="linear", C=0.025), SVC(gamma=2, C=1), DecisionTreeClassifier(max_depth=5), RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1), AdaBoostClassifier(), GaussianNB(), LDA(), QDA()] """ make_classification用于生成数据样本 n_features:特征个数=n_informative()+n_redundant+n_repeated n_informative:多信息特征的个数 n_redundant:冗余信息,informative特征的随机线性组合 n_repeated:重复信息,随机提取n_informative和n_redundant特征 n_classes:分类类别 n_clusters_per_class:某一个类别是由几个cluster构成的 weights:列表类型,权重比 class_sep:乘以超立方体大小的因子。较大的值分散了簇/类,并使分类任务更容易。默认为1 random_state: 如果是int,random_state是随机数发生器使用的种子; 如果RandomState实例,random_state是随机数生成器; 如果没有,则随机数生成器是np.random使用的RandomState实例。 返回值: X:形状数组[n_samples,n_features] 生成的样本。 y:形状数组[n_samples] 每个样本的类成员的整数标签。 """ X, y = make_classification(n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=1) rng = np.random.RandomState(2) X += 2 * rng.uniform(size=X.shape) linearly_separable = (X, y) #生成三种形式的数据,月亮型、圆型、线性可分型 datasets = [make_moons(noise=0.3, random_state=0), make_circles(noise=0.2, factor=0.5, random_state=1), linearly_separable ] #创建一个新的图表,参数是尺寸,单位为英寸。 figure = plt.figure(figsize=(27, 9)) i = 1 # iterate over datasets #遍历数据集 for ds in datasets: # preprocess dataset, split into training and test part #取得数据集和标签 X, y = ds #StandardScaler:去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本。 X = StandardScaler().fit_transform(X) #划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4) x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 #np.meshgrid:从坐标向量中返回坐标矩阵 """ 直观理解: 二维坐标系中,X轴可以取三个值1,2,3, Y轴可以取三个值7,8, 请问可以获得多少个点的坐标? 显而易见是6个: (1,7)(2,7)(3,7) (1,8)(2,8)(3,8) """ xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # just plot the dataset first ## 绘图库中的颜色查找表。比如A1是红色,A2是浅蓝色。 这样一种映射关系 cm = plt.cm.RdBu cm_bright = ListedColormap(['#FF0000', '#0000FF']) ax = plt.subplot(len(datasets), len(classifiers) + 1, i) # Plot the training points ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright) # and testing points ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6) ax.set_xlim(xx.min(), xx.max()) ax.set_ylim(yy.min(), yy.max()) ax.set_xticks(()) ax.set_yticks(()) i += 1 # iterate over classifiers for name, clf in zip(names, classifiers): ax = plt.subplot(len(datasets), len(classifiers) + 1, i) clf.fit(X_train, y_train) score = clf.score(X_test, y_test) # Plot the decision boundary. For that, we will assign a color to each # point in the mesh [x_min, m_max]x[y_min, y_max]. if hasattr(clf, "decision_function"): Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()]) else: Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1] # Put the result into a color plot Z = Z.reshape(xx.shape) ax.contourf(xx, yy, Z, cmap=cm, alpha=.8) # Plot also the training points ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright) # and testing points ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6) ax.set_xlim(xx.min(), xx.max()) ax.set_ylim(yy.min(), yy.max()) ax.set_xticks(()) ax.set_yticks(()) ax.set_title(name) ax.text(xx.max() - .3, yy.min() + .3, ('%.2f' % score).lstrip('0'), size=15, horizontalalignment='right') i += 1 figure.subplots_adjust(left=.02, right=.98) plt.show()
结果:
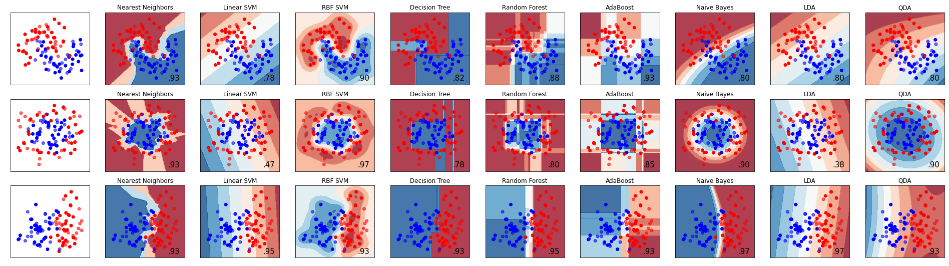
将其中的准确率用表格表示:
| 数据 | 最近邻 | 线性SVM | RBF-SVM | 决策树 | 随机森林 | Adaboost | 朴素贝叶斯 | LDA | QDA |
| 月型 | 0.93 | 0.78 | 0.90 | 0.82 | 0.88 | 0.93 | 0.80 | 0.80 | 0.80 |
| 圆型 | 0.93 | 0.47 | 0.97 | 0.78 | 0.80 | 0.85 | 0.90 | 0.38 | 0.90 |
| 线性型 | 0.93 | 0.93 | 0.95 | 0.93 | 0.95 | 0.93 | 0.97 | 0.97 | 0.93 |
当然,这仅仅是利用简单的模型试了试,并没有将每一个模型的参数都调至最优,但还是能说明一些问题的:
1、在数据是线性可分的情况下,各种方法的分类准确率差别都不是很大。
2、线性分类器对非线性可分的数据无能为力。
3、最近邻和RBF-SVM在三种数据上表现得都比较不错。