第1章:数据处理技巧
案例1:
- 数据:6,0000条不明飞行物(UFO)的目击纪录和报道。主要目击纪录发生在美国。
- 问题:面对这份数据的时空维度,我们可能会有以下疑问:UFO的出现是否有周期性规律?美国的不同州出现的UFO记录如果有区别,有哪些区别?
- 主要内容:
- 日期的处理
- 字符串地名的处理
- 主要函数:
#读入“ ”制表符数据,并设置列名称read.delim(" ", sep=" ", stringAsFactors=FALSE, header=FALSE, na.string="")names()#处理畸形数据(直接删除),并转化日期字符串nchar()——字符串长度as.Date(data,format=“%Y%m%d”)#地点数据(空间维度)tryCatch()——抛出异常strsplit()——gsub()——移除字符串开头空格?lapply(<vector>,<func>)——list-apply函数(应用后返回list链表),对每一行做操作do.call(<func=rbind>,<list>)——把列表的一行一行执行rbind,列表转换成矩阵,一般和lapply连用transform()——tolower()——match(x,ref)——两个向量x和ref,x是待匹配的向量,ref是匹配向量,函数返回与x长度相同的向量,如果在ref中未找到匹配项,则默认返回NAsubset()——提取数据#统计每个州每年月的数据来观察周期性summary()——ggplot()——ggsave(<plot>,<filenmame>)print()#数据聚合seq.date(from,to,by="month")——创建日期时间序列ddply(data,.(x1,x2),nrow)——以行为单位strftime(date.range,format="%Y-%m")——把日期对象转换成一个“YYYY-MM”格式的字符串merge(data1,data2,by.x,by.y,all=TRUE)
第2章:数据分析
数据处理:数据分析和验证
1、数据分析
- 方法:用摘要表和基本可视化方法从数据中寻找隐含的模式
- 数值摘要:均值、众数、百分位数和中位数、标准差和方差
- 可视化方法:直方图、和密度估计和散点图
- 方法:交叉验证和假设检验
- 交叉验证:用另一批数据来测试在原数据集上发现的模式
- 假设检验:利用概率论来测试原始数据集上发现的模式是否是巧合
1、数据:
知道数据由何而来是区别因果关系和相关关系的唯一方法(从实验中得到,还是因没有实验数据而直接观察记录而来的)
- 数值摘要
对象:每列数据
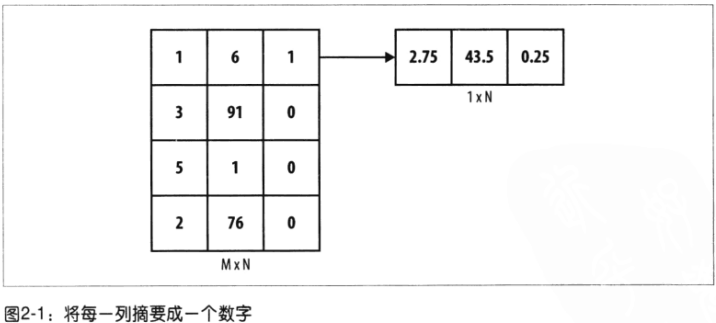
- 可视化摘要
对象:每列数据

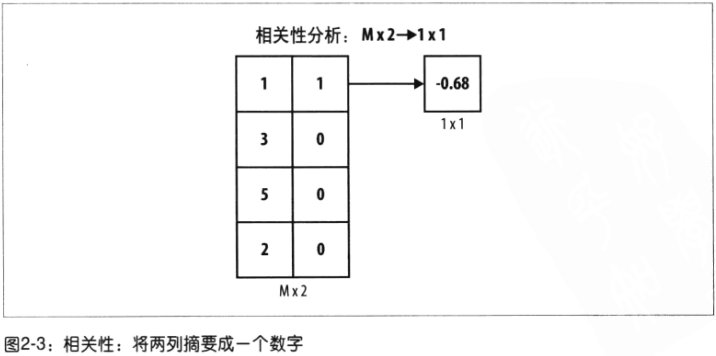
- 相关性
对象:两列数据
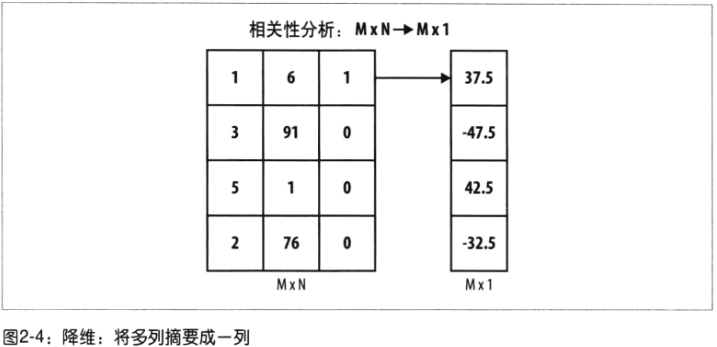
- 降维:
对象:多列数据转换为少数列
比较:
摘要统计描述的是所有数据在某一列(属性)上的特点;降维:把数据集中所有列转换成少数几列,得到的列数据每一行都是唯一的。
2、推断数据类型

虚拟变量编码dummy coding:用0和1对一个对象的定性属性进行描述。
3、数值摘要表
- 集中趋势
mean——均值
median——中位数
min——最小值
max——最大值
range——取值范围
quantile(data,prob=seq(0,1,by=0.20))——分位数
- 散步程度
var——样本方差,除数为n-1,原因:经验估算的方差会由于一些细微原因比其真值要略小
sd——样本标准差
注:摘要表中未提到的众数可视化方法的密度曲线图峰值更易解释
通过摘要表了解数据的集中程度方法是对比标准差和分位数的范围

4、可视化分析数据
ggplot()学习!
- 单列可视化:侧重数据的形状(直方图,密度曲线)
- 双列可视化:侧重两列之间的关系(散点图)
- 几种标准数据形状(分布)
4.1直方图
尝试不同的区间宽度来检验是否存在假象
- 过平滑oversmoothing:区间宽度值大,只能看到个顶峰,对称性消失
- 欠平滑undersmoothing:区间宽度值小
4.2核密度估计(Kernel Density Estimate,KDE)
密度曲线图:美观且在大数据集上更接近理论形状,有助于发现数据的模式类型。
1)期望的峰值不平坦,数据集在峰值处还隐藏着更多的结构,可以尝试将其中任意一个定性变量将曲线分开
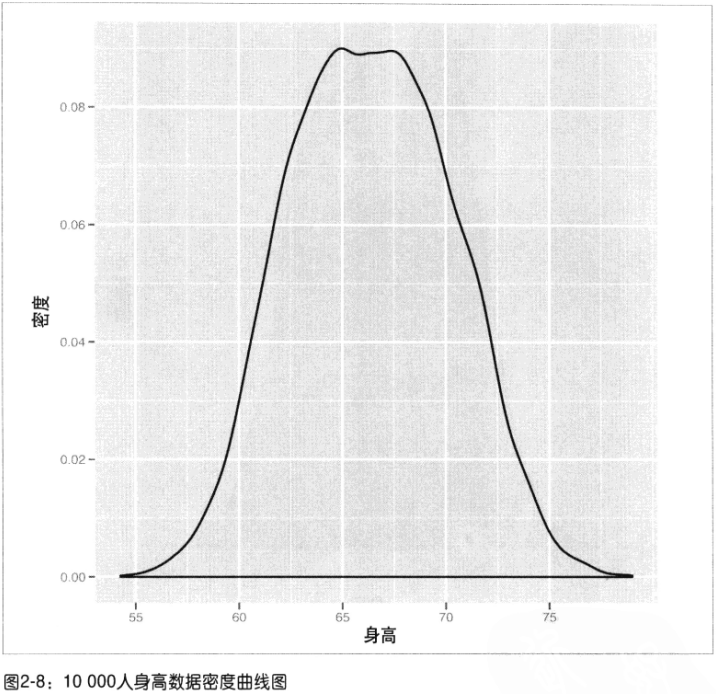
按性别区分,发现有两个隐藏的钟形曲线!

这里每一个正态分布叫一个分片(facet)
2)正态分布:(高斯分布或钟形曲线)
特点:
分布的均值:决定钟形曲线的中心所在
分布的方差:决定钟形曲线的宽度
均值和中位数是相等的,且大部分数据不偏离均值超过3个标准差的数值。
注:不是所有事物都符合正态分布:比如人们的年收入、股价每日的涨跌
3)众数:密度曲线的峰值处
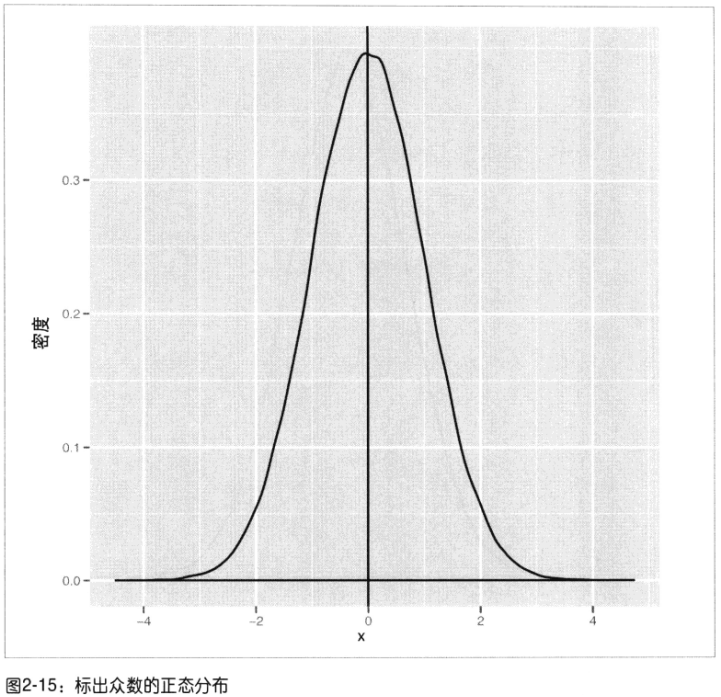
4)分布分类
分类1:
- 单峰unimodal:只有1个众数的分布
- 双峰bimodal:有2个众数的分布
- 多峰multimodal:有两个以上的众数的分布
分类2:
- 对称分布symmetric:左右两边形状一样,小于众数的数据和大于众数的数据的可能性是一样的。正态分布就有这个特点
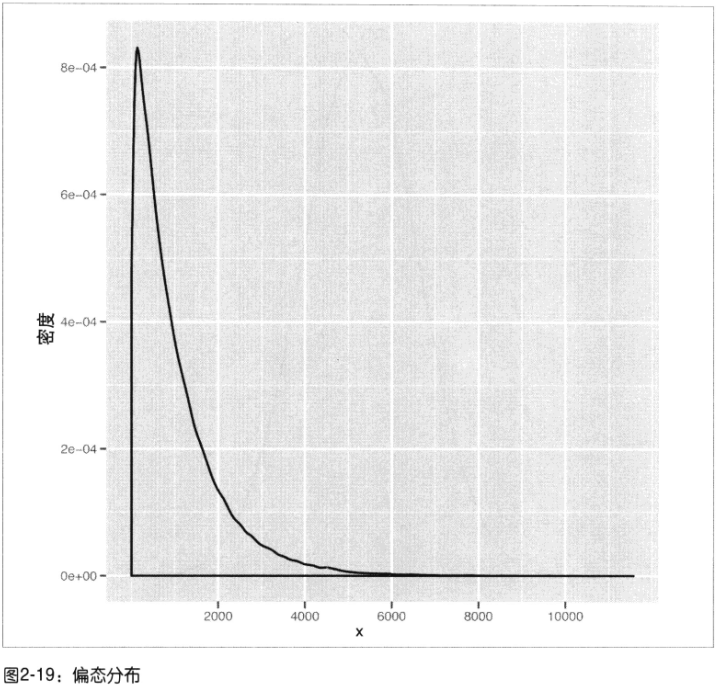
- 偏态分布skewed:
伽马分布gamma distribution:图形向右偏斜,众数右侧观察到极值的可能性要大于其左侧指数分布exponential distribution
分类3:
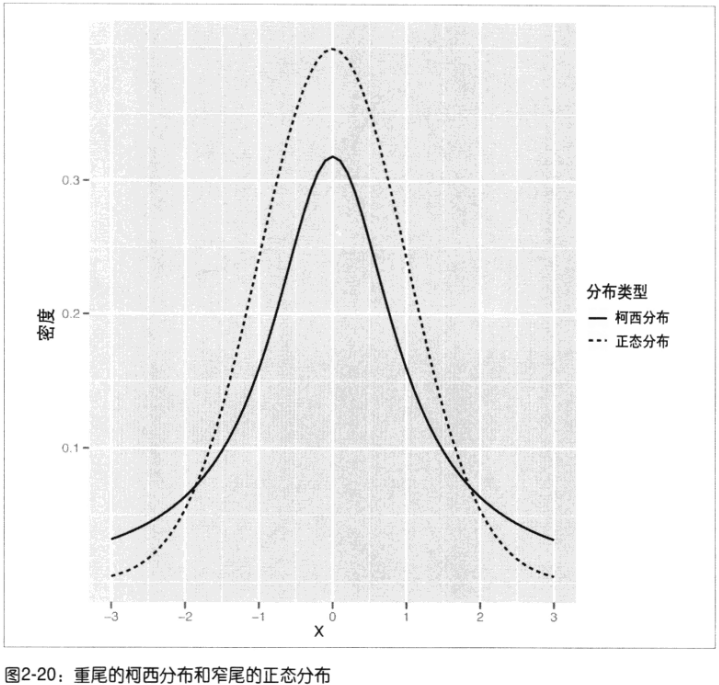
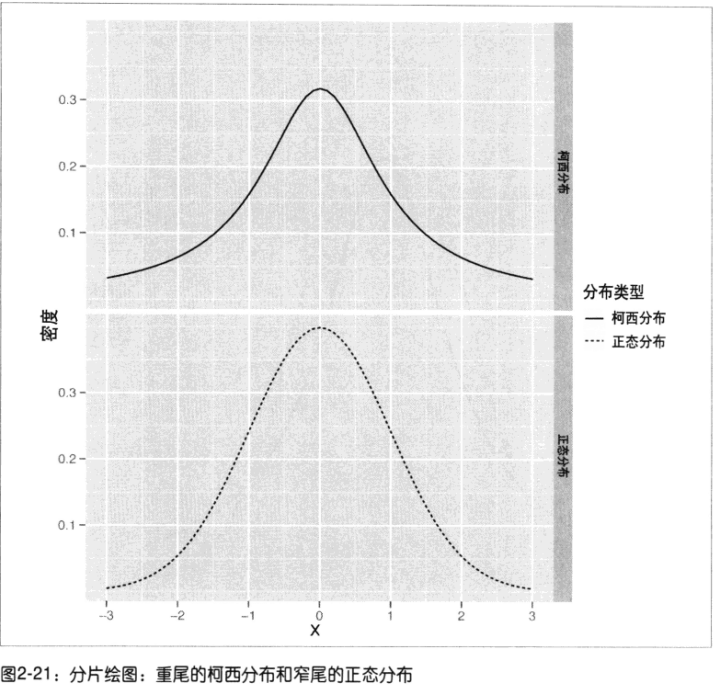
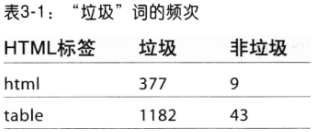
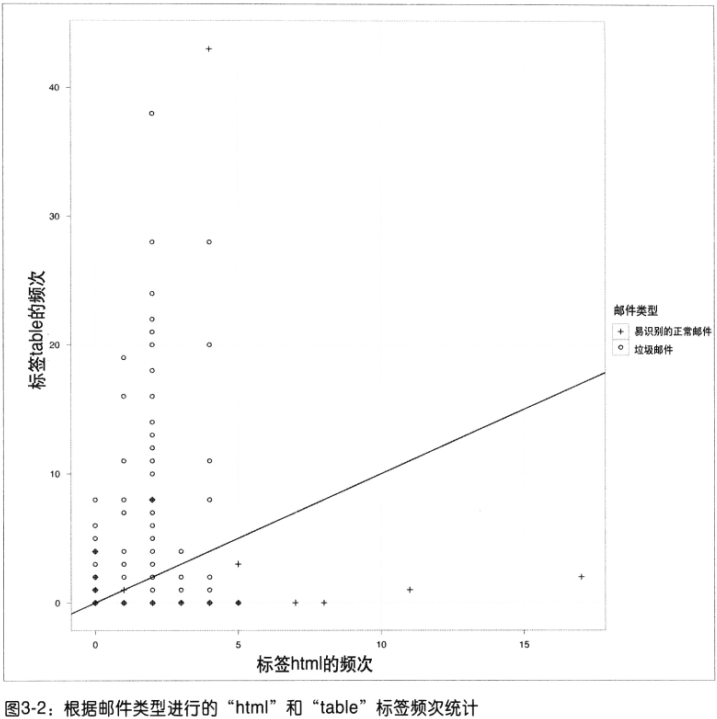
- 窄尾分布thin tailed:数值都在均值附近(99%可能性,3个标准内)正态分布
- 重尾分布heavy tailed:
柯西分布Cauchy distribution(90%在3个标准内,仍有5%可能性在6个标准值外)
比较1:
- 正态分布:单峰的、对称的,钟形的窄尾分布
- 柯西分布:单峰的、对称的,钟形的重尾分布
比较2:
- 伽玛分布:只有正值(>0)
- 指数分布:众数出现在0值处,数据集中频数最高的是0,并且只有非负值(>=0)
4.3散点图——列相关的可视化
第3章:分类
分类问题:“决策边界”
非线性分类:核方法,处理效果不错,并且几乎不增加多余计算成本
案例2:
分类判断邮件(纯文本格式的原始邮件内容)是否为垃圾邮件
文件标记为3类:垃圾邮件spam、易识别的正常邮件easy ham、不易识别的正常邮件hard ham。
1、特征提取:词频word count(“html”和”table“)、伪造的头部信息、IP地址以及黑名单等
2、文本处理:
以下散点图会发现,有多处散点重叠的线性
标准的图形化处理方法:在绘图之前给这些值增加随机噪声(抖动jittering)。
- 主要函数
tm包文本挖掘一系列函数file(path,open="rt",encoding="latin1")——open="rt"以文本形式读取readLines(<file>)——按行数据读取close(<file>)——dir()——读取目录中文件名
3、建模
训练集:垃圾邮件取500,易识别邮件500件
特征:统计词频、词的概率,该词在文本目录下所有文件出现的概率
没在训练集中出现的词频设为为较小的概率值0.0001%
总而言之就是概率判断!写得真难懂!
朴素贝叶斯分类具体参看这个:朴素贝叶斯分类器的应用
第5章 回归模型
1、基准模型:最简单的预测方法就是忽略输入,然后将过去输出值的均值作为预测结果。
2、线性回归模型所做的两个假设:
- 可分性可加性:变量之间的相互作用
- 单调性线性:线性比单调性更具约束力
3、线性回归的一般性系统问题:回归擅长内推插值(interpolation),却不擅长外推归纳。
当输入数据偏离既有输入观测数据时,预测模型一般不擅长预测其输出结果。
4、残差:(预测直线所不能解释的)误差。一个模型应该尽可能提取较多信号,并把噪声分开。尽量使残差中不存在结构。
5、衡量预测质量的指标:
- 误差平方:
缺点:取值与样本量n有关,随着数据集的增大而增大
- 均方误差(Mean Squared Errer,MSE):平方误差的均值
缺点:平均偏离误差数是呈x^2平方增长
- 均方根误差(Root Mean Squared Error,RMSE)
缺点:取值范围为无穷,不能直观的看出模型的质量
- 拟合优度 r2=r2xy(SST=Syy):
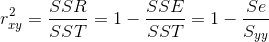
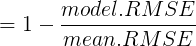
在线性回归模型中,使用R2,从公式(1-模型.RMSE/均值.RMSE)可以解释R2是比较模型结果与假设只用均值作为预测结果的好坏。取值范围为[0,1],若不如均值好,则为0;若对每个数据都做出完美解释则为1.
案例3:
预测互联网上排名前1000的网站在2011年的访问量。
其中特征变量中有因子x.f也有连续变量x.c,输出y是连续变量
- 有关y~x.c(连续型输入)的分析:
先画散点图,发现由于数值跨度的刻度值过大,使得主要数据点趋向于彼此距离很近,无法将其分开。
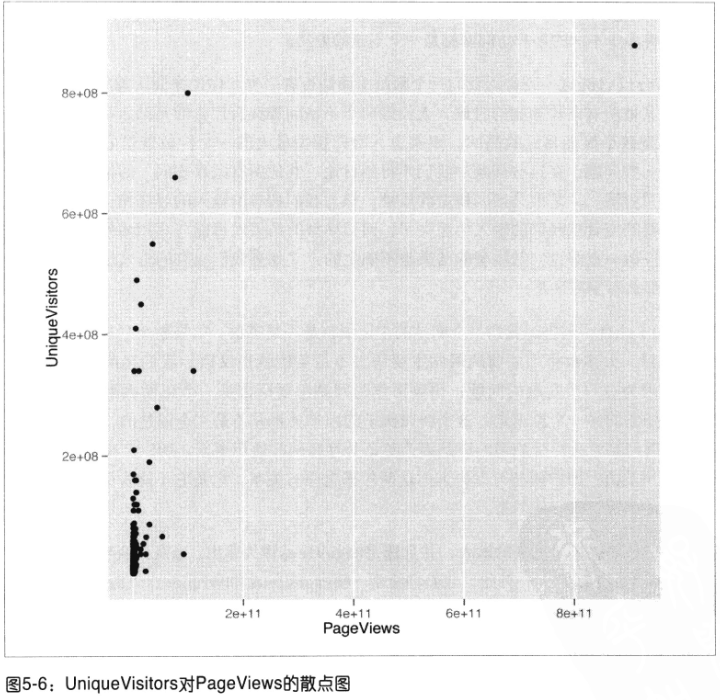
再画密度图:和散点图一样无法理解。
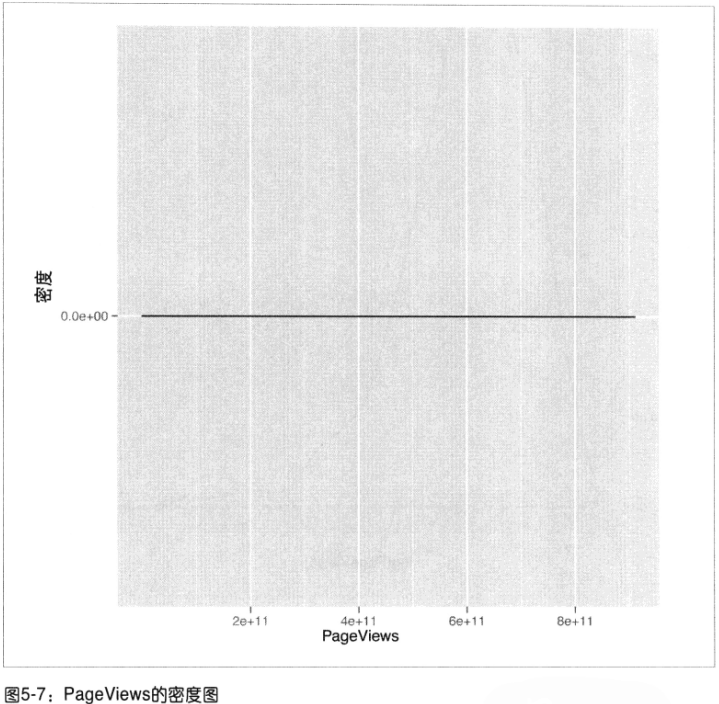
尺度变换(取log):当看到没有意义的密度图时,尝试对分析的数值取log(注:此图不必担心对0取log的错误!数值不会取0)对数螺旋曲线P126第4章
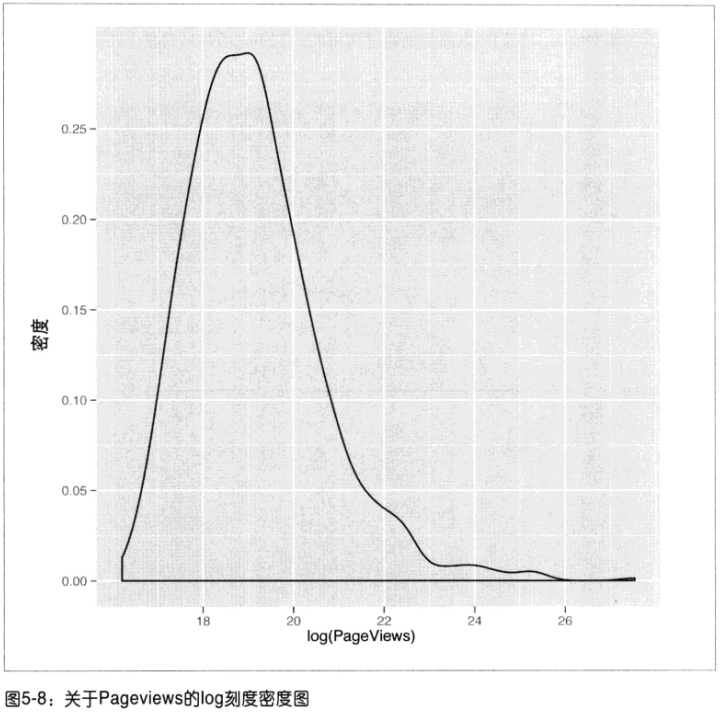
建模:lm()
评估:summary():详细解释!
1、残差的分位数2、coef()函数:
Std Error,t-value,p-value等用于评估估计参数结果的不确定性,即估计参数的置信度。t-value,p-value用于衡量对真实系数不为0有多大的信心。
一个传统的确定输入、输出相关的方法是:为这个输入找到一个距离0至少为2个标准之外的系数!(估计系数/Std.Error=t-value个标准之外)
3、Residual Standard Error是RMSE值,degree of freedom是自由度=数据点个数-系数个数。当数据较少而是用的系数过多就是一种过拟合4、R2指明数据中存在的变化有多少已经被模型所解释。在Multiple R-squared中,系数越多,就会得到越大的惩罚。5、F-statistic解释它在未知数据上的预测能力,并不是模型在用于拟合数据上的效果
- 有关y于因子输入
因子的取值情况将作为线性模型截距的一部分
如果特征变量的单独模型的R2解释能力较小,可以去掉而获取更具预测能力的输入模型。
相关性cor():相关并非因果。
第6章交叉验证和正则化
Generalized Additive Model(GAM)广义加性模型
(kernel trick)核方法基本思想是:将非线性问题转换为线性问题。
一个好的模型至少能解释90%的数据,R2大于90%
多项式回归:
- 奇异点问题:过多的增加高次项会导致与低次项之间太相关(多重共线!)以至不正常拟合,会在系数中出现NA值以及没有*标的问题(奇异点问题)无法为每个特征找到合适的权重系数。
- 过拟合问题:此时手动添加 (X^2) 不如用poly(x,degree=n)函数。因为它产生的是正交(不相关)多项式,但是高次项过多会导致过拟合问题。
解决方法:交叉验证和正则化
- 交叉验证的核心思想:把数据集分为训练集和测试集,训练集(80%)建模,测试集(20%)对模型进行检验,用RMSE来度量效果。
- 正则化:“让模型尽量拟合训练数据”与“让模型尽量保持简单“之间做出权衡
一个模型的简单与复杂可以通过模型的多项式的次数和特征变量的权重大小来衡量,权重越大模型越复杂。L2正则化(L2 norm):特征权重的平方的累加L1正则化(L1 norm):特征权重的绝对值的累加。(惩罚较强)通过交叉验证来校正正则化算法。
比较:
- 过拟合:随着次数不断增加,训练误差和测试误差变化趋势开始不一致了,即训练误差持续变小,而测试误差开始变大。
- 欠拟合:模型过于简单以致训练集都拟合不好
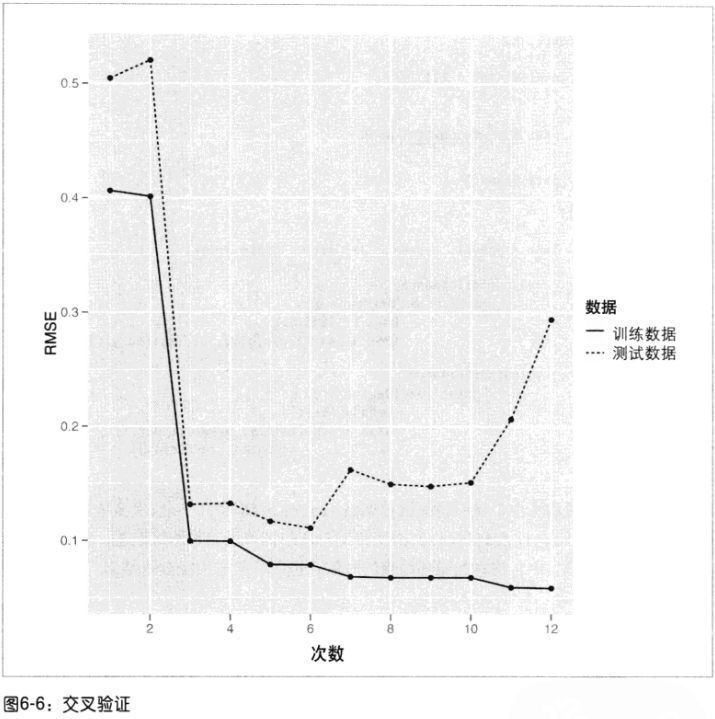
正则化操作过程:
训练正则化的线性模型的函数glmnet():执行结果的行数越前正则化越强。其输出结果的意义是:
1)DF是指明非0权重个数,但不包括截距项。可以认为大部分输入特征的权重为0时,这个模型就是稀疏的(sparse)。2)%Dev就是模型的R23)超参数(lambda)是正则化参数。lambda越大,说明越在意模型的复杂度,其惩罚越大,使得模型所有权重趋向于0。
模型最终lambda取值的选择:可以通过交叉验证,通过输入glmnet中得到的不同lambda值,用测试集验证效果好坏(RMSE评估)

案例4:文本回归
根据O‘Reilly出版社的销售前100的畅销书的逢低描述文本来预测它们的相对流行程度。
特征变量:某些单词的词频
做回归,发现lambda图效果不好,(随着lambda变大,模型越来越好,但是这种情况说明模型简化到了一个常数模型不变了!)
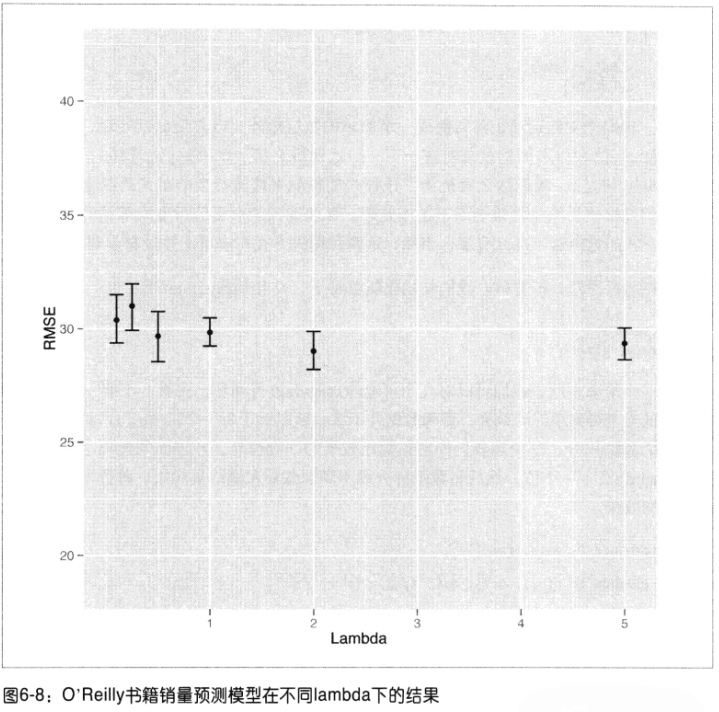
将目标改为:预测它们是否进入排名前50的而分类问题
方法:logstic回归
inv.logit()——预测值y的反logit,boot包的函数
线性回归服从高斯分布,logistic回归服从二项分布
评估:错误率
第7章 优化模型
从数据中拟合一个模型可看作是优化问题(optimization)
优化问题(分2步):
step1、为模型设定一个度量标准(线性回归就是RMSE,但是分母不变,可直接计算累加的平方误差,以节省运算时间)step2、选择最优参数a、b取值
- 方法1:网格搜索(gird search):枚举,但是耗时,并且可能会出现维度灾难(特征变量取值个数的乘积)
- 方法2:优化算法optim函数(主要用于非线性的优化求解,线性回归的最小二乘算法与optim计算结果接近)
optim(c(0,0),<func>)——优化问题函数,c(0,0)是优化函数参数的初始值,返回值par是参数最优点值,value是参数的最优点时平方误差值,counts是返回执行输入函数func的次数以及梯度gradient的次数,convergence值为0表示有把握找到最优点,非0值时对应错误,message是一些其它信息。
curve(sapply(x,<func>),<from>,<to>)——画曲线图,from和to设置横坐标取值范围
岭回归
岭回归与普通最小二乘法的唯一区别是:改变了误差函数,即岭回归把回归系数的本身当作误差项的一部分,这促使回归系数表小。

误差函数若是改用绝对值,由于绝对值误差曲线要比平方误差或岭误差曲线锋利的多,无法根据斜率的变化通过optim()找到前进的方向来确定全局最优点。如下所示:
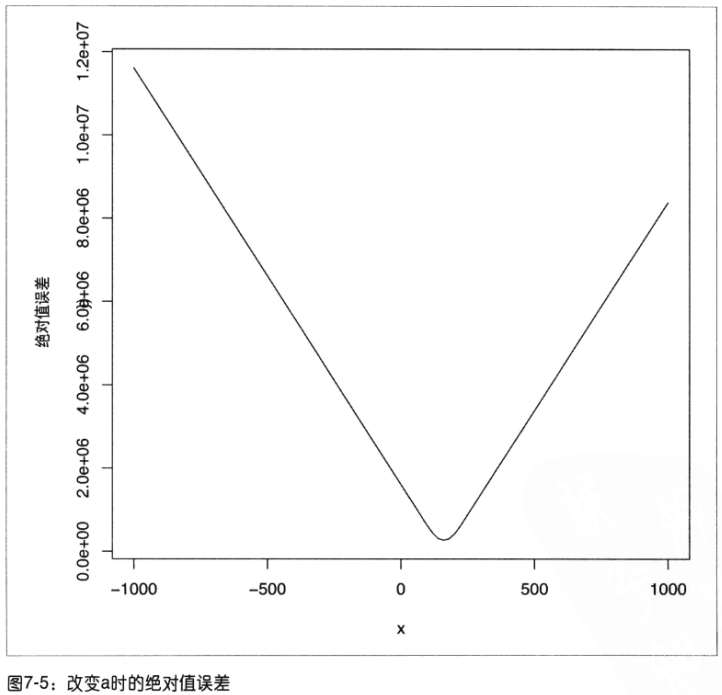
案例5:密码破译优化问题
仅通过一段密文(凯撒密码),确定这段密文对应的原文是标准的英语,该如何解码它
破解替换密码:
1、为每一种解密规则定义一个解密效果度量2、定义一个基于目前已知的解密效果最优的解密规则的算法,对它进行随机修改来生成一个新的解密规则3、定义一个算法,可以递进地生成破译效果逐渐变好的解密规则。
利用一个词典数据库来计算任何一串字符串是一个真正英文单词的概率。(由一串高概率单词组成的文本串更可能是真正的英文)
处理不存在的单词:因为它们的概率是0,去一个接近0的值
打分(1):找到两个解密串中每个单词的概率,再把它们连乘起来得到整个解密串的概率,根据概率高低来衡量2种解密规则的优劣。
替换密码(2):有解密规则生成新解密规则的算法最终归结为交换两个字母的现有规则
- 方法1:贪心忧化——只接受使解密串概率变高的新解密规则
- 方法2:
1、解密规则B的解密串概率大于A,则替换A2、解密规则B的解密串概率小于A,则以P(B)/P(A)的概率替换A
处理最终概率接近0值的方法是去对数在乘积
比较(3):由于概率高的解密规则问题不具有连续性,不能用optim函数优化来解决,就选用Metropolis方法
机器学习算法都可以看作是最小化某种预测误差的优化问题。
但是有些问题无法通过optim函数的标准优化算法(梯度下降)解决,其它优化算法有:
随机优化算法,比如:
- 模拟退火(随着循环次数的增多,越来越不能接受没有变好的规则,即越来越贪心。optim函数可以实现)
- 遗传算法
- 马尔可夫链蒙特卡洛(MCMC)
- Metropolis方法
第8章主成分分析PCA
比较:
- 有监督:从已知正确答案的训练集中学习,发现数据中的结构
- 无监督:没有任何已知答案指导的情况下,想要发现数据中的结构,比如数据降维
- 用一列信息替换多列,监管损失了信息,但在数据的可理解上获得了有价值的回报
- 数据集中每一列都是强相关的时候,PCA特别有效
方案6:股市数据的降维
2010年1月2日~2011年5月25日期间25只股票的价格
- 主要函数:
ymd()——lubridate包,将"年-月-日"格式的字符串转换成日期对象,(可以比较前后时间)
cast()——reshape包,修改原数据的组织结构,创建一个数据矩阵
cor()——相关性矩阵,结合ggplot可以观察相关性的均值和低相关出现的频率(强相关的时候PCA有效)
princomp() 和 prcomp()——主成分分析,结果的标准差显示每一个主成分的贡献率(成分方差占总方差的比例),返回值loadings每一列代表每一个成分的载荷因子
predict(<pca>)[,1]——用主成分的第一列作为原有数据的预测结果
rec()——反转数据顺序
melt(data,id.vars)——reshape包,修改数据组织结构,创建一个数据矩阵,以id.var作为每行的编号,剩余列数据取值仅作为1列数值,并用原列名作为新数值的分类标记。
第12章模型比较
支持向量机SVM
核方法:用来解决非线性决策边界。使用一个数学转换,把原始数据集转移到一个新的数学空间中,使在新空间里的决策边界是简单的(线性的)。这个转换是基于一个核函数的计算。
常用的核函数有(4种) 主要超参数
1、线性(linear)
2、多项式(polynomial) 多项式次数:degree=3(默认)先提升,最优,然后下降(过拟合)
3、径向(redial) 正则化参数:cost的增加会使模型与训练数据拟合更差一些,cost越大,决策边界越接近线性(简化)
4、S型(sigmoid) gamma越大,模型越好
缺点:大数据集上SVM要花费大量时间,一般就不调参数,指数换换核函数
模型比较:垃圾邮件比较SVM、Logitic回归和knn算法

比较结果的经验总结:
1、尝试多种模型算法:高手是知道某些特定问题不合适某些算法,需要把算法尝试一遍!
2、根据数据的内在结构筛选模型:结构在这个问题中logistic回归效果最好,其它非线性模型并不好,说明该问题的决策边界可能是线性的,最优模型一定满足数据的内在结构特征的(在商业中也是用Logistic回归来淘汰朴素贝叶斯分类器)
3、根据度量标准筛选模型参数:模型效果取决于具体的问题、数据结构特征,同时也取决于你为模型参数调优付出的努力