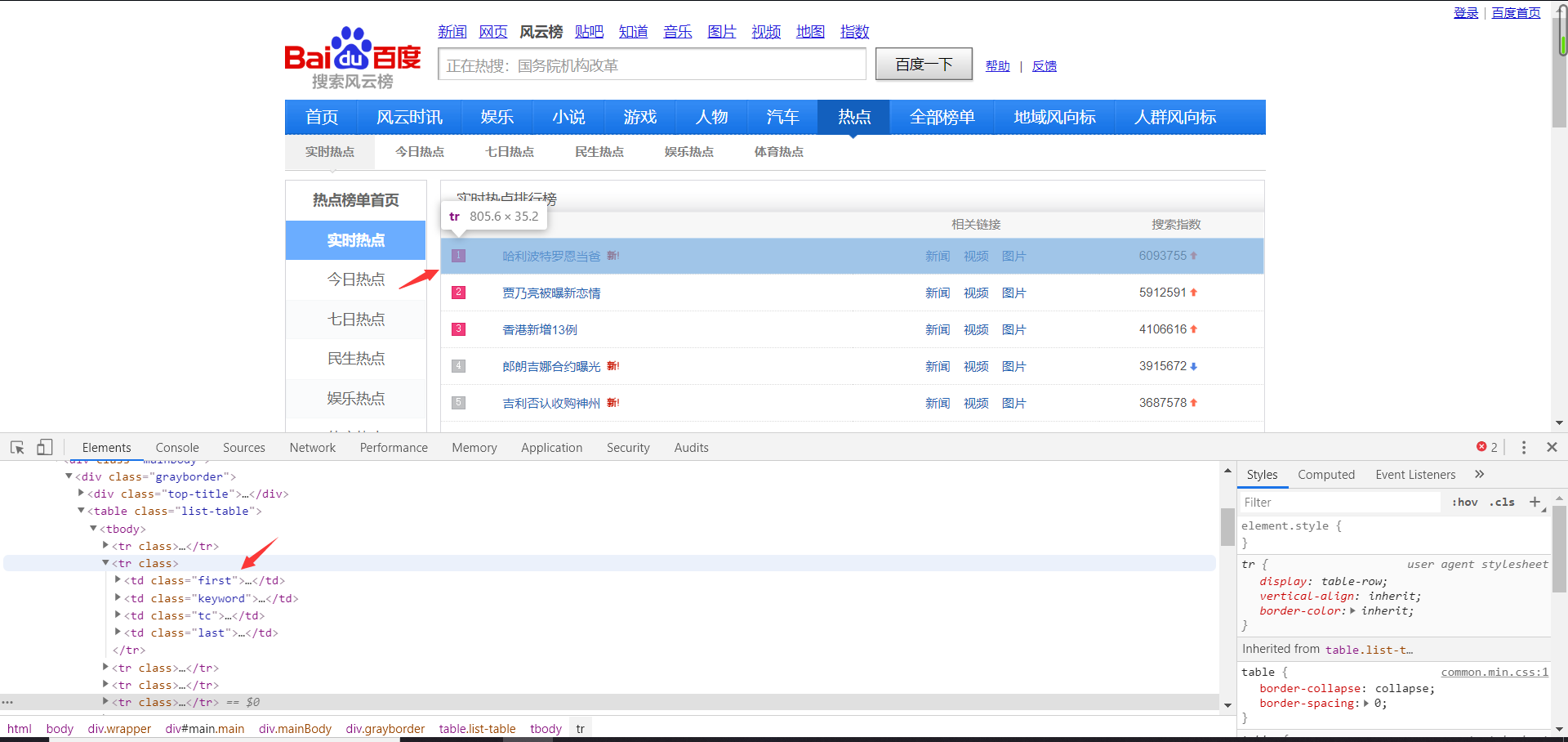
一、分析爬取的网址
f12不难找到排行版对应的区域,发现每个标题的各个元素是一个个td被包装在
一个tr标签里面,每一个标题都是一个tr。我们要获取的关键信息有排名,关键词,
搜索指数。
排名 :第一个td class=''first'
关键词:第二个td class = 'keyword'
搜索指数:最后一个td class = 'last'
二、思路:
分析网址,上面已经做完,找到数据所在地,切片,获取值,然后格式化的输出就可以
代码如下:


import requests from bs4 import BeautifulSoup import bs4 def get_html(url,headers): r = requests.get(url,headers = headers) r.encoding = r.apparent_encoding return r.text def get_pages(html): soup = BeautifulSoup(html,'html.parser') all_=soup.find_all('tr')[1:] #切片,寻找数据 for each_topic in all_: rank = each_topic.find('td', class_='first') # 排名 name = each_topic.find('td', class_='keyword') # 标题 times = each_topic.find('td', class_='last') #搜索指数 if rank != None and name!=None and times!= None: rank = each_topic.find('td',class_='first').get_text().replace(' ','').replace(' ','') name = each_topic.find('td',class_='keyword').get_text().replace(' ','').replace(' ','') times = each_topic.find('td',class_='last').get_text().replace(' ','').replace(' ','') tplt = "排名:{0:^4} 标题:{1:{3}^15} 热度:{2:^8}" print(tplt.format(rank,name,times,chr(12288))) def main(): url = 'http://top.baidu.com/buzz?b=1&fr=20811' headers= {'User-Agent':'Mozilla/5.0'} html = get_html(url,headers) get_pages(html) if __name__=='__main__': main()