一. 基于用户的协同过滤
算法思想:
当给用户A做个性化推荐时,先找到和他兴趣相似的用户,然后把这些用户喜欢的、而用户A没有听说过的物品推荐给A 。
算法步骤:
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
用户相似度计算公式
(1)Jaccard公式 :

其中u和v代表用户,N(u)用户u有过正反馈的物品集合。
(2)余弦相似度 :
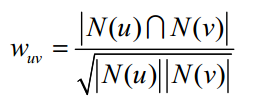
计算方法一:
直接计算出所用用户间的相似度的话,时间复杂度是O(|U|2),对于用户数目很大的数据集来说时间复杂度非常高。
计算方法二:
如果数据集中的用户数目很大,且大量用户没有相同行为,对于这样的数据集我们可以先建立一个物品到用户的倒排表(即对于每个物品,有哪些用户和他有过交互), 通过这个倒排表我们可以计算出用户有过相同行为的稠密矩阵,避免计算大量没用相同行为用户间的相似度。
python代码
def user_similarity(self): '''计算用户间的相似度矩阵''' #建立用户倒排表 item_users = defaultdict(set) for user, items in self.user_items.items(): for item in items: item_users[item].add(user) #计算用户间的余弦相似度 N = defaultdict(int) C = defaultdict(dict) for item, users in item_users.items(): for u1 in users: N[u1] += 1 for u2 in users: if u1 != u2: C[u1].setdefault(u2, 0) C[u1][u2] += 1 for u, related_users in C.items(): for related_user, _ in related_users.items(): C[u][related_user] = C[u][related_user] / math.sqrt(N[u] * N[related_user]) self.C = C #user间相似度矩阵
(3)改进后的用户相似度计算公式
上面两个公式中计算两个用户间的相似度时,所有的物品是一视同仁的,但是实际上两个用户对冷门物品采取相同的行为更能说明他们兴趣相似。
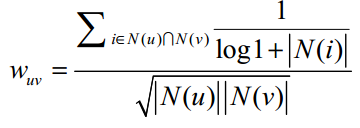
python代码
def user_similarity(self): '''计算用户间的相似度矩阵''' #建立用户倒排表 item_users = defaultdict(set) for user, items in self.user_items.items(): for item in items: item_users[item].add(user) #计算用户间的改进后相似度 N = defaultdict(int) C = defaultdict(dict) for item, users in item_users.items(): for u1 in users: N[u1] += 1 for u2 in users: if u1 != u2: C[u1].setdefault(u2, 0) C[u1][u2] += 1 / math.log(1 + len(item_users[item])) for u, related_users in C.items(): for related_user, _ in related_users.items(): C[u][related_user] = C[u][related_user] / math.sqrt(N[u] * N[related_user]) self.C = C #user间相似度矩阵
用户对物品的兴趣权重

二. 基于物品的协同过滤
步骤
(1)根据用户行为记录计算物品间的相似度。
(2)当用户对某个物品产生正反馈时,给他推荐与该物品最相似的一些物品。
UserCF和ItemCF对比

参考资料
《推荐系统实践》项亮