上篇博文在说SQL基础的时候,有一个地方有点误导大家,文中说到SQL 中的substring()和C#中的substring()相同,这有点歧义。基本原理虽然相同,但是有一点很不一样,就是C#中索引是从0开始的,而SQL中索引是从1开始的,所以在截取的时候需要稍微注意一下,在这里也感谢给我指出来的那位朋友。其实我们很多时候在阅读别人文章的时候,如果发现其中不妥的地方,耐心的,而且清楚的指出来,不但对自己是一种提高,对作者也是一种鼓励。因为很多时候,自己能明白是一回事儿,但要描述清楚,让别人明白又是另外一回事儿。好了,开头说了几句题外话,现在切入正题。
索引-->Index,可以对经常需要查询的字段添加索引,从而增加访问速率,提高检索速度。如果说索引不太好理解,咱们换个说法,书的目录大家都知道,通俗的说,索引跟目录挺相似的。有了目录,我们可以很方便,快捷的查询书中的内容,这比一页一页翻效率要高的多。但是,书中的内容一发生变化,我们要想目录还有效的话,就得及时的更改目录。索引也一样,虽然很多时候可以提高效率,但是如果库中的数据频繁变化的话,用不用索引就得论证一下了。另外索引占空间,而且添加,更新,删除数据时也需要同步更新,因此降低了Insert,Update,Delete的速度,所以只在经常检索的字段上创建索引。还有一个地方要注意的就是,为了避免全表扫描,尽量别在索引里用like之类的模糊查询。
IN,逻辑运算符,用来查找值属于指定结婚的元组,格式用法:


//语法格式 //列名 [not] IN (常量1,常量2,常量3......) //例: SELECT Sname,Ssex from Student where sdept IN ('信息系','计算机系','数学系') //查询表中系别为信息系,计算机系或者数学系的学生
SQL中常用的字符匹配:
_ 匹配任意一个字符 %匹配0或多个字符 [] 匹配 []中的任意一个字符 [^ ]不匹配[]中的任意一个字符
请看示例:
SELECT ......Sname like '张%' --查姓张的学生信息 SELECT ......Sname like '[张李刘]%' --查姓张,姓刘,或者姓李的学生信息 SELECT ......Sname like '_[小大]%'--查名字中第二个字为大或者小的学生 SELECT ......Sname not like '刘%' --查所有不姓刘的学生信息 SELECT ......Sno like '%[^235]' --查学号最后一位不是2,3,5的学生信息
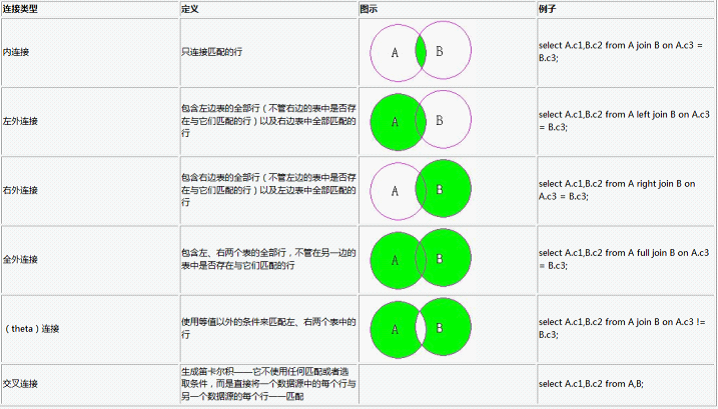
连接查询:我们在做SQL设计时,不可能将所有的信息都放入一个表,所以在查询信息的时候经常需要联合几个表来查询。不管是什么数据库,Oracle,MS SQL,DB2或者是Sybase,获取信息时连接查询都不可避免。本文将简单的说一下几个不同的连接,包括:内连接,自连接和外连接。
内连接:Inner join逻辑运算符返回满足第一个(顶端)输入与第二个(底端)输入联接的每一行。这个和用select查询多表是一样的效果,所以内连接用的比较少。还有一点要说明的就是Join 默认就是inner join。 所以我们在写内连接的时候可以省略inner 这个关键字。例:
//格式:select xxxx from 表1 join 表2 on 条件 select student.sno,sname......from student join sc on student.sno=sc.sno
自连接:相互连接的表在物理上为同一张表,但在逻辑上可以分为两张。使用自连接时必须为两个表取别名。如:查询与范冰冰在同一系学习的学生姓名和所在系。我们可以按这个思路来:先找到范冰冰在哪个系学习,在学生表中将这个表称为s1,然后找出此系所有学生,在student表中将这个表称为s2,s1和s2连接的条件就是两个表的系别相同。
select s2.sname,s2.sdept from student s2 join student s1 on s1.sdept=s2.sdept where s1.name='范冰冰' and s2.name!='范冰冰'
外连接:外连接又分左(外)连接,右(外)连接,全(外)连接。左外连接和右外连接时都会以一张表为基表,该表的内容会全部显示,然后加上两张表匹配的内容。 如果基表的数据在另一张表没有记录。 那么在相关联的结果集行中列显示为空值(NULL)。形如:
from 表1 left|right join 表2 on 条件 左连接的含义是限制表2中的数据必须满足连接条件,而不管表1中的数据是否满足连接条件,均会输出表1中的内容。右连接则正好相反。说了这么多连接可能还是有点迷糊,我也看过其他一些写SQL连接的文章,有一篇还真不错,这里借鉴一些:
关于内连接:
//1.2.1 先创建2张测试表并插入数据: SQL> select * from dave; ID NAME ---------- ---------- 1 dave 2 bl 1 bl 2 dave SQL> select * from bl; ID NAME ---------- ---------- 1 dave 2 bl //1.2.3 用内链接进行查询: SQL> Select a.id,a.name,b.name from dave a inner join bl b on a.id=b.id; -- 标准写法 ID NAME NAME ---------- ---------- ---------- 1 dave dave 2 bl bl 1 bl dave 2 dave bl SQL> Select a.id,a.name,b.name from dave a join bl b on a.id=b.id; -- 这里省略了inner 关键字 ID NAME NAME ---------- ---------- ---------- 1 dave dave 2 bl bl 1 bl dave 2 dave bl SQL> Select a.id,a.name,b.name from dave a,bl b where a.id=b.id; -- select 多表查询 ID NAME NAME ---------- ---------- ---------- 1 dave dave 2 bl bl 1 bl dave 2 dave bl
外连接:
--以下为模拟数据 SQL> select * from bl; ID NAME ---------- ---------- 1 dave 2 bl 3 big bird 4 exc 9 怀宁 SQL> select * from dave; ID NAME ---------- ---------- 8 安庆 1 dave 2 bl 1 bl 2 dave 3 dba 4 sf-express 5 dmm
左外连接(Left outer join/ left join)
left join是以左表的记录为基础的,示例中Dave可以看成左表,BL可以看成右表,它的结果集是Dave表中的数据,在加上Dave表和BL表匹配的数据。换句话说,左表(Dave)的记录将会全部表示出来,而右表(BL)只会显示符合搜索条件的记录。BL表记录不足的地方均为NULL.右外连接的结果和左外连接相反,就不举例了。
示例: SQL> select * from dave a left join bl b on a.id = b.id; ID NAME ID NAME --------- ---------- ---------- ---------- 1 bl 1 dave 1 dave 1 dave 2 dave 2 bl 2 bl 2 bl 3 dba 3 big bird 4 sf-express 4 exc 5 dmm -- 此处B表为null,因为没有匹配到 8 安庆 -- 此处B表为null,因为没有匹配到 SQL> select * from dave a left outer join bl b on a.id = b.id; ID NAME ID NAME ---------- ---------- ---------- ---------- 1 bl 1 dave 1 dave 1 dave 2 dave 2 bl 2 bl 2 bl 3 dba 3 big bird 4 sf-express 4 exc 5 dmm 8 安庆
以下这张图-1很好的表示了各连接的关系。
视图: 从数据库的基本表中选取出来的数据组成的逻辑窗口,数据库中只存放视图的定义,而不包含数据,其数据仍放在原表中。
1、单原表视图,顾名思义,从一个表中查询出来的数据,如:
create view is_student as select sno,sname,sage from student where sdept='计算机系'
2、多原表视图(建立计算机系选修了‘c01’的视图)
create view v_s1(sno,sname,grade) as select student.sno,sname,grade from student join sc on student.sno=sc.sno where sdept='计算机系' and sc.cno='c01'
3、在已有的视图上定义新的视图。类似于2,删除视图:drop view<viewname>
由于时间关系,其他的内容放到下篇写吧,希望小伙伴们能够多多包含!谢谢。
下篇会介绍一下存储过程,事务和函数,以及个人之前在面试的时候遇到的几个经典的SQL问题,还有个人用的几个比较高效的SQL写法。