本篇文章主要是以一条SQL查询语句和一条SQL更新语句是如何执行的带出来整体的MySQL架构
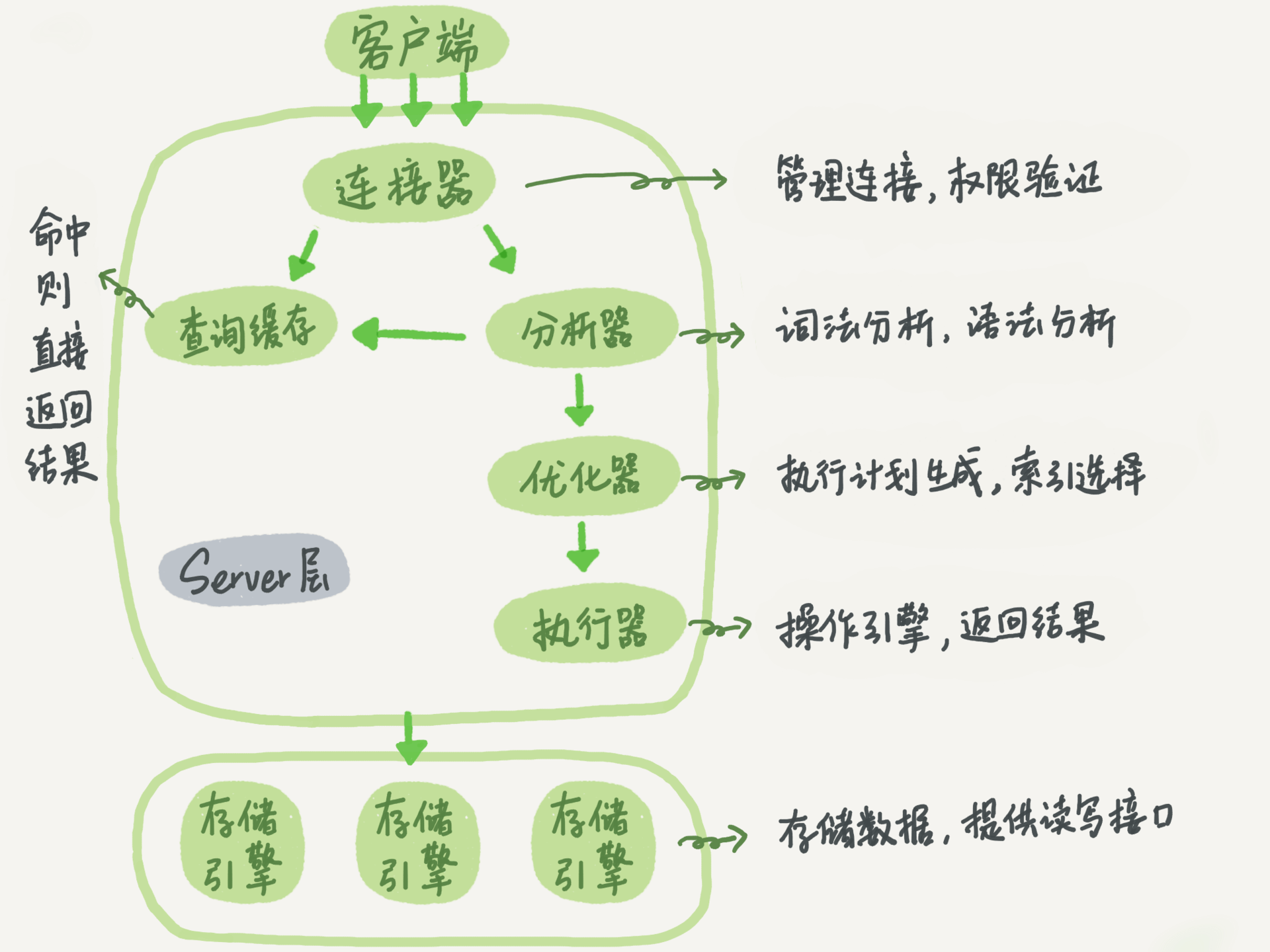
下方的图片是整体一个情况的概括,像查询缓存在MySQL8.0后已经弃用了,因为确实用处不大,而且像undo、redo和binlog在查询语句中是不会写入的。

查询语句
建立连接
mysql> select * from T where ID=10;
以如上的一条SQL语句为例,MySQL是采用可拔插是存储引擎,常见的存储引擎有MyISAM、InnoDB、Memory等。
咱们之前写Java代码的时候,一般会引入一个MySQL的jdbc jar包,例如mysql-connector-java-xxx.jar,这个jar包的作用就是与MySQL的服务建立连接。
说完连接后,就可以引出连接池的概念。从字面的意思就可以看出,这样是一个池子,因为频繁创建销毁线程对性能的影响很大,用一个池子来保持多个数据库连接,如果需要的话直接从池子里拿即可。常见的连接池有C3P0、Druid等。
查询缓存
查询缓存在8.0后就已经弃用了,原因是因为缓存的失效非常频繁,当对一个表更新后,那么所有的缓存都会失效。
解析器
解析器就是对整条SQL语句对词句分析,例如语法是否正确,当有错误的语法后就会收到下方的提示
mysql> elect * from t where ID=1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from t where ID=1' at line 1
优化器
一条SQL语句可能有多个执行方案,优化器的作用就是选择一个最优的方案
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
例如上方的语句,可能存在两种方案,可能是先查询t1的数据或者是t2的数据,具体就是优化器所需要进行的选择
执行器
执行器会根据我们的优化器生成的一套执行计划,然后不停的调用存储引擎的各种接口去完成SQL语句的执行计划。执行完毕后将结果返回,那么整条查询语句的过程也就结束。
更新语句
mysql> update T set c=c+1 where ID=2;
更新语句与上方的查询语句略有不同,首先需要引入一个Buffer Pool的概念
缓冲池
InnoDb存储引擎的内存结构是以页为单位的,它会从磁盘上加载部分数据到缓冲池中,这样当一条更新语句来的时候,它会先查看缓冲池中是否有数据,没有的话再从硬盘上加载。这个bufferpool后边会单独认真写一篇

undo log
undo日志的作用就是在更新前将数据的旧值写入undo日志中,这样如果提交事务前需要对数据回滚的话,随时可以回滚数据。

redo log buffer和redo log
redo log buffer是内存的一个缓冲区,用来存放redo log的。redo log记录了对数据库具体做了什么操作。但是此时redo log还是在内存中,如果断电的话就会丢失。那么何时将redo log 刷新到磁盘上?
redo log可以理解为重做日志,是InnoDB所特有的,首先就要引入一个Write-Ahead Logging概念,即先写日志,再写磁盘。redo log默认会在事务提交的时候将redolog更新到磁盘上。
这个策略是通过innodb_flush_log_at_trx_commit来配置,这个特性也成为crash-safe。

binlog
binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。之前说redo log的时候提到提交事务的时候,会将redo日志刷新到磁盘上,其实这同时也会将binlog刷新到磁盘上。
而binlog叫做归档日志,他里面记录的是偏向于逻辑性的日志,类似于“对users表中的id=10的一行数据做了更新操作,更新以后的值是什么”。
基于binlog和redolog完成事务的提交
上文提到,提交事务的时候,会同时将redo log和binlog刷入磁盘,那么为什么这么设计呢?
因为提交binlog的时候,还会将binlog带有一个commit标记同时写入redolog中,这样的作用就是作为一个标识保证redolog和binlog的位置是一样的。

当整个流程执行完后,此时磁盘上的数据还是旧值,但是缓冲池的数据却是最新的,MySQL有一个后台的IO线程,会在之后某个时间里,随机的把内存buffer pool中的修改后的脏数据给刷回到磁盘上的数据文件里去。