【关系抽取-R-BERT】加载数据集
【关系抽取-R-BERT】模型结构
【关系抽取-R-BERT】定义训练和验证循环
相关代码
import logging
import os
import numpy as np
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from tqdm import tqdm, trange
from transformers import AdamW, BertConfig, get_linear_schedule_with_warmup
from model import RBERT
from utils import compute_metrics, get_label, write_prediction
logger = logging.getLogger(__name__)
class Trainer(object):
def __init__(self, args, train_dataset=None, dev_dataset=None, test_dataset=None):
self.args = args
self.train_dataset = train_dataset
self.dev_dataset = dev_dataset
self.test_dataset = test_dataset
self.label_lst = get_label(args)
self.num_labels = len(self.label_lst)
self.config = BertConfig.from_pretrained(
args.model_name_or_path,
num_labels=self.num_labels,
finetuning_task=args.task,
id2label={str(i): label for i, label in enumerate(self.label_lst)},
label2id={label: i for i, label in enumerate(self.label_lst)},
)
self.model = RBERT.from_pretrained(args.model_name_or_path, config=self.config, args=args)
# GPU or CPU
self.device = "cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu"
self.model.to(self.device)
def train(self):
train_sampler = RandomSampler(self.train_dataset)
train_dataloader = DataLoader(
self.train_dataset,
sampler=train_sampler,
batch_size=self.args.train_batch_size,
)
if self.args.max_steps > 0:
t_total = self.args.max_steps
self.args.num_train_epochs = (
self.args.max_steps // (len(train_dataloader) // self.args.gradient_accumulation_steps) + 1
)
else:
t_total = len(train_dataloader) // self.args.gradient_accumulation_steps * self.args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in self.model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.args.weight_decay,
},
{
"params": [p for n, p in self.model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = AdamW(
optimizer_grouped_parameters,
lr=self.args.learning_rate,
eps=self.args.adam_epsilon,
)
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=self.args.warmup_steps,
num_training_steps=t_total,
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(self.train_dataset))
logger.info(" Num Epochs = %d", self.args.num_train_epochs)
logger.info(" Total train batch size = %d", self.args.train_batch_size)
logger.info(" Gradient Accumulation steps = %d", self.args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
logger.info(" Logging steps = %d", self.args.logging_steps)
logger.info(" Save steps = %d", self.args.save_steps)
global_step = 0
tr_loss = 0.0
self.model.zero_grad()
train_iterator = trange(int(self.args.num_train_epochs), desc="Epoch")
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration")
for step, batch in enumerate(epoch_iterator):
self.model.train()
batch = tuple(t.to(self.device) for t in batch) # GPU or CPU
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2],
"labels": batch[3],
"e1_mask": batch[4],
"e2_mask": batch[5],
}
outputs = self.model(**inputs)
loss = outputs[0]
if self.args.gradient_accumulation_steps > 1:
loss = loss / self.args.gradient_accumulation_steps
loss.backward()
tr_loss += loss.item()
if (step + 1) % self.args.gradient_accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
self.model.zero_grad()
global_step += 1
if self.args.logging_steps > 0 and global_step % self.args.logging_steps == 0:
self.evaluate("test") # There is no dev set for semeval task
if self.args.save_steps > 0 and global_step % self.args.save_steps == 0:
self.save_model()
if 0 < self.args.max_steps < global_step:
epoch_iterator.close()
break
if 0 < self.args.max_steps < global_step:
train_iterator.close()
break
return global_step, tr_loss / global_step
def evaluate(self, mode):
# We use test dataset because semeval doesn't have dev dataset
if mode == "test":
dataset = self.test_dataset
elif mode == "dev":
dataset = self.dev_dataset
else:
raise Exception("Only dev and test dataset available")
eval_sampler = SequentialSampler(dataset)
eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=self.args.eval_batch_size)
# Eval!
logger.info("***** Running evaluation on %s dataset *****", mode)
logger.info(" Num examples = %d", len(dataset))
logger.info(" Batch size = %d", self.args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
preds = None
out_label_ids = None
self.model.eval()
for batch in tqdm(eval_dataloader, desc="Evaluating"):
batch = tuple(t.to(self.device) for t in batch)
with torch.no_grad():
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2],
"labels": batch[3],
"e1_mask": batch[4],
"e2_mask": batch[5],
}
outputs = self.model(**inputs)
tmp_eval_loss, logits = outputs[:2]
eval_loss += tmp_eval_loss.mean().item()
nb_eval_steps += 1
if preds is None:
preds = logits.detach().cpu().numpy()
out_label_ids = inputs["labels"].detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
out_label_ids = np.append(out_label_ids, inputs["labels"].detach().cpu().numpy(), axis=0)
eval_loss = eval_loss / nb_eval_steps
results = {"loss": eval_loss}
preds = np.argmax(preds, axis=1)
write_prediction(self.args, os.path.join(self.args.eval_dir, "proposed_answers.txt"), preds)
result = compute_metrics(preds, out_label_ids)
results.update(result)
logger.info("***** Eval results *****")
for key in sorted(results.keys()):
logger.info(" {} = {:.4f}".format(key, results[key]))
return results
def save_model(self):
# Save model checkpoint (Overwrite)
if not os.path.exists(self.args.model_dir):
os.makedirs(self.args.model_dir)
model_to_save = self.model.module if hasattr(self.model, "module") else self.model
model_to_save.save_pretrained(self.args.model_dir)
# Save training arguments together with the trained model
torch.save(self.args, os.path.join(self.args.model_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", self.args.model_dir)
def load_model(self):
# Check whether model exists
if not os.path.exists(self.args.model_dir):
raise Exception("Model doesn't exists! Train first!")
self.args = torch.load(os.path.join(self.args.model_dir, "training_args.bin"))
self.model = RBERT.from_pretrained(self.args.model_dir, args=self.args)
self.model.to(self.device)
logger.info("***** Model Loaded *****")
说明
整个代码的流程就是:
- 定义训练数据;
- 定义模型;
- 定义优化器;
- 如果是训练,将模型切换到训练状态;model.train(),读取数据进行损失计算,反向传播更新参数;
- 如果是验证或者测试,将模型切换到验证状态:model.eval(),相关计算要用with torch.no_grad()进行包裹,并在里面进行损失的计算、相关评价指标的计算或者预测;
使用到的一些技巧
采样器的使用
在训练的时候,我们使用的是RandomSampler采样器,在验证或者测试的时候,我们使用的是SequentialSampler采样器,关于这些采样器的区别,可以去这里看一下:
https://chenllliang.github.io/2020/02/04/dataloader/
这里简要提一下这两种的区别,训练的时候是打乱数据再进行读取,验证的时候顺序读取数据。
使用梯度累加
核心代码:
if (step + 1) % self.args.gradient_accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
self.model.zero_grad()
global_step += 1
梯度累加的作用是当显存不足的时候可以变相的增加batchsize,具体就不作展开了。
不同参数设置权重衰减
核心代码:
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in self.model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.args.weight_decay,
},
{
"params": [p for n, p in self.model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = AdamW(
optimizer_grouped_parameters,
lr=self.args.learning_rate,
eps=self.args.adam_epsilon,
)
有的参数是不需要进行权重衰减的,我们可以分别设置。
warmup的使用
核心代码:
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=self.args.warmup_steps,
num_training_steps=t_total,
)
看一张图:
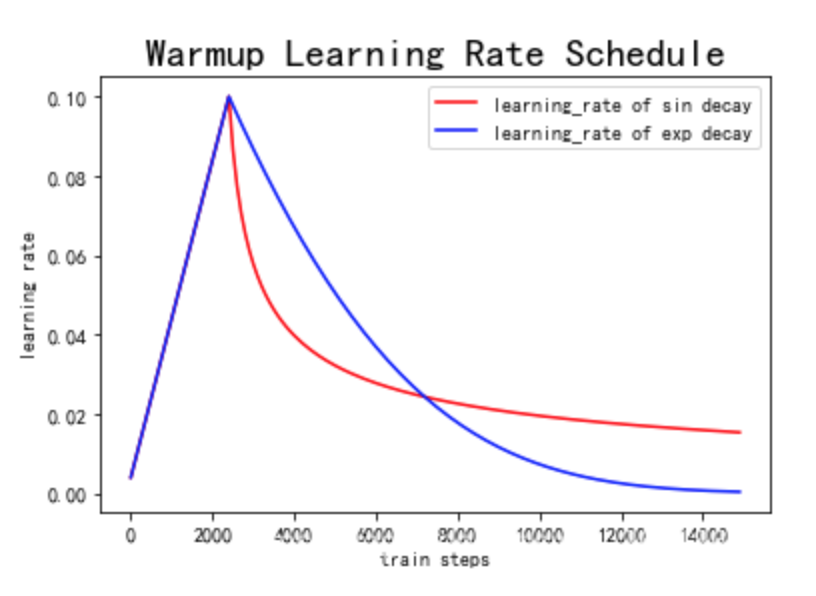
warmup就是在初始阶段逐渐增大学习率到指定的数值,这么做是为了避免在模型训练的初期的不稳定问题。