HPC&CC复习
- CUDA编程不要求, 但是会考CUDA
- 要求OpenMP和部份MPI,简单编程,可能会有大题
- 题型:
- 单选
- 简答
- 综合
复习题2020
-
解释并比较以下基本概念
- PVP, SMP, MPP, DSM, Cluster
- PVP: 并行向量处理机。系统中包含为数不多的高性能特制的向量处理器,使用专门设计的高带宽交叉开关网络将向量处理器连向共享存储模块。通常不使用高速缓存,而使用大量的向量存储器和指令缓冲器。
- UMA, NUMA, CC_NUMA, CORMA, NORMA
- HPC, HPCC, Distributed computing, Cloud computing
- PVP, SMP, MPP, DSM, Cluster
-
熟悉掌握 PVP、SMP、MPP、DSM 和 Cluster 并行机结构的不同点。
-
属性 PVP SMP MPP DSM Cluster 结构类型 MIMD MIMD MIMD MIMD MIMD 处理器类型 专用定制 商用 商用 商用 商用 互联网络 定制交叉开关 总线,交叉开关 定制网络 定制网络 商用网络 通信机制 共享变量 共享变量 消息传递 共享变量 消息传递 地址空间 单地址空间 单地址空间 多地址空间 单地址空间 多地址空间 系统存储器 集中共享 集中共享 分布非共享 分布共享 分布非共享 访存模型 UMA UMA NORMA NUMA NORMA 代表机器 Cray C-90 IBM R50 Intel Paragon, IBM Stanford DASH Berkeley NOW
-
-
列出常用静态网络和动态网络的主要参数(节点度、直径、对剖带宽和链路数)以及复 杂度、网络性能、扩展性和容错性等。
-
静态网络主要参数:程序执行期间,这种点到点的链接保持不变
-
节点度:射入或射出一个节点的边数。在单向网络中。入射和出射边之和成为节点度。
-
网络直径:网络中任何两个节点之间的最长距离,即最大路径数
-
对剖宽度:对分网络各半所必须移去的最少边数
-
对称的:如果从任一节点观看网络都一样
-
链路数:连接的个数
网络名称 网络规模 节点度 网络直径 对剖宽度 对称 链路数 线性阵列 N个节点 2 N-1 1 非 N-1 环形 N个节点 2 (lfloor N/2 floor)(双向) 2 是 N 2-D网孔 N 4 (2(N^{1/2}-1)) (N^{1/2}) 非 (2(N-N^{1/2})) Illiac网孔 (N=n^2) 4 n-1 2n 非 2N 2-D环绕 (N=n^2) 4 (2lfloor n/2 floor) 2n 是 2N 二叉树 N 3 (2(lceil log_2N ceil-1)) 1 非 N-1 星形 N N-1 2 (lfloor N/2 floor) 非 N-1 n-超立方 (N=2^n) (log_2N=n) n N/2 是 nN/2 立方环 (N=k2^k) 3 (2k-1+lfloor k/2 floor) N/(2k) 是 3N/2
-
-
动态网络:用交叉开关构成,可按应用程序的要求动态地改变连接组态
-
网络特性 硬件复杂度 每个处理器带宽 网络性能 扩展性 容错性 阻塞 总线 O(n+w) O(wf/n)~O(wf) 差 是 多级互联 O(wf) (O((nlog_kn)w)) 是 交叉开关 O(wf) (O(n^2w)) 否 -
n:节点规模。w:数据宽度。f:时钟频率
-
-
-
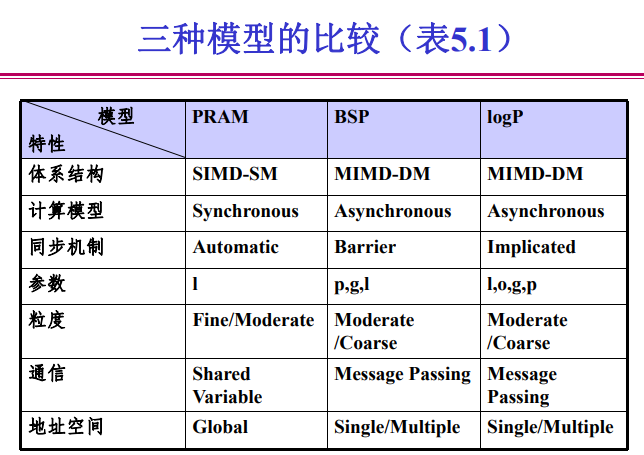
掌握并行计算模型 PRAM、BSP 和 logP,以及 PRAM-CRCW 等 PRAM 存取模式。
-
-
PRAM:Parallel Random Access Machine
-
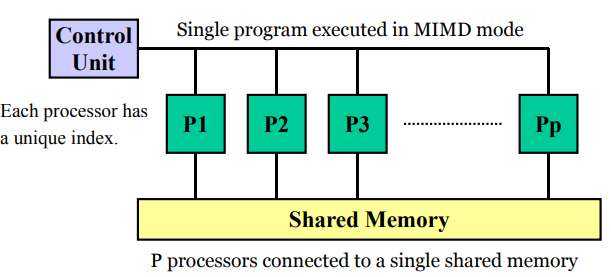
有一个集中的共享存储器和一个指令控制器,通过共享存储SM的Read/Write交换数据,隐式同步计算
-
-
全局共享存储,单一地址空间
-
同步、通信和并行化的开销为0
-
优点
- 适合并行算法表示和复杂性分析,易于使用
- 易于扩展:根据需要可以在PRAM模型中加入一些诸如同步和通信等需要考虑的内容
- 隐藏了并行机的通讯、同步等细节
-
缺点
- 不适合MIMD并行机,忽略了SM的竞争、通讯延迟等因素
- 使用了一个SM,不适合于分布共享存储结构的并行机
- PRAM模型是同步的,不能反映现实中很多系统的异步性
- PRAM模型假设了每个处理器可在单位时间访问共享存储器的任意单元,因此要求处理机间通信无延迟、无限带宽和无线开销——不现实
-
BSP:Bulk Synchronous Paralle,块同步模型
- 是一种异步MIMD-DM模型(分布式存储),支持消息传递系统,块内异步并行,块间显式同步
- 3个组成部分
- 节点:处理器,本地存储
- 通信网络:点到点,消息传递
- 同步障:同步机制
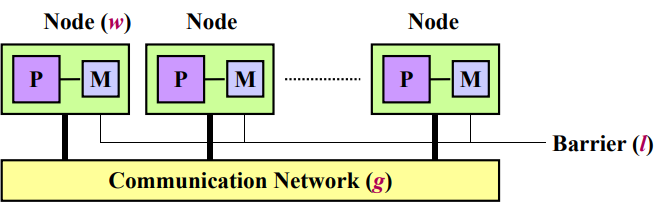
- BSP计算由若干超级步组成
- 优点
- 试图为软件和硬件之间架起一座类似于冯诺依曼机的桥梁,因此,BSP模型也常叫桥模型
- 将处理器和路由器分开,强调了计算任务和通信任务的分开,简化了通信协议
- 缺点
- 需要显式同步,编程效率不高
- 全局障碍同步假定是用特殊的硬件支持的,这在很多并行机中可能没有相应的硬件
-
logP模型:分布存储的、点到点通讯的多处理机模型
-
优化组播树
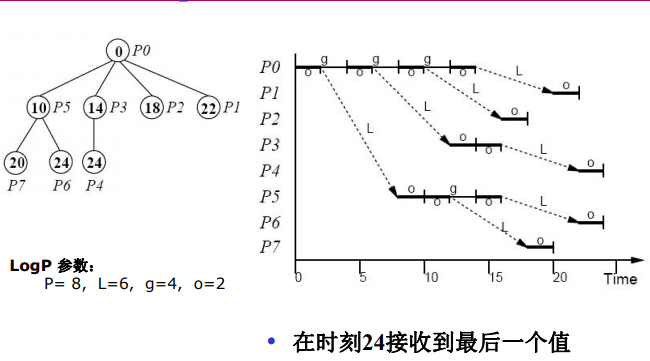
-

-
优点
- 异步模型,没有同步障
- 捕捉了并行计算机的通讯瓶颈
- 通信由一组参数描述,但不涉及具体的网络结构,隐藏了并行机的网络拓扑、路由、协议
- 可以应用到共享存储、消息传递、数据并行的编程模型中
-
缺点
- 难以进行算法描述、设计和分析
- 对网络中的通信模式描述的不够深入。
- 主要适用于消息传递算法设计
-
-
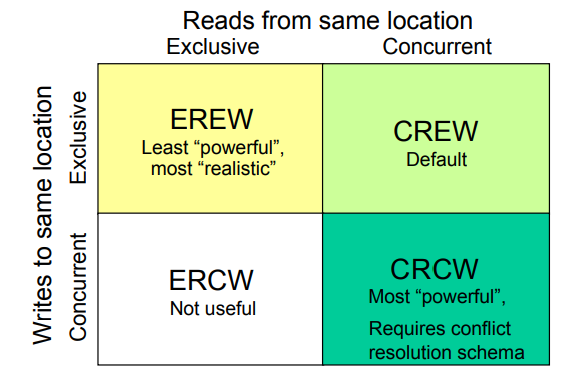
PRAM-CRCW:并发读、并发写
- 冲突解决模式:
- Common CRCW: 仅允许写入相同的数据
- Priority CRCW:仅允许优先级最高的处理器写入
- Arbitrary CRCW:运行任意处理器自由写入
- 是最强的计算模型
- 冲突解决模式:
-
-
-
-
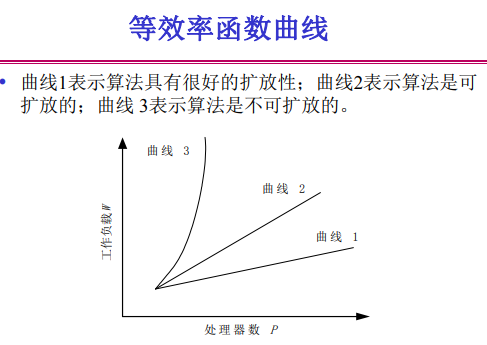
掌握加速比(speed up)、并行效率(efficiency)和可扩展(scalability)。 如何描述 在不同约束下的加速比?掌握加速比性能定理。
- 可扩展性:当系统和问题规模增大时,可维持相同性能的能力

- performance = work / time
- (speedup(p)=frac{performance(p)}{performace(l)})
- 不同约束下的加速比
- 固定问题规模PC
- Amdahl定律
- 固定问题规模PC
- 加速比性能定理
*
- 可扩展性:当系统和问题规模增大时,可维持相同性能的能力
-
如何进行并行计算机性能评测?什么是基准测试程序?
- 通过 CPU 和存储器的某些基本性能指标、并行和通信开销分析、并行机的可用性与好用性以及机器成本、价格与性价比进行机器级性能测评;
- 通过 加速比、效率、扩展性进行算法级性能测评;
- 通过Benchmark进行程序级性能测评。
- 基准测试程序:
- 用于测试和预测计算机系统的性能,揭示了不同结构机器的长处和短 处,为用户决定购买和使用哪种机器最适合他们的应用要求提供决策
-
什么是分治策略的基本思想?举例说明如何应用平衡树方法、倍增技术和流水线技术。
- 分治策略基本思想:将一个大而复杂的问题分解成若干特性相同的子问题分而治之。
- 平衡树:可用于求n个数的最大值。叶节点存放待处理的数据,内节点执行相应子问题计算,根节点给出问题的解。
- 倍增技术:可以应用于求森林根。对于n个节点的树执行logn此指针跳跃即可找到书的根。
- 流水线技术:可应用于执行以为脉动阵列上的DFT计算
-
掌握均匀划分、方根划分、对数划分和功能划分等。如何用划分方法解决 PSRS 排序、 归并排序和(m,n)选择问题?
-
并行算法设计的一般过程 PCAM 是指什么?各个步骤中的主要判据是什么?
- PCAM:是Partitioning(划分)、Communication(通信)、Agglomeration(组合)和Mapping(映射)首字母拼写。代表了使用此法设计并行算法的四个阶段。
- 划分判据:
- 划分是否具有灵活性
- 划分是否避免了冗余计算和存储
- 划分任务尺寸是否大致相当
- 任务数与问题尺寸是否成比例
- 功能分解是一种更深层次的分解,是否合理
- 通信判据:
- 所有任务是否执行大致相当的通信?
- 是否尽可能的局部通信
- 通信操作是否能并行执行
- 同步任务的计算能否并行执行
- 组合判据:
- 增加粒度是否减少了通信成本
- 重复计算是否已权衡了其得益
- 是否保持了灵活性和可扩展性
- 组合的任务数是否与问题尺寸成比例
- 是否保持了类似的计算和特性
- 有没有减少并行执行的机会
- 映射判据:
- 采用集中式负载平衡方案,是否存在通信瓶颈
- 采用动态负载平衡方案,调度策略的成本如何?
-
理解算法 6.2(并行快排序),7.1(PSRS 排序算法),7.8(求最大值算法),7.9(求前 缀和算法)。
-
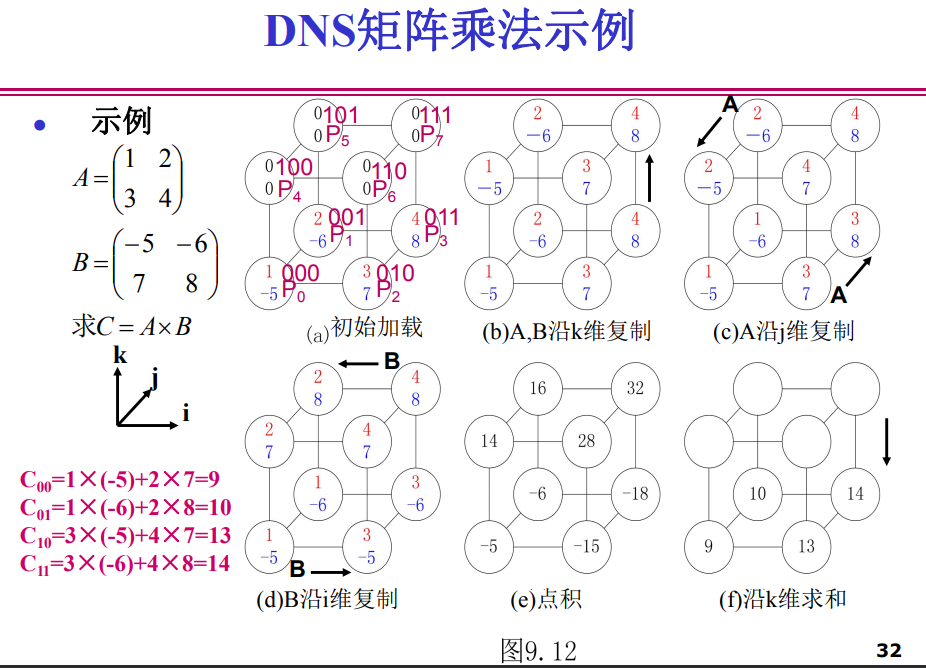
掌握并行矩阵乘法的基本方法,掌握简单分块并行算法、9.5(Cannon 算法),9.6(DNS 算法)的基本原理和算法过程。
-
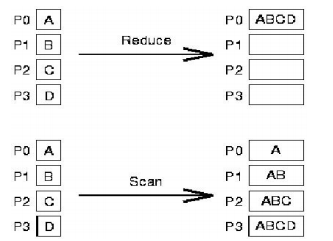
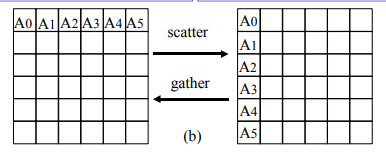
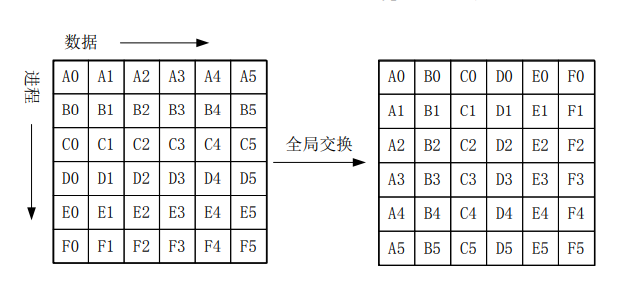
掌握进程通信的同步方式和聚集方式。列举主要的通信模式。
- 通信模式
- 通信模式
-
理解共享存储编程模型和分布存储编程模型的特征及差异。
- 共享存储编程模型
- 多线程:SPMD,MPMD
- 异步
- 显式同步
- 单一地址空间
- 隐式数据分布
- 隐式通信
- 分布存储编程模型
- 多地址空间
- 消息传递通信
- 编程、移植困难
- 可伸缩性
- 单地址空间
- 共享存储编程模型
-
什么是 OpenMP 的编程模型、体系结构、控制结构和数据域子句?
-
什么是 MPI 的消息、数据类型、通信域?
-
什么是 MPI 的阻塞通信和非阻塞通信?点到点通信模式有哪些?MPI 群集通信模式?
-
熟悉掌握用 OpenMP 和 MPI 编写计算圆周率 Pi、计算内积等简单例程和代码;熟悉掌 握 OpenMP 的基本编程方法和不同的并行化控制方法。
-
掌握 Map/Reduce 的体系结构和工作原理,理解 Word Count 算法的 Map/Reduce 算法原 理,负载均衡和容错方法;
-
掌握 GFS 的系统结构、特点和数据修改等流程,容错方法。
-
理解 GPU 结构和 CUDA 编程的基本概念。
- GPU
- 将芯片上的大部分区域用于计算逻辑
- GPU Core比较轻,用于优化具有简单控制逻辑的数据并行任务,注重并行程序的吞吐量
- 异构架构:GPU作为CPU的协处理器,GPU通过PCIe总线与CPU相连
- CUDA编程:采用单指令多线程SIMT,共享内存
- 编程模型
- 线程
- 线程块
- 线程网络
- 执行模型
- 流多处理器
- 流处理器:SP
- 流多处理器:SM
- 线程束
- 流多处理器
- 内存层次结构
- 编程模型
- GPU
-
CUDA 和 Map/Reduce 不要求具体代码编写。
-
掌握课后习题、作业和课堂练习题。