分布式爬虫
1、概览
该项目使用kafka和redis构建分布式爬虫集群。在多个spider实例间分发url的种子,这些请求通过redis进行协同。由于边界扩展或深度遍历的特点,任何其他抓取这些触发器的内容也将在集群中的所有工作程序之间分发。
系统的输入是一组Kafka主题,输出是一组Kafka主题。原始HTML和资源以交互方式,spider和日志输出方式进行爬网。
2、依赖
- Python 2.7:https://www.python.org/downloads/
- Redis:http://redis.io
- Zookeeper:https://zookeeper.apache.org
- kafka:http://kafka.apache.org
3、核心概念
- 蜘蛛是动态的并且是按需的,这意味着它们允许任意收集提交给抓取集群的任何网页
- 在单台计算机或多台计算机上扩展Scrapy实例
- 协调并优先处理所需站点的抓取工作
- 在刮擦作业中保留数据
- 同时执行多个抓取作业
- 允许深入访问有关您的抓取工作,即将发生的事情以及网站排名方式的信息
- 允许您在不丢失数据或停机的情况下,任意添加/删除/缩放池中的刮刀
- 利用Apache Kafka作为数据总线,用于任何应用程序与抓取集群交互(提交作业,获取信息,停止作业,查看结果)
- 允许在单独的计算机上对来自独立蜘蛛的爬网进行协调限制,但在相同的IP地址后面
4、架构
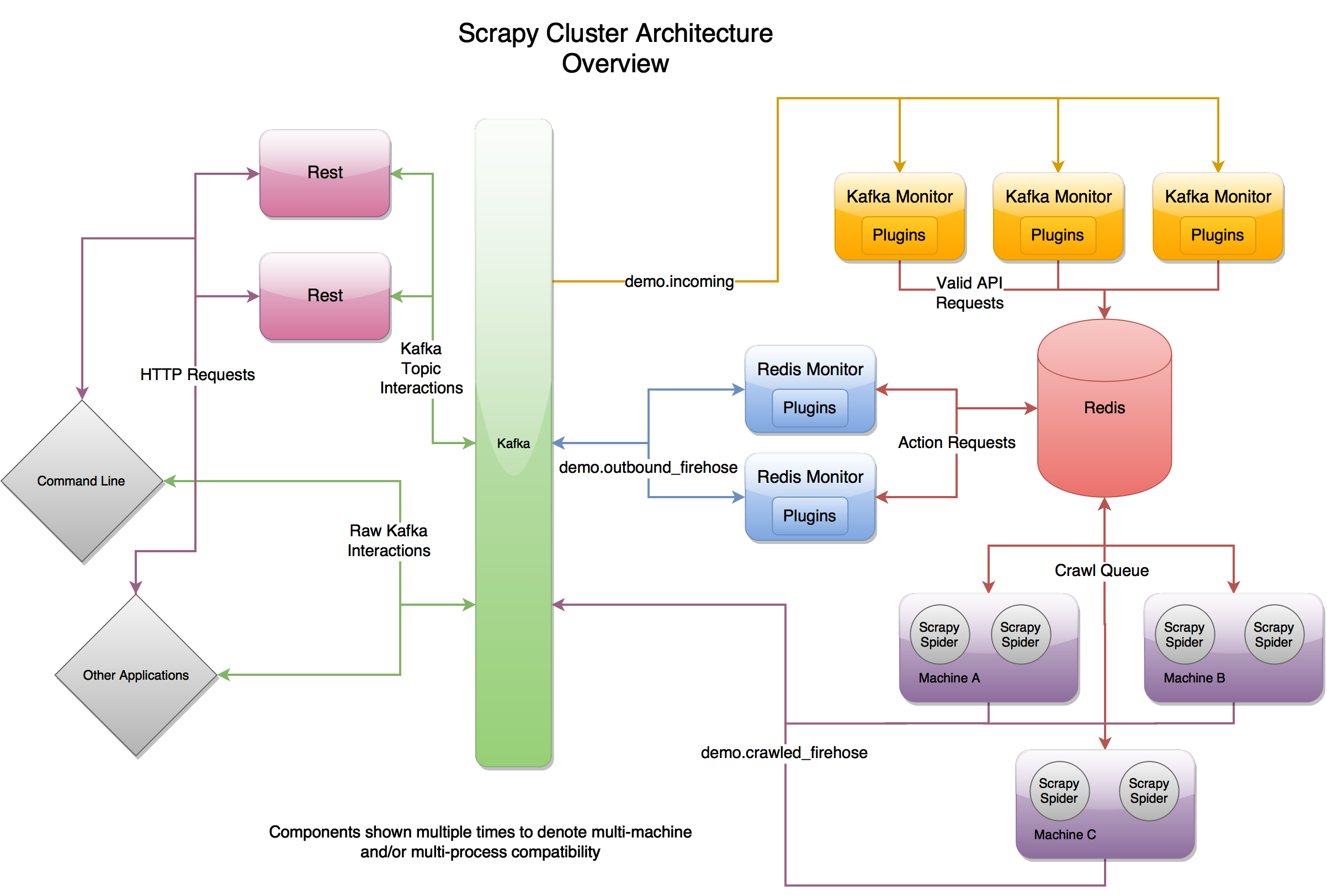
在最高级别,Scrapy Cluster运行单个输入Kafka主题,以及两个单独的输出Kafka主题。所有对群集的传入请求都要经过demo.incomingkafka主题,具体取决于请求将从demo.outbound_firehose动作请求demo.crawled_firehose主题或html爬网请求主题生成输出。
三个核心部件中的每一个都是可扩展的,以便增加或增强其功能。Kafka Monitor和Redis Monitor都使用“插件”来增强他们的能力,而Scrapy使用“中间件”,“管道”和“蜘蛛”来允许您自定义爬行。这三个组件和Rest服务一起允许跨多台计算机进行扩展和分布式爬网。