树
非线性数据结构定义:也就是每个元素可以有多个前驱和后继。树是一种非线性结构。它可以有两种定义。
第一种:树是n(n>=0,n为0时,称为空树)个元素的集合,它只有一个特殊的没有前驱的元素,这个元素成为树的根(root),而且树中除了根节点外,其余的元素都只能有一个前驱,可以有0个或者多个后继。
第二种递归定义:树T是n(n>=0,n为0时,称为空树)个元素的集合,它有且只有一个特殊元素根,剩余元素都可以被划分为M个互不相交的集合T1,T2,T3……、Tm,而每一个集合都是树,称为T的子树subtree,同时,子树也有自己的根。
维基百科是这样定义的:

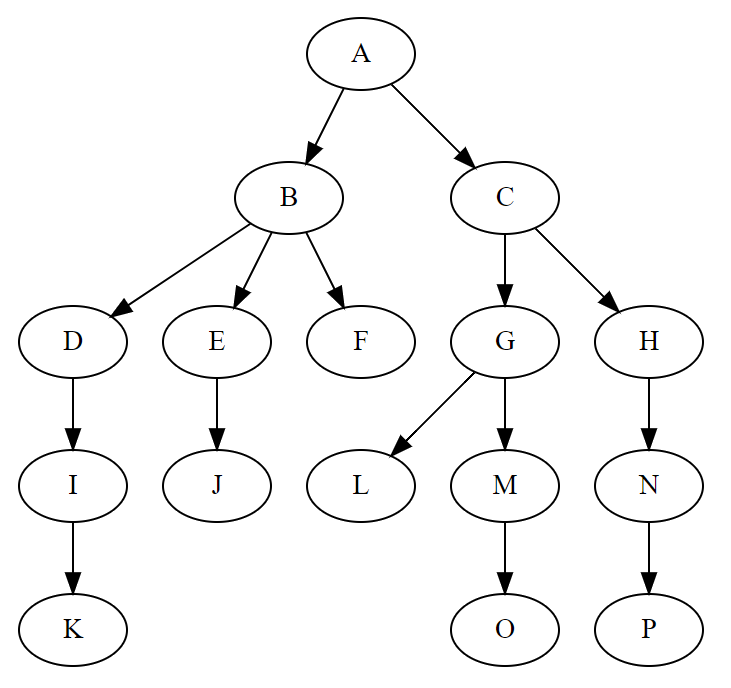
树中的概念
结点:树中的数据元素,也就是上图中的,A,B,C,D,E,F,G……
结点的度degree:节点拥有的子树的数目称为度,记作d(v)。
叶子结结:节点的度为0,称为叶子节点leaf,终端节点,末端节点。
分支结点:节点的度不为0,称为非终端节点或分支节点。
分支:节点之间的关系。
内部节点:除根节点外的分支节点,当然也不包括叶子节点。
树的度:树内各节点的度的最大值,比如下面这个图D节点的度最大为3,所以树的度数就是3.
孩子(儿子child)节点:节点的子树的根节点成为该节点的孩子。
双亲(父parent)节点:一个节点是他各子树的根节点的双亲。
兄弟(sibling)节点:具有相同双亲节点的节点。
祖先节点:从根节点到该节点所经分支上所有的节点,上图中A,B,D就都是G的祖先节点。
子孙节点:节点的所有子树上的节点都成为该节点的子孙,比如上图中,B节点的子孙有D,G,H,I。
节点的层次(level):根节点为第一层,根的孩子为第二层,以此类推,记作l(v).
树的深度(高度depth):树的层次的最大值,上图中的树深度为4.
堂兄弟:双亲在同一层的节点,堂兄弟的双亲不一定是兄弟。
有序树:节点的子树是有顺序的(兄弟有大小,有先后次序,不能交换),
无序树:节点的子树是无序的,可以交换。
路径:树中的k个节点,n1,n2……nk,满足ni是n(i+1)的双亲,成为n1到nK的一条路径,也就是一条线串下来的,前一个都是后一个的父(前驱)节点。
路径长度=路径上的节点数-1
森林:m(m>=0)棵不想交的树的集合。对于节点而言,其子树的集合就是森林,上图中A节点的2颗子树的集合就是森林。
数的特点:
- 数有唯一的根
- 子树不相交
- 除了根节点外,每个元素只能有一个前驱,可以有0个或多个后继。
- 根节点没有双亲节点(前驱),叶子节点没有孩子节点(后继)
- vi是vj的双亲,则L(vi)=L(vj)-1,也就是说双亲比孩子节点的层次小1。
二叉树
在计算机科学中,二叉树(英语:Binary tree)是每个节点最多只有两个分支(即不存在分支度大于2的节点)的树结构。通常分支被称作“左子树”或“右子树”。二叉树的分支具有左右次序,不能随意颠倒。

所以二叉树的每个节点最多有2棵子树,它不存在度数大于2的节点。
同时它是有序树,左子树,右子树是有顺序的,不能交换次序。而且即便是某个节点只有一颗子树,也要区分它是左子树还是右子树。
二叉树的5种基本形态:
- 空二叉树
- 只有一个根节点
- 根节点只有左子树
- 根节点只有右子树
- 根节点有左子树和右子树
斜树:
斜树分为左斜树和右斜树,左斜树是所有节点都只有左子树。而右斜树是所有节点都只有右子树。下图是一棵左斜树。
满二叉树
如果一棵二叉树的所有分支节点都存在左子树和右子树,并且所有叶子节点只存在在最下面一层。那么这就是满二叉树。如下图:

应该注意:
- 同样深度的二叉树中,满二叉树的节点是最多的。
- k为深度(1<=k<=n),则节点总数为(2^k)-1
- 上图为一个深度为4的15个节点的满二叉树。
完全二叉树Complete Binary Tree
如果二叉树的深度为K,二叉树的层数从1到K-1层的节点数都达到了最大个数 ,在第K层的所有节点都集中在最左边,这就是完全二叉树。完全二叉树是由满二叉树引申出来的,满二叉树一定是完全二叉树,而完全二叉树不一定是满二叉树。k为深度(1<=k<=n),则节点总数最大值为(2^k)-1,当达到最大值的时候就是满二叉树。下面三张图都是完全二叉树。
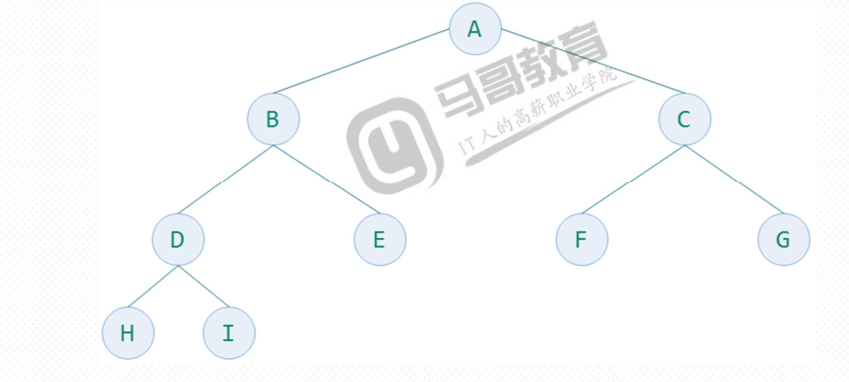
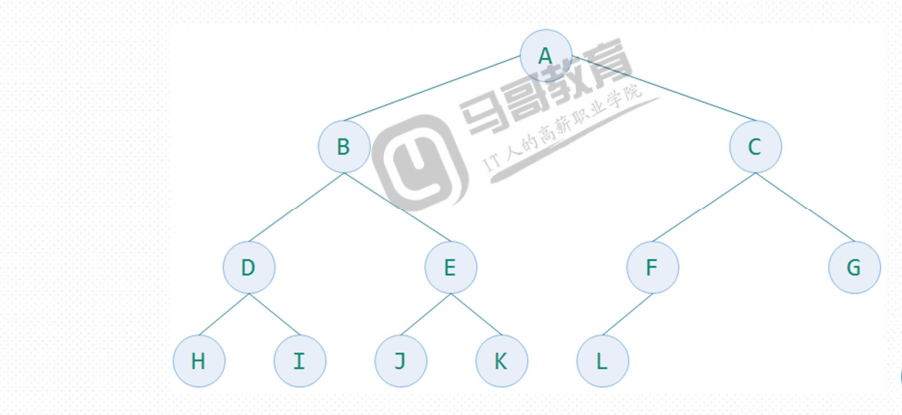
而下面的图则不是完全二叉树.
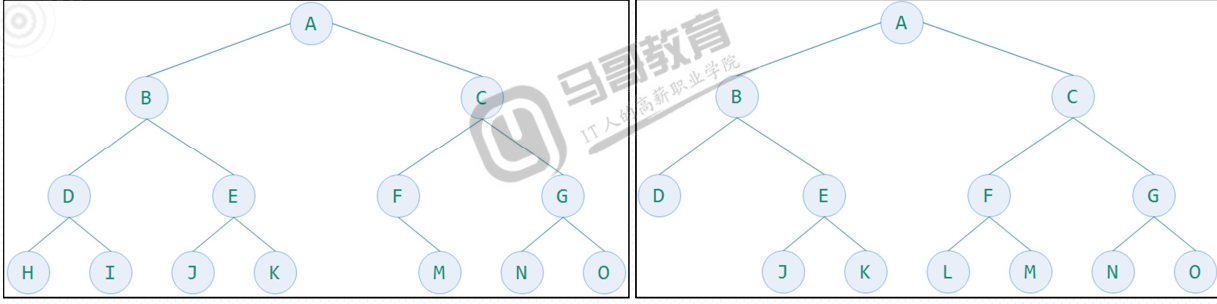
二叉树的性质
性质1:在二叉树的第i层上至多有2^(i-1)个节点(i>=1)。
性质2:深度为K的二叉树,至多有2^k-1个节点(k>=1),一层为2-1=1,二层4-1=3,三层8-1=7。
性质3:对任何一颗二叉树T,如果其终端节点数为no,度数为2的节点为n2,则有no = n2+1,也就是说,叶子节点数-1就等于度数为2的节点数。




二叉树的遍历
遍历也就是迭代所有元素一遍,而树的遍历也就是对树中所有元素不重复的访问一遍,也称作扫描。
树的遍历分为广度优先遍历(宽度优先)和深度优先遍历,广度优先遍历也就是层序遍历,而深度优先遍历分为前序遍历、中序遍历、后序遍历。
遍历序列:将树中所有元素遍历一遍后,得到的元素的序列。也就是将层次结构转换成了线性结构。
层序遍历
层序遍历也就是按照数的层次,从第一层开始,自左向右遍历元素。比如下面这颗树。
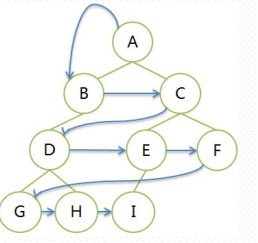
上面二叉树的遍历序列为ABCDEFGHI
深度优先遍历
设树的根节点为D,左子树为L,右子树为R,且要求L一定要在R之前,则有下面几种遍历方式:
- 前序遍历,也叫先序遍历、也叫先根遍历。DLR。
- 中序遍历,也叫中根遍历,LDR
- 后序遍历,也叫后跟遍历,LRD
前序遍历
前序遍历DLR,先从根节点开始,先左子树后右子树。然后每个子树内部依然是先根节点,再左子树后右子树,递归遍历。比如下面的这个图:
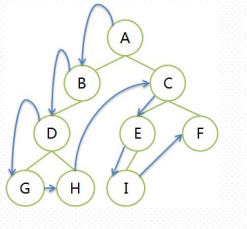
遍历序列为:A BDGH CEIF
中序遍历
中序遍历LDR是从根节点的左子树开始遍历,然后是根节点,再右子树。每个子树内部,也是先左子树,后根节点,再右子树。递归遍历。
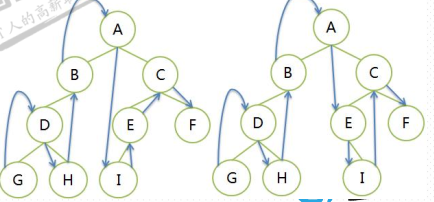
比如上面你的这两个图:左图的遍历序列为GDHB A IECF,右图的遍历序列GDHB A EICF
后序遍历
后序遍历是先左子树,后右子树,然后再根节点。每个子树内部依然是先左子树,后右子树,再根节点,递归遍历。

上图的遍历序列为 GHDB IEFC A
堆排序 heap sort
堆是一个完全二叉树,每个非叶子节点都要大于或者等于其左右孩子节点的值称为大顶堆。而每个非叶子节点都要小于或等于其左右孩子节点的值称为小顶堆。根节点一定是大顶堆中的最大值,一定是小顶堆中的最小值。
大顶堆
完全二叉树的每个非叶子节点都要大于或等于其左右孩子节点的值称为大顶堆。根节点一定是大顶堆中的最大值。如下图:
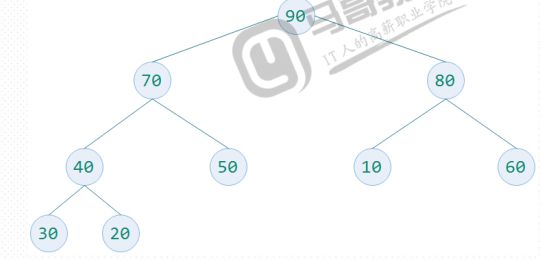
下面的这个也是大定堆
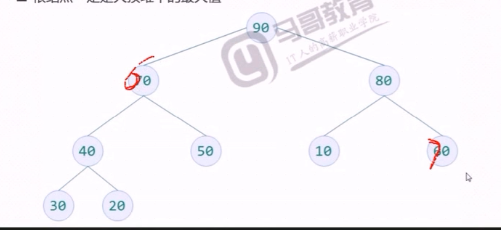
小顶堆
完全二叉树中的每个非叶子节点都要小于或等于其左右孩子节点的值称小顶堆。根节点一定是小顶堆的最小值。
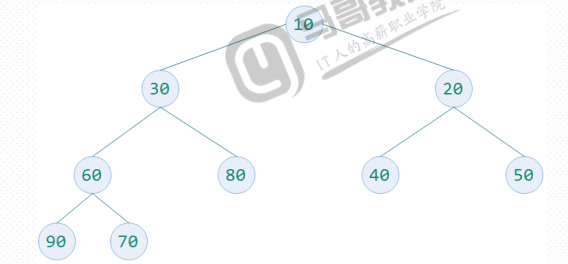
1、构建完全二叉树
待排序数字为30,20,80,40,50,10,60,70,90.构建一个完全二叉树存放数据,并根据性质5对元素编号,放入顺序的数据结构中。
构造一个列表为[0,30,20,80,40,50,10,60,70,90]
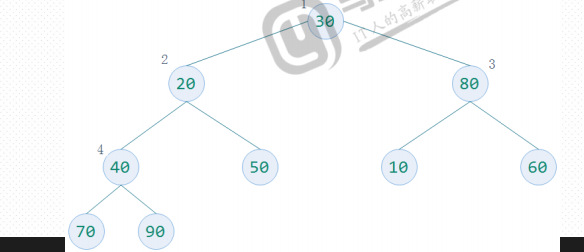
2、构建大顶堆——核心算法
度数为2的节点A,如果它的左右孩子节点的最大值比它大的,将这个最大值和该节点交换。
度数为1的节点A,如果它的左孩子的值大于它,则交换。
如果节点A被交换到新的位置,还需要和其他孩子节点重复上面的过程。
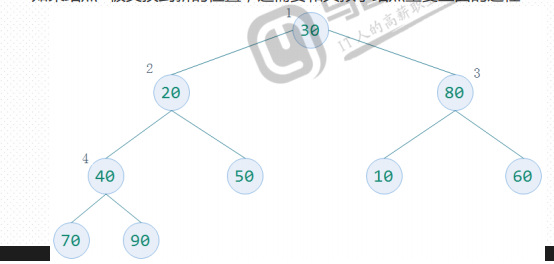
3、构建大顶堆——起点节点的选择
从完全二叉树的最后一个节点的双亲节点开始,即最后一层的最右边叶子节点的父节点开始。
节点数为n,则起始节点的编号为n//2(性质5)
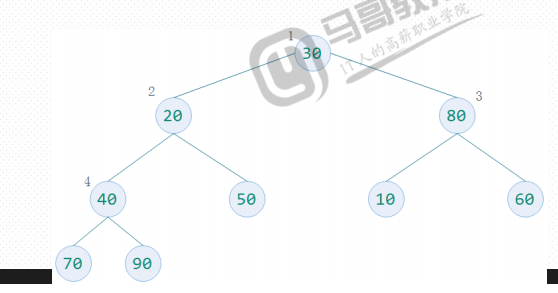
4、 构建大顶堆——下一个结点的选择
从起始结点开始向左找其同层结点,到头后再从上一层的最右边结点开始继续向左逐个查找,直至根结点。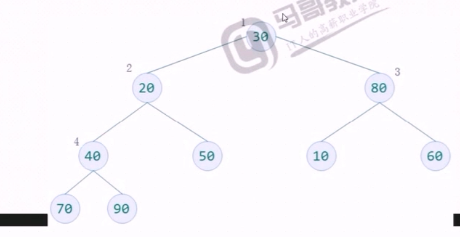
5、大顶堆的目标
确保每个结点的都比左右结点的值大 (构建大顶堆每次可能不一样,它并不是稳定的)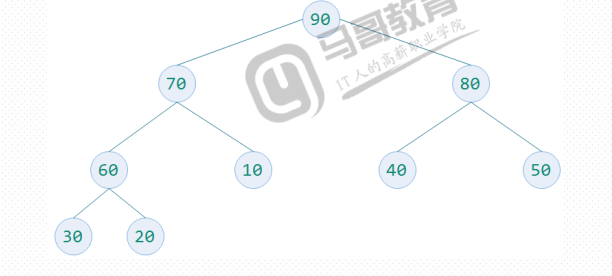
排序
将大顶堆根结点这个最大值和最后一个叶子结点交换,那么最后一个叶子结点就是最大值,将这个叶子结点排除在待排序结点之外。
从根结点开始(新的根结点),重新调整为大顶堆后,重复上一步 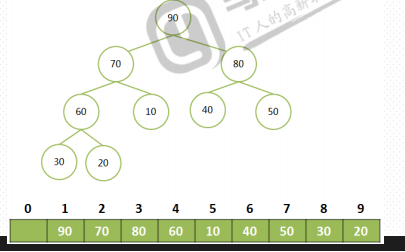
堆顶和最后一个结点交换,并排除最后一个结点 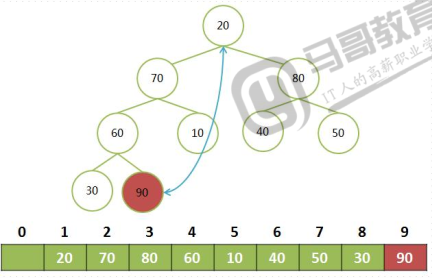

算法实现
总结
是利用堆性质的一种选择排序,在堆顶选出最大值或者最小值
时间复杂度:堆排序的时间复杂度为O(nlogn) ,由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn) 
空间复杂度 :只是使用了一个交换用的空间,空间复杂度就是O(1)
稳定性:不稳定的排序算法