数据分析三剑客:
概念:是把隐藏在一些看似杂乱无章的数据背后的信息提炼出来,总结出所研究对象的内在规律
Numpy 支持大量的维度数组与矩阵运算,
Pandas 处理数据丢失,
Matplotlib 是回值曲线图的,
**requests模块 **
text字符串形式的响应数据
json
content 二进制流
proxy="{http:ip:port}
aiohttp模块
text()字符串形式的响应数据
json()
read()二进制类型的数据
requests模块
Response.text:返回的是字符串形式的响应数据
Response.json(): 返回json数据
Response.content:返回的是二进制流(图片,mp3)
urllib的用法
url = 'http://img2.imgtn.bdimg.com/it/u=1718395925,3485808025&fm=26&gp=0.jpg'
urllib.request.urlretrieve(url=url,filename='./123.png')
爬取sogo的页面
url = 'https://www.sogo.com/'
response = requests.get(url=url)
#.text返回的是字符串形式的响应数据
page_text=response.text
with open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
携带动态的 参数
url = 'https://www.sogou.com/web?query=jay'
#动态的 参数
wd = input('enter a word:')
param = {
'query':wd
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
#携带了动态的参数进行的请求发送
response = requests.get(url=url,params=param,headers=headers)
#手动修改响应数据 的编码
response.encoding='utf-8'
page_text = response.text
filename = wd+".html"
with open(filename,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(filename,'下载成功')
**爬取豆瓣电影中电影的详情数据 **
url = 'https://movie.douban.com/j/chart/top_list'
s = input('enter a start:')
l = input('enter a limit:')
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
param = {
"type": "24",
"interval_id": "100:90",
"action":"" ,
"start": s,
"limit":l,
}
response = requests.get(url=url,headers=header,params=param)
page_text = response.text
print(type(page_text))
爬取图片
url='http://img2.imgtn.bdimg.com/it/u=1718395925,3485808025&fm=26&gp=0.jpg'
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
img_data = requests.get(url=url,headers=header).content
with open('./fj.jpg','wb') as f:
f.write(img_data)
爬取糗事百科中的糗图数据
re.S:单行处理,可以处理换行
import re
import os
import requests
from urllib import request
if not os.path.exists('./qiutuLibs'):
os.mkdir('./qiutuLibs') #创建文件呀
#通用的url模板(不可变)
url = 'https://www.qiushibaike.com/pic/page/%d/?s=5205107'
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
}
for page in range(1,36):
new_url = format(url%page)
page_text = requests.get(url=new_url,headers = header).text
#数据解析,img的属性值(图片的连接)
ex = '<div class="thumb">.*?<img src="(.*?)" alt=.*?</div>'
img_src_list = re.findall(ex,page_text,re.S)
for src in img_src_list:
src = 'https:'+src
img_name = src.split('/')[-1]
img_path = './qiutuLibs/'+img_name
request.urlretrieve(src,img_path)
print(img_name+'下载成功')
第一个反爬机制
robots协议,
特性:防君子不防小人
https和http相关
- http协议:客户端和服务器 端进行数据交互的形式。
- 常用的请求头信息
- User-Agent:请求载体的身份标识
- Connection:close
- 响应头信息
- content-type
- 常用的请求头信息
- https:安全的http(加密)
- 对称秘钥加密:客户端 - 加密信息 - 服务器(把秘钥很密文同时发送,存在隐患)
- 非对称秘钥加密:服务端把公钥给客户端,客户端加密后把密文发回服务端(客户端不能保证公钥是哪个指定服务器发的)
- 证书秘钥加密(***):证书":公开秘钥,服务端会产生公开密钥,把秘钥交给证书认证机构,做数字签名,把证书交给客户端,客户端通过公钥给密文加密,然后把密文交给服务端
UA检测
网站会检测当前请求的请求载体的身份标识。
如何破解(uA伪装)
将user-agent对应得数据封装到字典中,将字典作用到请求方法的headers参数中
什么是动态加在数据?
通过ajax或js请求到的数据
如何获取动态加载数据?
在抓包工具中进行全局搜索, 定位到动态加载数据对应的数据包,从数据包提取url和参数
Get和post方法中常用的参数
url headers params/data
一、什么是爬虫?
通过编写程序让其模拟浏览器上网,然后去互联网中抓取数据的过程 ",
爬虫的分类
通用爬虫:就是抓取一整张页面源码内容
聚焦爬虫:抓取的是页面中局部的内容
增量式爬虫:可以监测网站数据更新的情况。抓取网站中最新更新出来的数据
反爬机制 :对应的载体数网站。
反反爬策略: 对应的载体爬虫程序.
探究一下爬虫的合法性:
爬虫本身是不被法律禁止(中立性)
爬取数据的违法风险的体现:
爬虫干扰了被访问网站的正常运营
爬虫抓取了受到法律保护的特定类型的数据或信息
如何规避违法的风险?
严格遵守网站设置的robots协议;
在规避反爬虫措施的同时,需要优化自己的代码,避免干扰被访问网站的正常运行;
在使用、传播抓取到的信息时,应审查所抓取的内容,如发现属于用户的个人信息、隐私或者他人的商业秘密的,应及时停止并删除。
二、数据解析方式
实现数据解析方式
正则,bs4,xpath,pyquery
为什么使用数据解析?
数据解析是实现聚焦爬虫的核心技术,就是在一张页面源码中提取除指定的文本内容
通用解析原理?
要解析提取的数据都是存储在标签中间或者是标签的属性中
1)标签定位
2)取文本或者取属性
通用解决乱码的处理方式
1) img_title = img_title.encode('iso-8859-1').decode('gbk')
2) response = requests.get(url=new_url,headers=header)
response.encoding = 'utf-8'
page_text = response.text
1.正则解析
re.S:单行处理,可以处理换行
2.bs4解析
解析原理:
1).实例化一个BeautifulSoup的一个对象,且将即将被解析的页面源码加载到该对象中
",
2).需要调用bs对象中相关属性和方法进行标签定位和数据的提取
",
环境安装
pip install lxml(解析器)
",
pip install bs4
",
BeautifulSoup对象的实例化
BeautifulSoup('fp','lxml'):将本地存储的一张html页面中的页面源码加载到bs对象中
BeautifulSoup(page_text,'lxml'):将互联网请求到的页面源码数据加载到bs对象"
bs相关属性和方法
tagName就是div a标签
attrName是class id 属性
soup.tagName #可以定位到第一次出现的tagName标签,返回值是一个单数
find('tagName') == soup.tagName"
属性定位
find('tagName',attrName='value'),返回的也是单数
find_all(): 和find的用法一样,只是返回值是一个列表(复数)
select('选择器'):id,class,标签,层级选择器,返回值为列表.
>表示一个层级 空格表示多个层级
取文本
string定位的是直系的文本内容
text,get_text()定位的是所有的文本内容
取属性
tag['attrName']"
**使用bs 解析本地存储的页面中相关的局部数据 **
from bs4 import BeautifulSoup
fp = open('./index.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
爬取诗词名句网数据
把数据存在本地
import requests
url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
}
page_text = requests.get(url=url,headers=header).text
#数据解析 :章节标题和对应得内容
soup = BeautifulSoup(page_text,'lxml')
a_list = soup.select('.book-mulu > ul > li > a')
fp = open('./sanguo.txt','w',encoding='utf-8')
for a in a_list:
title = a.string
detail_url = 'http://www.shicimingju.com'+a['href']
# print(detail_url)
detail_page_text = requests.get(url=detail_url,headers=header).text
# print(detail_page_text)
#解析详情页的页面源码
soup = BeautifulSoup(detail_page_text,'lxml')
content = soup.find('div',class_="chapter_content").text
# content = soup.select('.chapter_content')
# print(content)
fp.write(title+':'+content+'
')
print(title,'下载成功')
fp.close()
Soup.a: 拿到a标签
soup.find(‘div’,class_=’tang)
soup.select(‘.tang > a’)[1].string: 拿到的是a标签的内容 1是下标索引
Soup.select(‘.tang > img’)[0][‘src’] :s索引为0的img标签,取属性src
.select(‘.tang > ul >li > a’)== .select(‘.tang a’)
3.xpath解析
- 优点:通用性强
- 解析原理:
- 1.实例化一个etree的对象,将即将被解析的页面源码加载到该对象中 ",
- 2.调用etree对象中的xpath方法结合着不同的xpath表达式实现标签定位和数据提取
- 环境安装:
- pip install lxml
- etree对象实例化:
- etree.parse('filePath') #解析的是本地
- etree.HTML(page_text) #解析的是浏览器的
xpath 相关的属性和方法
xpath方法返回值是列表
最左侧如果为一个斜杠,则表示必须从跟节点开始进行标签定位
最左侧为两个斜杠,表示可以从任意位置标签定位
非最左侧的一个斜杠表示一个层级,两个斜杠表示多个层级
属性定位
//tagName[@attrName='value']
索引定位
//div[@class="tang"]/ul/li[2] 索引是从1开始
取文本
/text() //text()
取属性
/@attrName
爬取boss(岗位名称,公司名称,薪资,岗位描述)
from lxml import etree
import requests
tree = etree.parse
url = 'https://www.zhipin.com/job_detail/?query=python%E7%88%AC%E8%99%AB&city=101010100&industry=&position='
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
}
page_text = requests.get(url=url,headers=header).text
#解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="job-list"]/ul/li')
for li in li_list:
jog_name = li.xpath('./div/div[@class="info-primary"]/h3/a/div[1]/text()')[0]
salary = li.xpath('./div/div[@class="info-primary"]/h3/a/span/text()')[0]
company = li.xpath('.//div[@class="company-text"]/h3/a/text()')[0]
detail_url = 'https://www.zhipin.com'+li.xpath('./div/div[@class="info-primary"]/h3/a/@href')[0]
detail_page_text = requests.get(detail_url,headers=header).text
#解析详情页中的岗位描述
tree = etree.HTML(detail_page_text)
job_desc = tree.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div//text()')
job_desc = ''.join(job_desc)
print(jog_name,salary,company,job_desc)
好处:使用 | 管道符,使得xpath表达式更具有通用性(放到一个列表里)
"tree.xpath('//div[@class="bottom"]/ul/li/a/text() | //div[@class="bottom"]/ul/div[2]/li/a/text()')"
**图片懒加载概念:伪属性 **
图片懒加载是一种网页优化技术。图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间。为了解决这种问题,通过前后端配合,使图片仅在浏览器当前视窗内出现时才加载该图片(真属性),达到减少首屏图片请求数的技术就被称为“图片懒加载
网站一般如何实现图片懒加载技术呢?
在网页源码中,在img标签中首先会使用一个“伪属性”(通常使用src2,original......)去存放真正的图片链接而并非是直接存放在src属性中。当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载
HTTPConnectionPool(host:XX)Max retries exceeded with url
错误产生的原因
- 爬虫在短时间内发起了高频的网络请求,请求对应的ip就会被服务器端禁
- 连接池资源被耗尽
处理方式:
- 在headers里加connection:“close”, 或是改IP
代理
- 代理:代理服务器
- 基于代理的网站
- 站大爷
- goubanjia
- 快代理
- 西祠代理
- 代理的匿名度
- 透明:使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP ",
- 匿名:对方服务器可以知道你使用了代理,但不知道你的真实IP。 ",
- 高匿:对方服务器不知道你使用了代理,更不知道你的真实IP ",
- 类型
- http:代理服务器只可以转发http协议的请求 ",
- https:代理服务器只可以转发https协议的请求 ",
- 编码:
- 在get或者post方法中应用一个proxies的参数,给其参数赋值为{'http':'ip:port'}
例
url = 'https://www.baidu.com/s?wd=ip'
page_text = requests.get(url,headers=header,proxies={'http':'113.108.242.36:47713'}).text
with open('./ip.html','w',encoding='utf-8') as f:
f.write(page_text)
动态请求参数:
出现在post请求参数中
通常情况下动态参数往往都被隐藏在了前台页面中
cookie处理
- 处理方式
- 手动处理:将cookie的键值对手动添加到headers字典中,然后将headers作用到get或者post方法的headers参数中
- 自动处理:使用Session。
",
- session作用:session可以和requests一样进行请求的发送 ",
- 特性:使用session发起请求,如果请求过程中产生cookie,则cookie会被自动存储到session中"
例 爬取雪球网
url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id=-1&count=10&category=-1'
# requests.get(url,headers=header).text
#创建一个session对象
session = requests.Session()
#获取cookie
session.get('https://xueqiu.com/',headers=header)
#携带cookie进行的请求发送
session.get(url,headers=header).json()
模拟登陆
-
什么是模拟登陆
- 使用requests对登陆按钮的请求进行发送
(能够爬取到登录成功之后的相关页面数据)
- 使用requests对登陆按钮的请求进行发送
-
为什么要模拟登陆
- 有的页面必须登陆之后才显示
验证码的识别
- 有的页面必须登陆之后才显示
-
线上的打码平台:超级鹰,云打码,打码兔......
-
超级鹰的使用流程
- 注册:用户中心身份的账户
- 登陆:
- 查看提分的剩余
- 创建一个软件ID:软件ID-》生成一个软件ID(ID的名称和说明)
- 下载示例代码:开发文档-》选择语言-》点击下载
例:使用超级鹰识别验证码图片
先导入它里边的 类方法(要是用pycharm,就把他封装到一个py文件里)执行


例:模拟登陆


爬虫中的异步操作
- 线程池(适当)
- 单线程+多任务异步协程(推荐)
- 协程:coroutine
- 任务对象:stask
- 事件循环对象:event_loop
多任务异步协程(并发):提升爬去效率
-
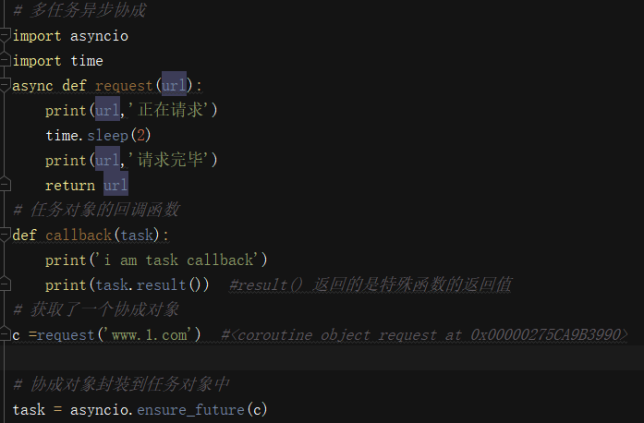
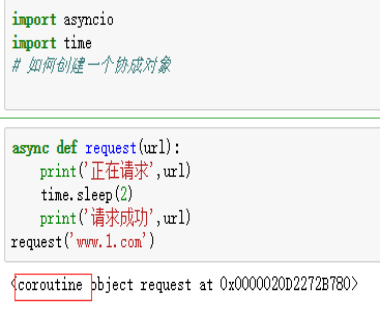
协程:对象 coroutine。如果一个函数在定义的时候被async修饰了,则该函数被调用的时候会返回一个协程对象 ,函数内部的程序语句不会其调用的时候被执行(特殊的函数)
-
任务对象:对象,就是对协程的进一步封装。任务对象协程特殊的函数.任务对象中可以显示
协程的相关状态。任务对象可以被绑定一个回调。
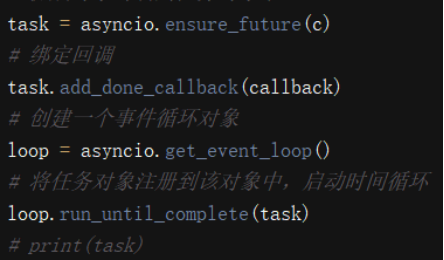
- 绑定回调: -
事件循环:无限(不确定循环次数)的循环。需要向其内部注册多个任务对象(特殊的函数)。
-
async:专门用来修饰函数
-
await:挂起
单线程+多任务异步协成
asyncio模块:协成
aiohttp模块:异步协成

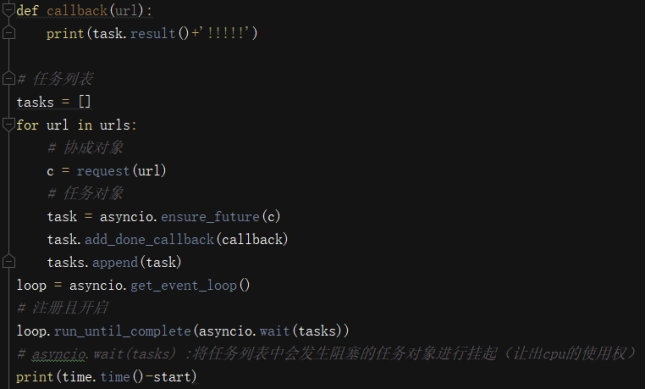
基于异步的操作

协成操作
Aiohttp模块实现多任务异步爬虫
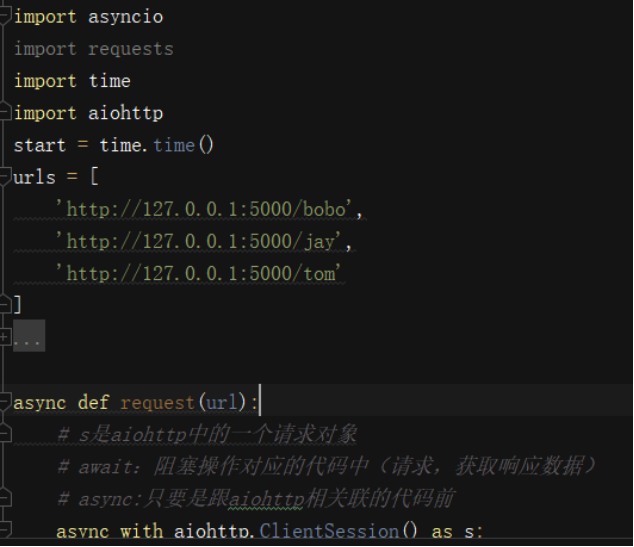
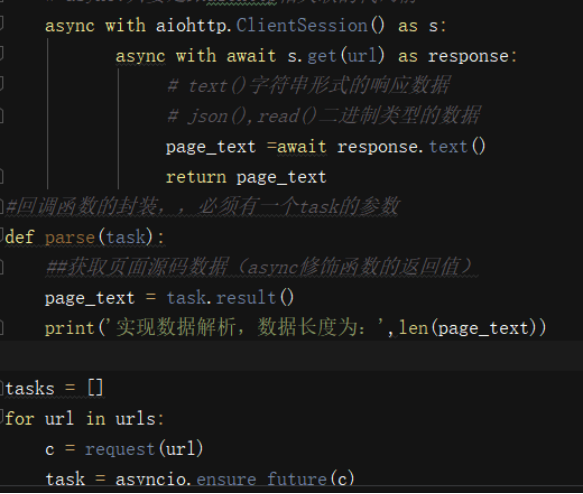

selenium模块
Pyppeteer(支持异步) ==selenium(不支持)
Pyppeteer通用性和适用性不强
概念
模块。基于浏览器自动化的模块。
- 爬虫之间的关联
- 实现模拟登陆
- 非常便捷的获取动态加载的页面数据
- 环境的安装:pip install selenium
- selenium的基本使用
- 实例化一个浏览器对象(必须将浏览器的驱动程序进行加载)
- 驱动程序下载:http://chromedriver.storage.googleapis.com/index.html
- 映射关系表:http://blog.csdn.net/huilan_same/article/details/51896672 ",
- 通过代码指定相关的行为动作
Js window.scrollTo(0,document.body.scrollHeight):滚条跳到尾
例

Selenium 如何规避网站监测
正常情况下我们用浏览器访问淘宝等网站的 window.navigator.webdriver的值为
undefined。而使用selenium访问则该值为true
Selenium 访问值为true,就是被检测了,
只需要设置Chromedriver的启动参数即可,参数'excludeSwitches',他的值为['enable-automation']

iframe
分析发现定位的a标签出现在iframe标签之下,则必须通过switch_to.frame操作后,才可以进行标签定位
phantomJs:是一个无可视化界面的浏览器
例:谷歌浏览器
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 实例化了一个谷歌浏览器对象且将驱动程序进行了加载
",
bro = webdriver.Chrome(executable_path='./chromedriver.exe',chrome_options=chrome_options)
bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
bro.save_screenshot('./1.png') #截图,看看无可视化界面跑哪了
print(bro.page_source)
scrapy框架
抓包工具
fiddler mitmproxy, 青花瓷(发送请求来提取数据的,相当于代理)
移动端数据爬取
- 抓包工具:
- fiddler,mitmproxy,青花瓷
- fiddlers相关配置
- 在手机中安装抓包工具的证书
- 将手机网络和fidders所在的机器配置到同一网段中
- 在手机中访问fidder服务器的一张子页面进行证书下载(信任和安装)
- (手机)网络代理配置:
- 将手机进行代理设置
- 代理ip:fidders所在机器的ip
- 端口:fidder自己的端口
概念
就是一个具有很强通用性且已经集成了很多功能的项目模板
scrapy功能(不带任何可视化界面),效率优于pyspider
- 高性能的数据解析
- 高性能的持久化存储
- 中间件
- 分布式
- 异步的数据下载(基于twisted实现)
pyspider框架:有可视化界面
环境安装
linux
pip install scrapy
windows
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install
Twisted
17.1.0
cp35
cp35m
win_amd64.whl
d. pip3 install pywin32
e. pip3 install scrapy
spider使用
- 创建一个工程:scrapy startproject ProName
- cd ProName
- 在爬虫文件夹(spiders)中创建一个爬虫文件:scrapy genspider spiderName www.x.com
- 配置文件:
- 进行UA伪装
- 不遵从robots
- 日志等级的指定 LOG_LEVEL = 'ERROR'
- 执行工程:scrapy crawl spiderName
持久化存储
-
基于终端指令
- 使用:可以将parse方法的返回值存储到本地磁盘文件中
- 指令:scrapy crawl spiderName -o filePath
- 好处:便捷
- 弊端:局限性强,只可以将数据存储到指定后缀的文本文件,只可以将数据存储到文件,不能存到数据库中(后缀:'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')
-
基于管道
- 编码流程:
- 数据解析
- 在item类中进行相关属性定义
- 将解析的数据封装到item类型的对象中
- 将item对象提交给管道
- 管道接收item然后调用process_item方法进行数据的持久化存储
- 将管道开启
- 编码流程:
使用
(1)配置setting

author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
content = div.xpath('./a/div/span//text()').extract()
content = ''.join(content)
div.xpath(‘’) [0] #取得是<Selector >对象
extract_first() #取得是单数
extract()#取得是复数放在列表里,通过
content = ''.join(content)拼接得到内容
(2)存储到本地
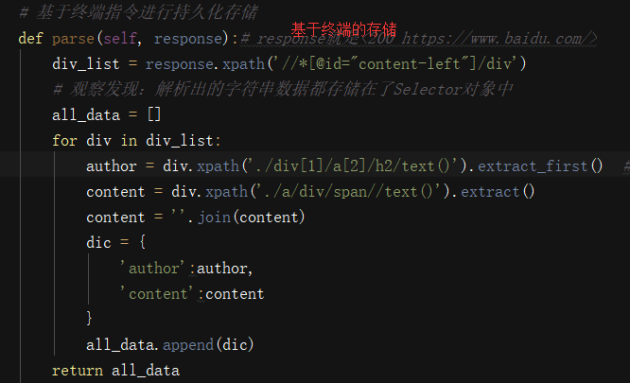

基于管道
- 数据解析
- 在item类中进行相关属性定义

-
将解析的数据封装到item类型的对象中
from firstBlood.items import FirstbloodItem
def parse(self, response): # response就是<200 https://www.baidu.com/>
div_list = response.xpath('//*[@id="content-left"]/div')
# 观察发现:解析出的字符串数据都存储在了Selector对象中
for div in div_list:
author = div.xpath(
'./div[1]/a[2]/h2/text()').extract_first() # [0]取得是
content = div.xpath('./a/div/span//text()').extract()
content = ''.join(content)
#实例化item对象
item = FirstbloodItem()
# 将解析的数据封装到item中
item['author'] = author #将解析到的author存储到item对象的author属性中
item['content'] = content
# 将item提交给管道
yield item -
管道接收item然后调用process_item方法进行数据的持久存本地
对应的是一种数据存储的方式
class FirstbloodPipeline(object):
# 保证文件只打开一次
f = None
def open_spider(self,spider):
print('开始爬虫')
self.f = open('qiubai.txt','w',encoding='utf-8')# item就是用来接收爬虫文件提交过来的item对象 # process_item每接收一个item就会被调用一次 def process_item(self, item, spider): print(item) self.f.write(item['author']+':'+item['content']+' ') return item def close_spider(self,spider): print('结束爬虫') self.f.close() -
将管道开启
300优先级,数值越小优先级越高

-
执行

2)存MySQL中 在pip2lines.py中写
# 存在MySQL数据库
class mysqlPileLine(object):
conn = None
cursor = None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='',db='spider',charset='utf8')
self.cursor = self.conn.cursor()
print(self.conn)
def process_item(self,item,spider):
sql = 'insert into qiubai values ("%s","%s")'%(item['author'],item['content'])
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
改配置
ITEM_PIPELINES = {
# 'firstBlood.pipelines.mysqlPileLine': 301,
- 在终端建库,建表,查看

3)存redis数据库中
将redis的版本切换到2.10.6 pip install -U redis==2.10.6
class redisPileLiine(object):
conn = None
def open_spider(self,spider):
self.conn = Redis(host='127.0.0.1',port=6379)
def process_item(self,item,spider):
# 将redis的版本切换到2.10.6 pip install -U redis==2.10.6
dic = {
'author':item['author'],
'content':item['content']
}
self.conn.lpush('qiubai',dic)
改配置
ITEM_PIPELINES = {
'firstBlood.pipelines.redisPileLiine': 302,
启动redis
keys *
llen qiubai :查看长度
ImagesPileline类
在piplines.py
#定制指定父类的管道类
class ImgPileline(ImagesPipeline):
#根据图片地址进行图片数据的请求
def get_media_requests(self,item,info):
#不需要指定回调函数
yield scrapy.Request(url=item['img_src'])
# 指定图片存储的名称
def file_path(self,request,response=None,info=None):
url = request.url #图片地址
name = url.split('/')[-1]
return name
#将item传递给下一个即将被执行的管道类
def item_completed(self,results,item,info):
return item
在setting里
ITEM_PIPELINES = {
'imgPro.pipelines.ImgPileline': 300,
}
三、Scrapy五大核心组件
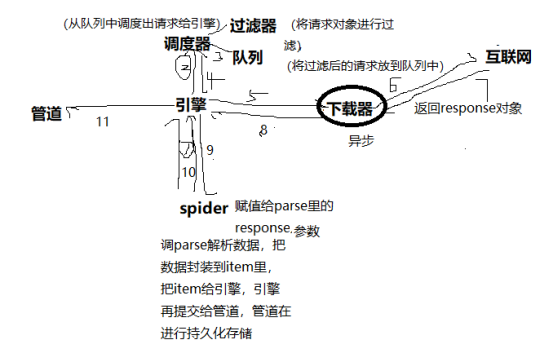
每一个组件的作用
- 组件之间的工作流程
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 引擎(Scrapy)
使用场景:
爬取的数据不在同一张页面中
Request(url,callback,meta={xx:xx}):meta就可以传递个callback
callback接受meta:response.meta
例:
url = 'https://www.4567tv.tv/index.php/vod/show/class/%E5%8A%A8%E4%BD%9C/id/1/page/2.html'
page_num = 2
def detail_parse(self,response):
desc = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item = response.meta['item']
item['desc'] = desc
yield item
def parse(self, response):
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
name = li.xpath('./div/a/@title').extract_first()
detail_url = 'https://www.4567tv.tv'+li.xpath('./div/a/@href').extract_first()
item = MovieproItem()
item['name'] = name
# meta是一个字典,可以将meta传递给callback
yield scrapy.Request(detail_url,callback=self.detail_parse,meta={'item':item})
Scrapy的相关配置:
增加并发:
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。
降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘INFO’
禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False
禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False
减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 10 超时时间为10s
整理:
数据解析:response.xpath()
-
scrapy的xpath和etree的xpath的区别:
- xpath返回的列表元素的类型不一样
- extract() extract_first()
-
细节处理:
- 什么时候需要编写多个管道类
- 场景:爬取到的数据一份存入本地文件,一份存储mysql,redis
-
管道文件中管道类表示什么含义?
- 一个管道类对应一种持久化存储的方式
- process_item中返回值的作用:
- return item:将item传递给下一个即将被执行的管道类
- 基于Spider父类的全站数据爬取
- 手动请求发送
- yield scrapy.Request(url,callback):callback指定解析方法 (get)
- 手动请求发送
yield scrapy.Request(url=new_url,callback=self.parse) #get请求
- yield scrapy.FormRequest(url,callback,formdata)#post请求 - 对起始url列表发起post请求: def start_requests(self): for url in self.start_urls: yield scrapy.FormRequest(url,formdata={},callback=self.parse) - 注意:scrapy如果发起post请求,scrapy会自动处理cookie
反爬虫机制
3.1 使用代理
适用情况:限制IP地址情况,也可解决由于“频繁点击”而需要输入验证码登陆的情况。
这种情况最好的办法就是维护一个代理IP池,网上有很多免费的代理IP,良莠不齐,可以通过筛选找到能用的。对于“频繁点击”的情况,我们还可以通过限制爬虫访问网站的频率来避免被网站禁掉。
proxies = {'http':'http://XX.XX.XX.XX:XXXX'}
Requests:
import requests
response = requests.get(url=url, proxies=proxies)
Urllib2:
import urllib2
proxy_support = urllib2.ProxyHandler(proxies)
opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
urllib2.install_opener(opener) # 安装opener,此后调用urlopen()时都会使用安装过的opener对象
response = urllib2.urlopen(url)
3.2 时间设置
适用情况:限制频率情况。
Requests,Urllib2都可以使用time库的sleep()函数
import time
time.sleep(1)
3.3 伪装成浏览器,或者反“反盗链”
有些网站会检查你是不是真的浏览器访问,还是机器自动访问的。这种情况,加上User-Agent,表明你是浏览器访问即可。有时还会检查是否带Referer信息还会检查你的Referer是否合法,一般再加上Referer。
headers = {'User-Agent':'XXXXX'} # 伪装成浏览器访问,适用于拒绝爬虫的网站
headers = {'Referer':'XXXXX'}
headers = {'User-Agent':'XXXXX', 'Referer':'XXXXX'}
Requests:
response = requests.get(url=url, headers=headers)
Urllib2:
import urllib, urllib2
req = urllib2.Request(url=url, headers=headers)
response = urllib2.urlopen(req)