问题:
如何增量同步文件,例如一个文本文件有10M,分别存放在A,B两个地方,现在两个文件是完全一样的,但是我马上要在A上对这个文件进行修改,B如何实现自动和A上的文件保持一致,并且网络的传输量最少。
应用场景:
这样的使用场景太多,这里随便列举几个
1.A机器为线上运营的机器,现在需要一台备份的机器B,当A发生宕机的时候,或者硬盘损坏等各种认为非人为原因导致数据不可用时,可以很快从B恢复
2.SVN这样的应用场景,不需要每次修改都向服务器发送并替换掉一个文件,而是只发送被修改的部分
3.手机客户端对一个文本修改,如果那个文本有2M,难道我每次更新都需要上传整个文件吗?每次2M,傻子才用!
等等....
解决方案:
一.分而治之
计算机最重要的基本算法思路就是分而治之,在我们眼里,一个文件不是一个文件,而是一堆存储块,每个存储块可能20Byte大小,至于这个值具体多大,你可以自己设定,这里的20Byte仅提供参考。通过这样的方法,一个文件被分成了很多个块,我们只需要比对块是否相同就可以得出哪个部分做了相应修改。
二.快速校验
刚上面提到如何比对文件,当然这里肯定不会把文件的每个块上传去比对,那样做就没有意义了。快速比对这不禁让我想起了哈希规则,哈希表可以通过O(1)的复杂度查找某个key,为什么? 因为它通过计算hash值来初步验证key,一个key的hash值是唯一的。但是仅仅验证hash值是不可靠的,因为hash值有可能会冲突,所以在验证完hash值后,我们在进行key的比较来确定要找的值...
通过哈希的思路,我们可以使用类似的方法来实现文件增量同步,把每一个存储块,通过MD5计算其值,然后传递MD5值到服务器,让服务器比对MD5来确定有没有被修改,如若MD5值不相等,则判定这个文件块有被修改过
为什么是MD5?
1)能够将任意长度的字符串转换为128位定长字符串(MD5 16)
2)MD5能够保证绝大部分情况下不同的值hash之后其hash值不一样,哈希冲突比较少
这样就可以了吗?
No,MD5的生成需要占用比较长的CPU时间,所以我们需要寻找一种更简洁的校验方式,这里选用Alder32 是一个比较通用的解决方案
Alder32算法实现:
A = 1 + D1 + D2 + ... + Dn (mod 65521)
B = (1 + D1) + (1 + D1 + D2) + ... + (1 + D1 + D2 + ... + Dn) (mod 65521)
= n×D1 + (n−1)×D2 + (n−2)×D3 + ... + Dn + n (mod 65521)
Adler-32(D) = B × 65536 + A
C实现版本

unsigned long adler32(unsigned char *data, int len) /* where data is the location of the data in physical memory and
len is the length of the data in bytes */
{
unsigned long a = 1, b = 0;
int index;
/* Process each byte of the data in order */
for (index = 0; index < len; ++index)
{
a = (a + data[index]) % MOD_ADLER;
b = (b + a) % MOD_ADLER;
}
return (b << 16) | a;
}
三.实现更改
因为已经找出来了文件不同的地方,所以只需要按需上传更改的部分到服务器,然后服务器做更改就可以了。
实例分析:
理论概述完毕,来点小例子子
客户端文件内容是:
taohuiissoman
而服务器的文件内容是:
itaohuiamsoman
首先,客户端开始分块并计算出MD5和Alder32值。

如上图,像taoh是一块,对taoh分别计算出MD5和alder32值。以此类推,最后一个n字母不足4位保留。于是,客户端把计算出的MD5和alder32按顺序发出,最后发出字符n。
服务器收到后,先把自己保存的File.2的内容按4字节划分。

划分出itao、huia、msom、an,当然,这些串的Alder32值肯定无法从File.1里划分出的:taoh、uiis、soma、n找出相同的。于是向后移一个字节,从t开始继续按4字节划分。
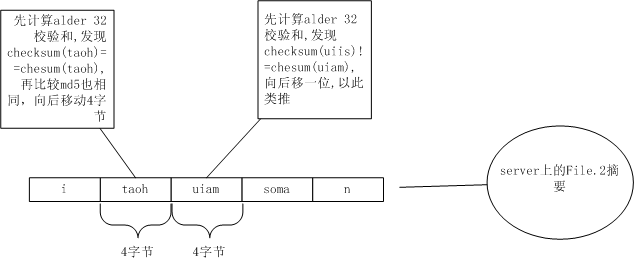
从taoh上找到了alder32相同的块,接着再比较MD5值,也相同!于是记下来,跳过taoh这4个字符,看uiam,又找不到File.1上相同的块了。继续向后跳1个字节从i开始看。还是没有找到Alder32相同,继续向后移,以此类推。

到了soma,又找到相同的块了。
重复上面的步骤,直到File.2文件结束。
通过这个简单的例子,可以设想一下其他任何的增删查改功能