首字母大写---str.capitalize()
s='xuanxuan' print(s.capitalize())
输出结果就是:Xuanxuan
全部大写(小写)---str.upper() str.lower()
s='XuanXUAn' print(s.upper(),s.lower())
大小写反转---str.swapcase()
字符串中原来大写的现在变小写,原来小写的现在变大写;
s='XuanXUAn' print(s.swapcase())
每个隔开(中间有特殊字符或者数字)的部分首字母大写---str.title()
s='xuanxuan keke xixi' print(s.title()) s='xuan*ke-xixi' print(s.title())
运行结果:
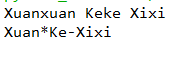
字符串居中(需设长度),可填充--str.center()
s='xuanxuankeke' print(s.center(20)) #长度20,空白填充,并且是字符串居中! print(s.center(30,'#')) #长度30,#填充
运行结果:

字符串按照tab分割,8的倍数隔开,不足补空格---str.expandtabs()
就是来一个字符串,其间可能由 分割,比如 前面的字符串是3个字符,结果就是在后面自动补5个空格,接着就是原字符串 后面的内容,如果原来字符串 前面是10个字符,结果就是在 位置补充6个空格(反正就是8的倍数,然后不空格就0k):
s='xuan keke' #xuan为4个字符,会在后面自动补充4个(8-4)个空格 print(s.expandtabs())
运行结果:
s='xuanxuanyou ekeke' #补充五个空格,前面xuanxuanyou是11个字符,会在后面补充5(16-11)个空格,再输出后面的内容 print(s.expandtabs())
运行结果:

字符串长度(不仅适用于字符串,还可用于元组,list等)---len(str)
s='xuanxuanlove' print(len(s)) #结果是12
检查字符串是否以str1开头(结尾)---str.startswith(str1,startindex,endindex) str.endswith(str1,startwith,endwith)
str1:是匹配字符串,就是看所要检查字符串是否以str1开头或者结尾;
startindex 和 endindex 是要确定从哪一部分开始检查原有字符串,如果都不写,默认是匹配全部字符串的开头结尾,写的haul就是匹配从startindex -endindex部分的子字符串
s='xuanbabylove' print(s.startswith('x')) #True print(s.startswith('xuan')) #True print(s.startswith('uan',1,6)) #True
尾部匹配也是类似:
s='xuanbabylove' print(s.endswith('love')) #True
查找元素,返回索引--str.find()
可以查找单个元素,也可以查找子字符串,找到则发挥该子串或者单个字符串的首位置,找不到则返回-1
s='xuanxuan' print(s.find('a')) #返回2 print(s.find('uan')) #返回该子串所在的位置,首位置 1 print(s.find('ubn')) #找不到这样的子串,返回-1
查找元素,返回索引---str.index()
字符串,list 也可以用index方法,用于查找原字符串匹配的子字符串索引,跟find方法很像,只不过找不到的话不再返回-1 ,而是会报错
s='xuanxuanlove' print(s.index('ua')) #找到返回1 print(s.index('sb')) #会报错
运行结果:


删除字符串收尾部分特殊字符---str.strip() str.rstrip() str.lstrip()
1.比如说有一个字符串前后有空格需要去除,strip()可以不填充,默认去除空格:
s=' xuanxuan ' print(s.strip())
输出结果:

2.如果是想去除一个字符串前后出现的其他特殊字符呢,不仅仅是上面说的空格~
s=' *&%xuanxu an %&uxa*&% ' #s字符串中首尾部分有空格,& * %特殊字符,中间也有但是不会去除 print(s.strip(' %*&')) #会去除s中首尾为空格,&,*,%,但是不会去除s中间部分的上述特殊字符
运行结果:
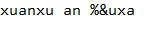
3.如果只是想去除一个字符串首部的某个特殊字符或者只是想去除字符串尾部的特殊字符(注意字符换中间的特殊字符是不能去除的):
可以使用 str.lstrip() 和 str.rstrip():
s=' *&%xuanxu an %&uxa*&% ' #s字符串中首尾部分有空格,& * %特殊字符,中间也有但是不会去除 print(s.lstrip(' *%&')) #仅去除字符串左边匹配的特殊字符 print(s.rstrip(' &*%')) #仅仅是去除字符串右边匹配的特殊字符
运行结果:
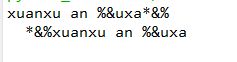
统计字符串中某个子串的个数--str.count(str1,startindex,endindex)
查找该字符串中有多少个str1,后边两个参数可选,就是规定从什么位置开始查找该子字符串,如果找不到就输出0
s='xuanxuan' print(s.count('x')) #2
字符串分割---str.split() 完成str--->list转换
s='xuanxuan;keke;fnagfang;xixi' print(s.split(';')) s='xuanxuan keke xixi' print(s.split())
运行结果:
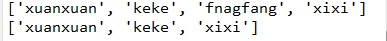
如果split()中参数缺省,则会以任意空白字符为分隔符,也就是去除所有空白字符:
s=' sdjlsd jdk sdkls sjkdk' s1=s.split() #split()函数参数缺省,则会去除所有的空白字符 print(s,' ',s1)
运行结果:
sdjlsd jdk sdkls sjkdk ['sdjlsd', 'jdk', 'sdkls', 'sjkdk']
字符串的格式化输出---str.format()
之前格式化输出采用的方法是%s %d 占位符:
name='xuan' age=22 print("my name is %s,I am %d years old" %(name,age))
现在可以采用高大上的方法format:
print("my name is{},I am {} years old and my hobbi is {}".format('xuan',22,'dog'))
也就是这里的{} 其实就相当于之前%s 和%d 这样的占位符
前面可以重复输出,使用索引
print("my name is{0},I am {1} years old and my hobbi is {2}.Repeat:my name is {0}".format('xuan',22,'dog'))
也可以打乱顺序:
print("my name is{2},I am {1} years old and my hobbi is {0}".format('dog',22,'xuan'))
字符串中某个子串替换---str.replace(old,new,count)
old 就是原有字符串中的子串
new就是你要把原有的那个子串替换成什么
count 就是原有字符串中如果有多old 你想替换掉几个
s='我爱中国,我真的很爱中国,我的家在中国!' print(s.replace('中国','河南')) #count不写,默认全部替换 print(s.replace('中国','河南',0)) #一个也不替换 print(s.replace('中国','河南',1)) #只替换第一个中国 print(s.replace('中国','河南',2)) #只替换前两个中国 print(s.replace('中国','河南',3)) #跟count不写一样,都是全部替换,因为这里只有三个中国
is系列--用于判断该字符串是否属于某一种类型
s='xuanxuan' print(s.isalpha()) #判断该字符串是不是由字母组成的 True s='xuanxuan12' print(s.isalpha()) #False n='123' print(n.isdigit()) #判断该字符串是不是由数字组成的 True s_n='xuan123' print(s.isalnum()) #判断该字符串是否由数字或字母组成 True print(s.isalnum()) #当然当字符串是纯的字母组成时,isalnum()也会返回真
for循环
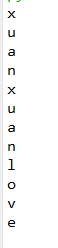
s='xuanxuanlove' for i in s: print(i)
运行结果: