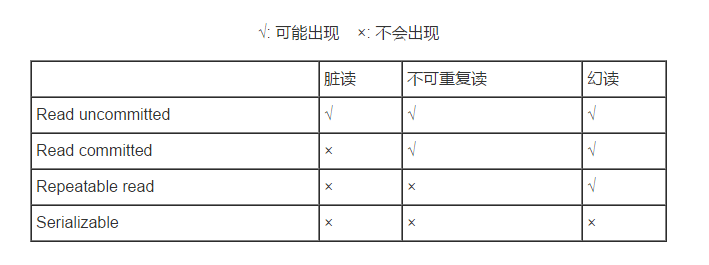
Spring事务的隔离级别
1. ISOLATION_DEFAULT(默认): 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
另外四个与JDBC的隔离级别相对应
2. ISOLATION_READ_UNCOMMITTED(未提交读): 这是事务最低的隔离级别,它充许令外一个事务可以看到这个事务未提交的数据。
这种隔离级别会产生脏读,不可重复读和幻像读。
3. ISOLATION_READ_COMMITTED(已提交读): 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
4. ISOLATION_REPEATABLE_READ(可重复读): 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。
它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
5. ISOLATION_SERIALIZABLE (串行化):这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。
除了防止脏读,不可重复读外,还避免了幻像读。
MySQL默认可重复读,Oracle默认已提交读。
静态注入和动态注入的区别
ArrayList超过初始化空间之后是如何进行扩容的?
如果通过无参构造的话,初始数组容量为0,当真正对数组进行添加时,才真正分配容量。每次按照1.5倍(位运算)的比率通过copeOf的方式扩容。
在JKD1.6中实现是,如果通过无参构造的话,初始数组容量为10,每次通过copeOf的方式扩容后容量为原来的1.5倍。
ArrayList相当于在没指定initialCapacity时就是会使用延迟分配对象数组空间,当第一次插入元素时才分配10(默认)个对象空间。
假如有20个数据需要添加,那么会分别在第一次的时候,将ArrayList的容量变为10 ;之后扩容会按照1.5倍增长。
也就是当添加第11个数据的时候,Arraylist继续扩容变为10*1.5=15;当添加第16个数据时,继续扩容变为15 * 1.5 =22个。:
向数组中添加第一个元素时,数组容量为10.
向数组中添加到第10个元素时,数组容量仍为10.
向数组中添加到第11个元素时,数组容量扩为15.
向数组中添加到第16个元素时,数组容量扩为22.
每次扩容都是通过Arrays.copyOf(elementData, newCapacity) 这样的方式实现的。
MySQL和Orale分页的区别
如果我们是通过JDBC的方式访问数据库,那么就有必要根据数据库类型采取不同的SQL分页语句,对于MySql数据库,我们可以采用limit语句进行分页,对于Oracle数据库,我们可以采用rownum的方式进行分页.
(1)MySql的Limit m,n语句
Limit后的两个参数中,参数m是起始下标,它从0开始;参数n是返回的记录数。我们需要分页的话指定这两个值即可
(2)Oracle数据库的rownum
在Oracle数据库中,分页方式没有MySql这样简单,它需要依靠rownum来实现.
Rownum表示一条记录的行号,值得注意的是它在获取每一行后才赋予.因此,想指定rownum的区间来取得分页数据在一层查询语句中是无法做到的,要分页还要进行一次查询.
SELECT * FROM
(
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM TABLE_NAME) A
WHERE ROWNUM <= 40
)
WHERE RN >= 21
其中最内层的查询SELECT * FROM TABLE_NAME表示不进行翻页的原始查询语句。ROWNUM <= 40和RN >= 21控制分页查询的每页的范围。
上面给出的这个分页查询语句,在大多数情况拥有较高的效率。分页的目的就是控制输出结果集大小,将结果尽快的返回。在上面的分页查询语句中,这种考虑主要体现在WHERE ROWNUM <= 40这句上。
选 择第21到40条记录存在两种方法,一种是上面例子中展示的在查询的第二层通过ROWNUM <= 40来控制最大值,在查询的最外层控制最小值。而另一种方式是去掉查询第二层的WHERE ROWNUM <= 40语句,在查询的最外层控制分页的最小值和最大值。这是,查询语句如下:
SELECT * FROM
(
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM TABLE_NAME) A
)
WHERE RN BETWEEN 21 AND 40
对比这两种写法,绝大多数的情况下,第一个查询的效率比第二个高得多。这是由于CBO优化模式下,Oracle可以将外层的查询条件推到内层查询中,以提高内层查询的执行效率。对于第一个查询语句,第二层的查询条件WHERE ROWNUM <= 40就可以被Oracle推入到内层查询中,这样Oracle查询的结果一旦超过了ROWNUM限制条件,就终止查询将结果返回了。而第二个查询语句,由于查询条件BETWEEN 21 AND 40是存在于查询的第三层,而Oracle无法将第三层的查询条件推到最内层(即使推到最内层也没有意义,因为最内层查询不知道RN代表什么)。因此,对于第二个查询语句,Oracle最内层返回给中间层的是所有满足条件的数据,而中间层返回给最外层的也是所有数据。数据的过滤在最外层完成,显然这个效率 要比第一个查询低得多。
上面分析的查询不仅仅是针对单表的简单查询,对于最内层查询是复杂的多表联合查询或最内层查询包含排序的情况一样有效。
说一下zk和dubbo
zookeeper相当一个文件系统,可以用来存储数据,所谓的注册到zk上去,就是把接口信息写到zk上去保存起来,通过命令可以清楚看到dubbo其实把接口调用信息全都注册到zk上了,我们通过另一个dubbo(注册在相同的zk上)去消费,dubbo上记录了接口的调用信息(ip、端口号等)就可以,通过这些信息去调用接口。
其实zookeeper只负责注册,调用方法是由dubbo去调就是zookeeper的配置管理功能体现,还有zookeeper在这里还有负载均衡的体现,dubbo上有三个默认负载均衡算法,RandomLoadBalance(随机算法),RoundRobinLoadBalance(轮询算法),LeastActiveLoadBalance(最少活跃算法),zookeeper将用你选择的算法,为你选择一台机器,因此zookeeper就帮你负载均衡了。
线程和进程的区别,线程的有几种状态
进程和线程
进程包括多个线程,一个进程可以有多个线程,每个独立运行着的程序称为一个进程,进程中最少有一个线程,简单的说进程就是操作系统的一个软件,线程就是进程中的一条执行路径
多线程的好处:多线程提高执行效率、可以提高资源利用率
从宏观意义上讲多线程同一时刻执行多个线程,微观意义上来说cpu同一时刻只执行一个线程
主线程和子线程
主线程:是指系统提供的线程,又叫main线程,由jvm虚拟机提供
子线程:需要程序员自己创建,又叫工作线程
线程从创建、运行到结束总是处于下面五个状态之一:新建状态、就绪状态、运行状态、阻塞状态及死亡状态。

单例模式中懒汉和恶汉的区别
/** * 饿汉模式 */ public class HungrySingle { private static final HungrySingle sInstance = new HungrySingle(); private HungrySingle() { } public static HungrySingle getInstance() { return sInstance; } }
在饿汉模式中,初始化变量的时候最好加上 final 关键字,这样比较严谨。
/** * 懒汉模式 */ public class LazySingle { private static LazySingle sInstance = null; private LazySingle() { } public static LazySingle getInstance() { if (sInstance == null) { sInstance = new LazySingle(); } return sInstance; } }
一般这样写的,在大多数情况下这样写是没问题的,但是如果在多线程并发执行的时候,就会很容易出现安全隐患。第一个线程进来判断sInstance==null,还没有new出实例的时候,这个时候第二个线程也进来了,判断的sInstance也是null,然后也会new出实例的,这样就不是我们所要的单例模式了,那我们就需要加锁了,使用synchronized关键字。
/** * 懒汉模式 */ public class LazySingle { private static LazySingle sInstance = null; private LazySingle() { } public static LazySingle getInstance() { synchronized (LazySingle.class) { // 加synchronized解决安全隐患 if (sInstance == null) { sInstance = new LazySingle(); } return sInstance; } } }
这样我们的安全隐患就被解决了,但是同样带来了一个问题。那就是每次都要判断锁,程序的执行效率就会比较低。所以我们就应该尽量减少判断锁的次数,以提高运行效率。加上双重判断就可以了。
/** * 懒汉模式 */ public class LazySingle { private static LazySingle sInstance = null; private LazySingle() { } public static LazySingle getInstance() { if (sInstance == null) { // 加上这个判断,减少锁的判断 synchronized (LazySingle.class) { if (sInstance == null) { sInstance = new LazySingle(); } } } return sInstance; } }
比较:
饿汉式是线程安全的,在类创建的同时就已经创建好一个静态的对象供系统使用,以后不再改变。
懒汉式如果在创建实例对象时不加上synchronized则会导致对象的访问不是线程安全的。
推荐使用第一种
从实现方式来讲他们最大的区别就是懒汉式是延时加载,它是在需要的时候才创建对象,而饿汉式在虚拟机启动的时候就会创建,
饿汉式无需关注多线程问题,但是它是加载类时创建实例,所以如果是一个工厂模式、缓存了很多实例、那么就得考虑效率问题,因为这个类一加载则把所有实例不管用不用一块创建。
懒汉式的优点是延时加载,缺点是线程不是同步的,需要进行线程同步。