transformer综述:https://arxiv.org/pdf/2009.06732.pdf
transformer:Attention Is All You Need
基本构成:编码器+解码器
基本组件:
- 输入层:词嵌入+位置编码
- 隐含层:多头注意力机制、残差连接、前馈神经网络、层归一化
- 输出层:全连接+softmax
解码器和编码器的结构是大致相同的,但也有所区别: - q,k,v的来源不一样:交叉注意力机制
- masked多头注意力机制
其它变体:
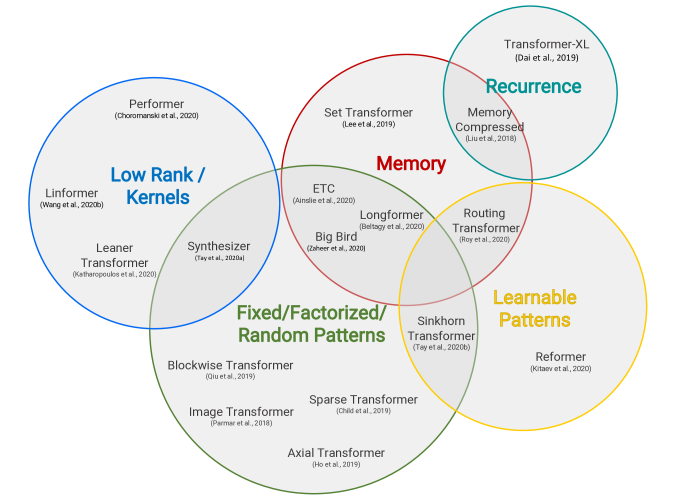
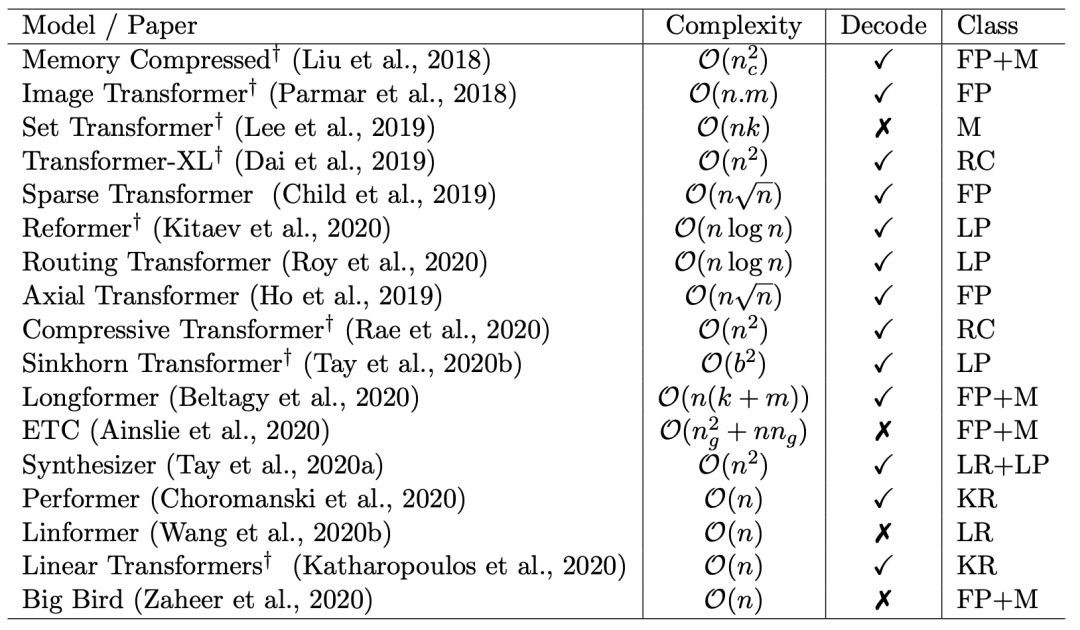
下面是一些变体的简介:
transformer-xl:Attentive Language Models Beyond a Fixed-Length Context
主要解决长序列的问题。
transformer存在的问题:
- 1)因为segments之间独立训练,所以不同的token之间,最长的依赖关系,就取决于segment的长度;2)出于效率的考虑,在划分segments的时候,不考虑句子的自然边界,而是根据固定的长度来划分序列,导致分割出来的segments在语义上是不完整的。
改进方法:
- 在对当前segment进行处理的时候,缓存并利用上一个segment中所有layer的隐向量序列,而且上一个segment的所有隐向量序列只参与前向计算,不再进行反向传播,这就是所谓的segment-level Recurrence。
- 采用相对位置编码,在计算当前位置隐向量的时候,考虑与之依赖token的相对位置关系。具体操作是,在算attention score的时候,只考虑query向量与key向量的相对位置关系,并且将这种相对位置关系,加入到每一层Trm的attention的计算中。
Compressive Transformers for Long-Range Sequence Modelling
基于transformer-XL 方法进行改进,通过压缩memory 使得模型可以处理更长的序列。
Sparse Transformer: Concentrated Attention Through Explicit Selection
vanilla Transformer对很多不相关的单词给予了很高的重视,而Sparse Transformer则集中在最相关的k个单词上。
Image Transformer
受卷积神经网络启发的Transformer变种,重点是局部注意范围,即将接受域限制为局部领域。
Longformer: The Long-Document Transformer
Sparse Transformer的变体,通过在注意力模式中留有空隙、增加感受野来实现更好的远程覆盖。
Etc: Encoding long and structured data in transformers
Sparse Transformer的变体,引入了一种新的全局本地注意力机制。
Big Bird: Transformers for Longer Sequences
与Longformer一样,同样使用全局内存,但不同的是,它有独特的“内部变压器构造(ITC)”,即全局内存已扩展为在sequence中包含token,而不是简单的参数化内存。
Efficient content-based sparse attention with routing transformers
提出了一种基于聚类的注意力机制,以数据驱动的方式学习稀疏注意力。
Reformer: The efficient transformer
一个基于局部敏感哈希(LSH)的注意力模型,引入了可逆的Transformer层,有助于进一步减少内存占用量
Sparse sinkhorn attention
这个模型属于分块模型,以分块的方式对输入键和值进行重新排序,并应用基于块的局部注意力机制来学习稀疏模式
Hat: Hardware-aware transformers for efficient natural language processing
这是基于低秩的自注意力机制的高效Transformer模型,主要在长度维度上进行低秩投影,在单次转换中按维度混合序列信息。
Transformers are rnns: Fast autoregressive transformers with linear attention
使用基于核的自注意力机制、和矩阵的关联特性,将自注意力的复杂性从二次降低为线性
Masked language modeling for proteins via linearly scalable long-context transformers
利用正交随机特征(ORF),采用近似的方法避免存储和计算注意力矩阵。
Synthesizer: Rethinking self-attention in transformer models
提出一种新的学习注意力权重的方式。该方法没有使用点积注意力或基于内容的注意力)。生成独立于token-token交互的对齐矩阵,并探索了一组用于生成注意力矩阵的参数化函数。
https://zhuanlan.zhihu.com/p/84159401
http://tech.sina.com.cn/csj/2020-09-21/doc-iivhuipp5559540.shtml