参考:
https://www.cnblogs.com/jay36/p/7680008.html
https://blog.csdn.net/weixin_42447959/article/details/81637909
JVM调优总结-调优方法
JVM调优工具
Jconsole,jProfile,VisualVM
Jconsole : jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用。对垃圾回收算法有很详细的跟踪。详细说明参考这里
JProfiler:商业软件,需要付费。功能强大。详细说明参考这里
VisualVM:JDK自带,功能强大,与JProfiler类似。推荐。
如何调优
观察内存释放情况、集合类检查、对象树
上面这些调优工具都提供了强大的功能,但是总的来说一般分为以下几类功能
堆信息查看

可查看堆空间大小分配(年轻代、年老代、持久代分配)
提供即时的垃圾回收功能
垃圾监控(长时间监控回收情况)

查看堆内类、对象信息查看:数量、类型等

对象引用情况查看
有了堆信息查看方面的功能,我们一般可以顺利解决以下问题:
--年老代年轻代大小划分是否合理
--内存泄漏
--垃圾回收算法设置是否合理
线程监控

线程信息监控:系统线程数量。
线程状态监控:各个线程都处在什么样的状态下

Dump线程详细信息:查看线程内部运行情况
死锁检查
热点分析

CPU热点:检查系统哪些方法占用的大量CPU时间
内存热点:检查哪些对象在系统中数量最大(一定时间内存活对象和销毁对象一起统计)
这两个东西对于系统优化很有帮助。我们可以根据找到的热点,有针对性的进行系统的瓶颈查找和进行系统优化,而不是漫无目的的进行所有代码的优化。
快照
快照是系统运行到某一时刻的一个定格。在我们进行调优的时候,不可能用眼睛去跟踪所有系统变化,依赖快照功能,我们就可以进行系统两个不同运行时刻,对象(或类、线程等)的不同,以便快速找到问题
举例说,我要检查系统进行垃圾回收以后,是否还有该收回的对象被遗漏下来的了。那么,我可以在进行垃圾回收前后,分别进行一次堆情况的快照,然后对比两次快照的对象情况。
内存泄漏检查
内存泄漏是比较常见的问题,而且解决方法也比较通用,这里可以重点说一下,而线程、热点方面的问题则是具体问题具体分析了。
内存泄漏一般可以理解为系统资源(各方面的资源,堆、栈、线程等)在错误使用的情况下,导致使用完毕的资源无法回收(或没有回收),从而导致新的资源分配请求无法完成,引起系统错误。
内存泄漏对系统危害比较大,因为他可以直接导致系统的崩溃。
需要区别一下,内存泄漏和系统超负荷两者是有区别的,虽然可能导致的最终结果是一样的。内存泄漏是用完的资源没有回收引起错误,而系统超负荷则是系统确实没有那么多资源可以分配了(其他的资源都在使用)。
年老代堆空间被占满
异常: java.lang.OutOfMemoryError: Java heap space
说明:

这是最典型的内存泄漏方式,简单说就是所有堆空间都被无法回收的垃圾对象占满,虚拟机无法再在分配新空间。
如上图所示,这是非常典型的内存泄漏的垃圾回收情况图。所有峰值部分都是一次垃圾回收点,所有谷底部分表示是一次垃圾回收后剩余的内存。连接所有谷底的点,可以发现一条由底到高的线,这说明,随时间的推移,系统的堆空间被不断占满,最终会占满整个堆空间。因此可以初步认为系统内部可能有内存泄漏。(上面的图仅供示例,在实际情况下收集数据的时间需要更长,比如几个小时或者几天)
解决:
这种方式解决起来也比较容易,一般就是根据垃圾回收前后情况对比,同时根据对象引用情况(常见的集合对象引用)分析,基本都可以找到泄漏点。
持久代被占满
异常:java.lang.OutOfMemoryError: PermGen space
说明:
Perm空间被占满。无法为新的class分配存储空间而引发的异常。这个异常以前是没有的,但是在Java反射大量使用的今天这个异常比较常见了。主要原因就是大量动态反射生成的类不断被加载,最终导致Perm区被占满。
更可怕的是,不同的classLoader即便使用了相同的类,但是都会对其进行加载,相当于同一个东西,如果有N个classLoader那么他将会被加载N次。因此,某些情况下,这个问题基本视为无解。当然,存在大量classLoader和大量反射类的情况其实也不多。
解决:
1. -XX:MaxPermSize=16m
2. 换用JDK。比如JRocket。
堆栈溢出
异常:java.lang.StackOverflowError
说明:这个就不多说了,一般就是递归没返回,或者循环调用造成
线程堆栈满
异常:Fatal: Stack size too small
说明:java中一个线程的空间大小是有限制的。JDK5.0以后这个值是1M。与这个线程相关的数据将会保存在其中。但是当线程空间满了以后,将会出现上面异常。
解决:增加线程栈大小。-Xss2m。但这个配置无法解决根本问题,还要看代码部分是否有造成泄漏的部分。
系统内存被占满
异常:java.lang.OutOfMemoryError: unable to create new native thread
说明:
这个异常是由于操作系统没有足够的资源来产生这个线程造成的。系统创建线程时,除了要在Java堆中分配内存外,操作系统本身也需要分配资源来创建线程。因此,当线程数量大到一定程度以后,堆中或许还有空间,但是操作系统分配不出资源来了,就出现这个异常了。
分配给Java虚拟机的内存愈多,系统剩余的资源就越少,因此,当系统内存固定时,分配给Java虚拟机的内存越多,那么,系统总共能够产生的线程也就越少,两者成反比的关系。同时,可以通过修改-Xss来减少分配给单个线程的空间,也可以增加系统总共内生产的线程数。
解决:
1. 重新设计系统减少线程数量。
2. 线程数量不能减少的情况下,通过-Xss减小单个线程大小。以便能生产更多的线程。
JVM性能调优
1、JVM调优目标:使用较小的内存占用来获得较高的吞吐量或者较低的延迟。
程序在上线前的测试或运行中有时会出现一些大大小小的JVM问题,比如cpu load过高、请求延迟、tps降低等,甚至出现内存泄漏(每次垃圾收集使用的时间越来越长,垃圾收集频率越来越高,每次垃圾收集清理掉的垃圾数据越来越少)、内存溢出导致系统崩溃,因此需要对JVM进行调优,使得程序在正常运行的前提下,获得更高的用户体验和运行效率。
这里有几个比较重要的指标:
-
内存占用:程序正常运行需要的内存大小。
-
延迟:由于垃圾收集而引起的程序停顿时间。
-
吞吐量:用户程序运行时间占用户程序和垃圾收集占用总时间的比值。
当然,和CAP原则一样,同时满足一个程序内存占用小、延迟低、高吞吐量是不可能的,程序的目标不同,调优时所考虑的方向也不同,在调优之前,必须要结合实际场景,有明确的的优化目标,找到性能瓶颈,对瓶颈有针对性的优化,最后进行测试,通过各种监控工具确认调优后的结果是否符合目标。
2、JVM调优工具
(1)调优可以依赖、参考的数据有系统运行日志、堆栈错误信息、gc日志、线程快照、堆转储快照等。
①系统运行日志:系统运行日志就是在程序代码中打印出的日志,描述了代码级别的系统运行轨迹(执行的方法、入参、返回值等),一般系统出现问题,系统运行日志是首先要查看的日志。
②堆栈错误信息:当系统出现异常后,可以根据堆栈信息初步定位问题所在,比如根据“java.lang.OutOfMemoryError: Java heap space”可以判断是堆内存溢出;根据“java.lang.StackOverflowError”可以判断是栈溢出;根据“java.lang.OutOfMemoryError: PermGen space”可以判断是方法区溢出等。
③GC日志:程序启动时用 -XX:+PrintGCDetails 和 -Xloggc:/data/jvm/gc.log 可以在程序运行时把gc的详细过程记录下来,或者直接配置“-verbose:gc”参数把gc日志打印到控制台,通过记录的gc日志可以分析每块内存区域gc的频率、时间等,从而发现问题,进行有针对性的优化。
比如如下一段GC日志:
-
2018-08-02T14:39:11.560-0800: 10.171: [GC [PSYoungGen: 30128K->4091K(30208K)] 51092K->50790K(98816K), 0.0140970 secs] [Times: user=0.02 sys=0.03, real=0.01 secs]
-
2018-08-02T14:39:11.574-0800: 10.185: [Full GC [PSYoungGen: 4091K->0K(30208K)] [ParOldGen: 46698K->50669K(68608K)] 50790K->50669K(98816K) [PSPermGen: 2635K->2634K(21504K)], 0.0160030 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
-
2018-08-02T14:39:14.045-0800: 12.656: [GC [PSYoungGen: 14097K->4064K(30208K)] 64766K->64536K(98816K), 0.0117690 secs] [Times: user=0.02 sys=0.01, real=0.01 secs]
-
2018-08-02T14:39:14.057-0800: 12.668: [Full GC [PSYoungGen: 4064K->0K(30208K)] [ParOldGen: 60471K->401K(68608K)] 64536K->401K(98816K) [PSPermGen: 2634K->2634K(21504K)], 0.0102020 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
上面一共是4条GC日志,来看第一行日志,“2018-08-02T14:39:11.560-0800”是精确到了毫秒级别的UTC 通用标准时间格式,配置了“-XX:+PrintGCDateStamps”这个参数可以跟随gc日志打印出这种时间戳,“10.171”是从JVM启动到发生gc经过的秒数。第一行日志正文开头的“[GC”说明这次GC没有发生Stop-The-World(用户线程停顿),第二行日志正文开头的“[Full GC”说明这次GC发生了Stop-The-World,所以说,[GC和[Full GC跟新生代和老年代没关系,和垃圾收集器的类型有关系,如果直接调用System.gc(),将显示[Full GC(System)。接下来的“[PSYoungGen”、“[ParOldGen”表示GC发生的区域,具体显示什么名字也跟垃圾收集器有关,比如这里的“[PSYoungGen”表示Parallel Scavenge收集器,“[ParOldGen”表示Serial Old收集器,此外,Serial收集器显示“[DefNew”,ParNew收集器显示“[ParNew”等。再往后的“30128K->4091K(30208K)”表示进行了这次gc后,该区域的内存使用空间由30128K减小到4091K,总内存大小为30208K。每个区域gc描述后面的“51092K->50790K(98816K), 0.0140970 secs”进行了这次垃圾收集后,整个堆内存的内存使用空间由51092K减小到50790K,整个堆内存总空间为98816K,gc耗时0.0140970秒。
④线程快照:顾名思义,根据线程快照可以看到线程在某一时刻的状态,当系统中可能存在请求超时、死循环、死锁等情况是,可以根据线程快照来进一步确定问题。通过执行虚拟机自带的“jstack pid”命令,可以dump出当前进程中线程的快照信息,更详细的使用和分析网上有很多例,这篇文章写到这里已经很长了就不过多叙述了,贴一篇博客供参考:http://www.cnblogs.com/kongzhongqijing/articles/3630264.html
⑤堆转储快照:程序启动时可以使用 “-XX:+HeapDumpOnOutOfMemory” 和 “-XX:HeapDumpPath=/data/jvm/dumpfile.hprof”,当程序发生内存溢出时,把当时的内存快照以文件形式进行转储(也可以直接用jmap命令转储程序运行时任意时刻的内存快照),事后对当时的内存使用情况进行分析。
(2)JVM调优工具
①用 jps(JVM process Status)可以查看虚拟机启动的所有进程、执行主类的全名、JVM启动参数,比如当执行了JPSTest类中的main方法后(main方法持续执行),执行 jps -l可看到下面的JPSTest类的pid为31354,加上-v参数还可以看到JVM启动参数。
-
3265
-
32914 sun.tools.jps.Jps
-
31353 org.jetbrains.jps.cmdline.Launcher
-
31354 com.danny.test.code.jvm.JPSTest
-
380
②用jstat(JVM Statistics Monitoring Tool)监视虚拟机信息
jstat -gc pid 500 10 :每500毫秒打印一次Java堆状况(各个区的容量、使用容量、gc时间等信息),打印10次
-
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
-
11264.0 11264.0 11202.7 0.0 11776.0 1154.3 68608.0 36238.7 - - - - 14 0.077 7 0.049 0.126
-
11264.0 11264.0 11202.7 0.0 11776.0 4037.0 68608.0 36238.7 - - - - 14 0.077 7 0.049 0.126
-
11264.0 11264.0 11202.7 0.0 11776.0 6604.5 68608.0 36238.7 - - - - 14 0.077 7 0.049 0.126
-
11264.0 11264.0 11202.7 0.0 11776.0 9487.2 68608.0 36238.7 - - - - 14 0.077 7 0.049 0.126
-
11264.0 11264.0 0.0 0.0 11776.0 258.1 68608.0 58983.4 - - - - 15 0.082 8 0.059 0.141
-
11264.0 11264.0 0.0 0.0 11776.0 3076.8 68608.0 58983.4 - - - - 15 0.082 8 0.059 0.141
-
11264.0 11264.0 0.0 0.0 11776.0 0.0 68608.0 390.0 - - - - 16 0.084 9 0.066 0.149
-
11264.0 11264.0 0.0 0.0 11776.0 0.0 68608.0 390.0 - - - - 16 0.084 9 0.066 0.149
-
11264.0 11264.0 0.0 0.0 11776.0 258.1 68608.0 390.0 - - - - 16 0.084 9 0.066 0.149
-
11264.0 11264.0 0.0 0.0 11776.0 3012.8 68608.0 390.0 - - - - 16 0.084 9 0.066 0.149
jstat还可以以其他角度监视各区内存大小、监视类装载信息等,具体可以google jstat的详细用法。
③用jmap(Memory Map for Java)查看堆内存信息
执行jmap -histo pid可以打印出当前堆中所有每个类的实例数量和内存占用,如下,class name是每个类的类名([B是byte类型,[C是char类型,[I是int类型),bytes是这个类的所有示例占用内存大小,instances是这个类的实例数量:
-
num #instances #bytes class name
-
----------------------------------------------
-
1: 2291 29274080 [B
-
2: 15252 1961040 <methodKlass>
-
3: 15252 1871400 <constMethodKlass>
-
4: 18038 721520 java.util.TreeMap$Entry
-
5: 6182 530088 [C
-
6: 11391 273384 java.lang.Long
-
7: 5576 267648 java.util.TreeMap
-
8: 50 155872 [I
-
9: 6124 146976 java.lang.String
-
10: 3330 133200 java.util.LinkedHashMap$Entry
-
11: 5544 133056 javax.management.openmbean.CompositeDataSupport
执行 jmap -dump 可以转储堆内存快照到指定文件,比如执行 jmap -dump:format=b,file=/data/jvm/dumpfile_jmap.hprof 3361 可以把当前堆内存的快照转储到dumpfile_jmap.hprof文件中,然后可以对内存快照进行分析。
④利用jconsole、jvisualvm分析内存信息(各个区如Eden、Survivor、Old等内存变化情况),如果查看的是远程服务器的JVM,程序启动需要加上如下参数:
-
"-Dcom.sun.management.jmxremote=true"
-
"-Djava.rmi.server.hostname=12.34.56.78"
-
"-Dcom.sun.management.jmxremote.port=18181"
-
"-Dcom.sun.management.jmxremote.authenticate=false"
-
"-Dcom.sun.management.jmxremote.ssl=false"
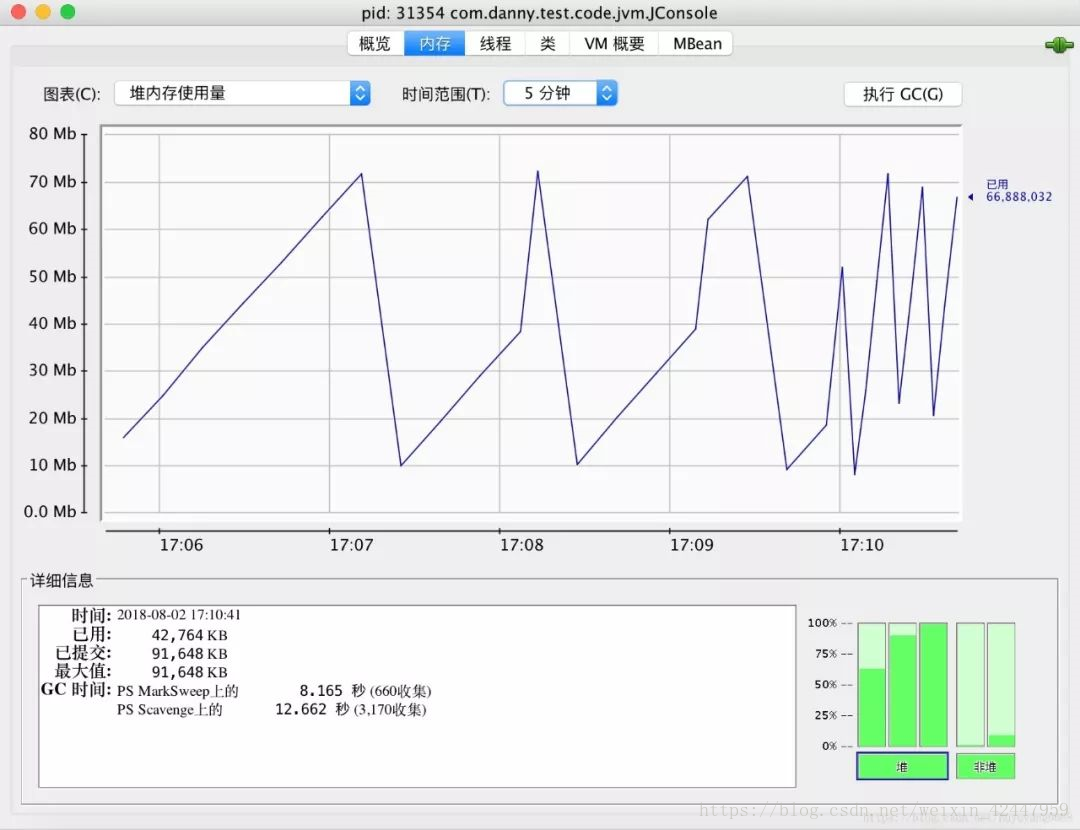
下图是jconsole界面,概览选项可以观测堆内存使用量、线程数、类加载数和CPU占用率;内存选项可以查看堆中各个区域的内存使用量和左下角的详细描述(内存大小、GC情况等);线程选项可以查看当前JVM加载的线程,查看每个线程的堆栈信息,还可以检测死锁;VM概要描述了虚拟机的各种详细参数。(jconsole功能演示)
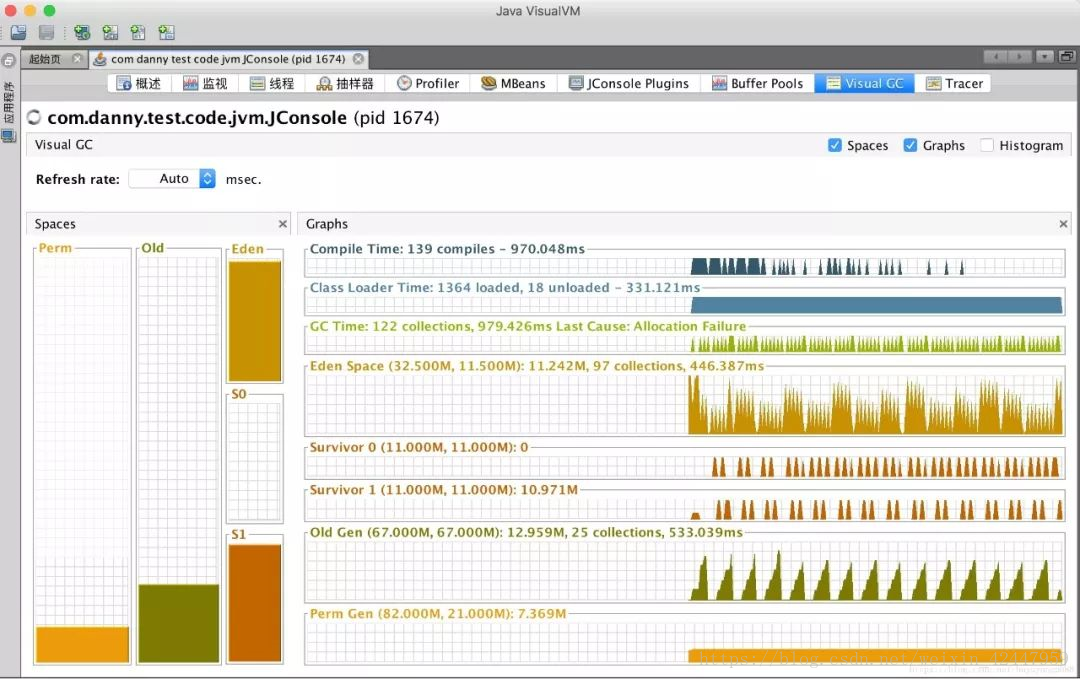
下图是jvisualvm的界面,功能比jconsole略丰富一些,不过大部分功能都需要安装插件。概述跟jconsole的VM概要差不多,描述的是jvm的详细参数和程序启动参数;监视展示的和jconsole的概览界面差不多(CPU、堆/方法区、类加载、线程);线程和jconsole的线程界面差不多;抽样器可以展示当前占用内存的类的排行榜及其实例的个数;Visual GC可以更丰富地展示当前各个区域的内存占用大小及历史信息(下图)。(jvisualvm功能演示)
⑤分析堆转储快照
前面说到配置了 “-XX:+HeapDumpOnOutOfMemory” 参数可以在程序发生内存溢出时dump出当前的内存快照,也可以用jmap命令随时dump出当时内存状态的快照信息,dump的内存快照一般是以.hprof为后缀的二进制格式文件。
可以直接用 jhat(JVM Heap Analysis Tool) 命令来分析内存快照,它的本质实际上内嵌了一个微型的服务器,可以通过浏览器来分析对应的内存快照,比如执行 jhat -port 9810 -J-Xmx4G /data/jvm/dumpfile_jmap.hprof 表示以9810端口启动 jhat 内嵌的服务器:
-
Reading from /Users/dannyhoo/data/jvm/dumpfile_jmap.hprof...
-
Dump file created Fri Aug 03 15:48:27 CST 2018
-
Snapshot read, resolving...
-
Resolving 276472 objects...
-
Chasing references, expect 55 dots.......................................................
-
Eliminating duplicate references.......................................................
-
Snapshot resolved.
-
Started HTTP server on port 9810
-
Server is ready.
在控制台可以看到服务器启动了,访问 http://127.0.0.1:9810/ 可以看到对快照中的每个类进行分析的结果(界面略low),下图是我随便选择了一个类的信息,有这个类的父类,加载这个类的类加载器和占用的空间大小,下面还有这个类的每个实例(References)及其内存地址和大小,点进去会显示这个实例的一些成员变量等信息:

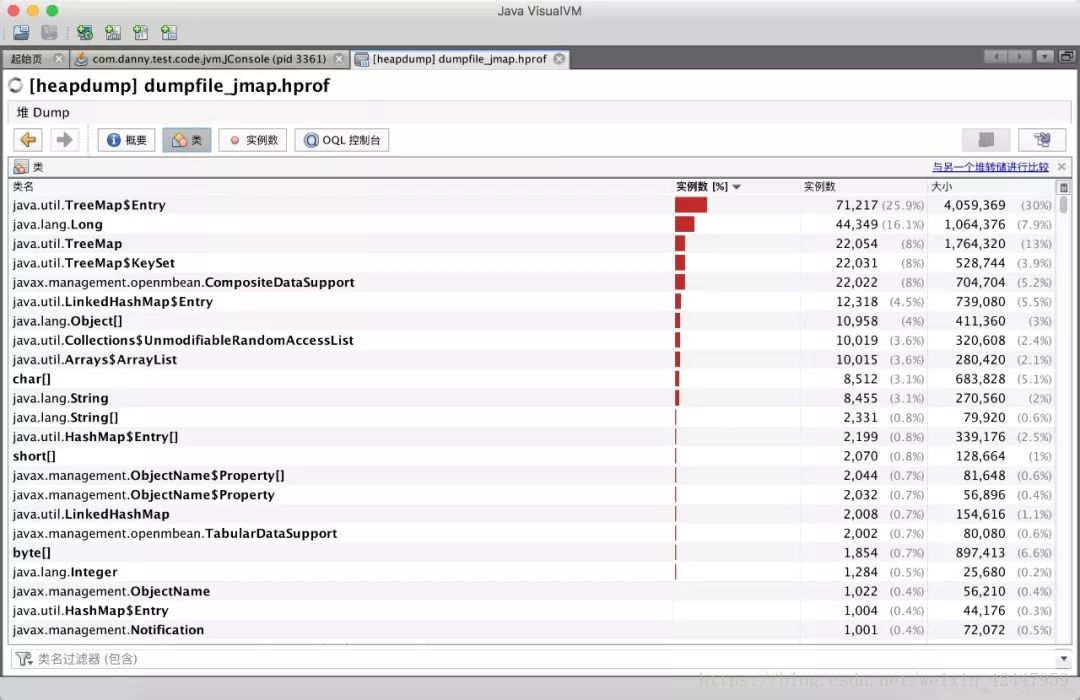
jvisualvm也可以分析内存快照,在jvisualvm菜单的“文件”-“装入”,选择堆内存快照,快照中的信息就以图形界面展示出来了,如下,主要可以查看每个类占用的空间、实例的数量和实例的详情等:
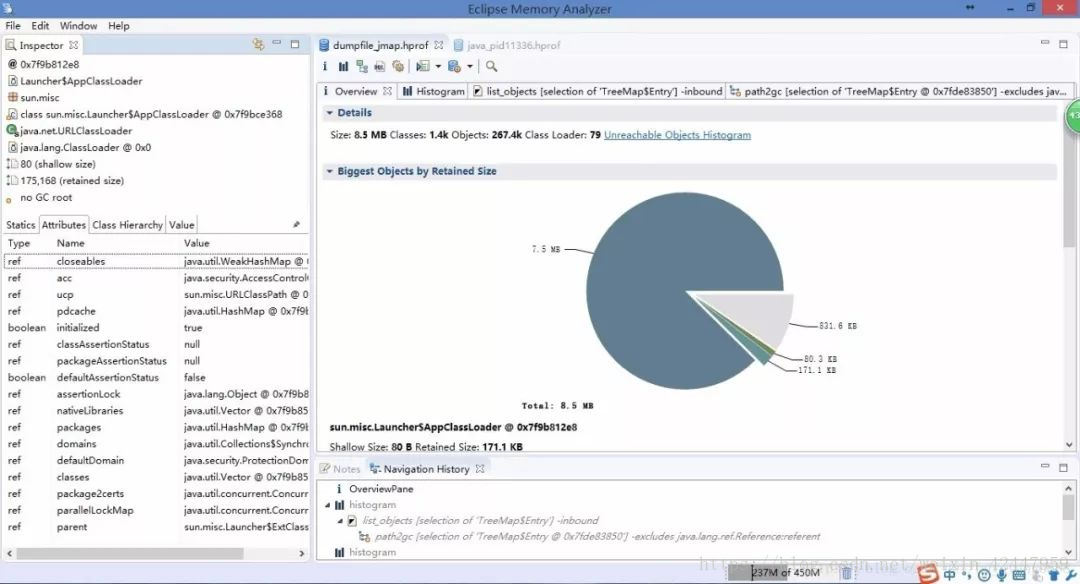
还有很多分析内存快照的第三方工具,比如eclipse mat,它比jvisualvm功能更专业,出了查看每个类及对应实例占用的空间、数量,还可以查询对象之间的调用链,可以查看某个实例到GC Root之间的链,等等。可以在eclipse中安装mat插件,也可以下载独立的版本(http://www.eclipse.org/mat/downloads.php ),我在mac上安装后运行起来老卡死~下面是在windows上的截图(MAT功能演示):
(3)JVM调优经验
JVM配置方面,一般情况可以先用默认配置(基本的一些初始参数可以保证一般的应用跑的比较稳定了),在测试中根据系统运行状况(会话并发情况、会话时间等),结合gc日志、内存监控、使用的垃圾收集器等进行合理的调整,当老年代内存过小时可能引起频繁Full GC,当内存过大时Full GC时间会特别长。
那么JVM的配置比如新生代、老年代应该配置多大最合适呢?答案是不一定,调优就是找答案的过程,物理内存一定的情况下,新生代设置越大,老年代就越小,Full GC频率就越高,但Full GC时间越短;相反新生代设置越小,老年代就越大,Full GC频率就越低,但每次Full GC消耗的时间越大。建议如下:
-
-Xms和-Xmx的值设置成相等,堆大小默认为-Xms指定的大小,默认空闲堆内存小于40%时,JVM会扩大堆到-Xmx指定的大小;空闲堆内存大于70%时,JVM会减小堆到-Xms指定的大小。如果在Full GC后满足不了内存需求会动态调整,这个阶段比较耗费资源。
-
新生代尽量设置大一些,让对象在新生代多存活一段时间,每次Minor GC 都要尽可能多的收集垃圾对象,防止或延迟对象进入老年代的机会,以减少应用程序发生Full GC的频率。
-
老年代如果使用CMS收集器,新生代可以不用太大,因为CMS的并行收集速度也很快,收集过程比较耗时的并发标记和并发清除阶段都可以与用户线程并发执行。
-
方法区大小的设置,1.6之前的需要考虑系统运行时动态增加的常量、静态变量等,1.7只要差不多能装下启动时和后期动态加载的类信息就行。
代码实现方面,性能出现问题比如程序等待、内存泄漏除了JVM配置可能存在问题,代码实现上也有很大关系:
-
避免创建过大的对象及数组:过大的对象或数组在新生代没有足够空间容纳时会直接进入老年代,如果是短命的大对象,会提前出发Full GC。
-
避免同时加载大量数据,如一次从数据库中取出大量数据,或者一次从Excel中读取大量记录,可以分批读取,用完尽快清空引用。
-
当集合中有对象的引用,这些对象使用完之后要尽快把集合中的引用清空,这些无用对象尽快回收避免进入老年代。
-
可以在合适的场景(如实现缓存)采用软引用、弱引用,比如用软引用来为ObjectA分配实例:SoftReference objectA=new SoftReference(); 在发生内存溢出前,会将objectA列入回收范围进行二次回收,如果这次回收还没有足够内存,才会抛出内存溢出的异常。
避免产生死循环,产生死循环后,循环体内可能重复产生大量实例,导致内存空间被迅速占满。 -
尽量避免长时间等待外部资源(数据库、网络、设备资源等)的情况,缩小对象的生命周期,避免进入老年代,如果不能及时返回结果可以适当采用异步处理的方式等。
(4)JVM问题排查记录案例
JVM服务问题排查 https://blog.csdn.net/jacin1/article/details/44837595
次让人难以忘怀的排查频繁Full GC过程 http://caogen81.iteye.com/blog/1513345
线上FullGC频繁的排查 https://blog.csdn.net/wilsonpeng3/article/details/70064336/
【JVM】线上应用故障排查 https://www.cnblogs.com/Dhouse/p/7839810.html
一次JVM中FullGC问题排查过程 http://iamzhongyong.iteye.com/blog/1830265
JVM内存溢出导致的CPU过高问题排查案例 https://blog.csdn.net/nielinqi520/article/details/78455614
一个java内存泄漏的排查案例 https://blog.csdn.net/aasgis6u/article/details/54928744
(5)常用JVM参数参考:
| 参数 | 说明 | 实例 |
|---|---|---|
| -Xms | 初始堆大小,默认物理内存的1/64 | -Xms512M |
| -Xmx | 最大堆大小,默认物理内存的1/4 | -Xms2G |
| -Xmn | 新生代内存大小,官方推荐为整个堆的3/8 | -Xmn512M |
| -Xss | 线程堆栈大小,jdk1.5及之后默认1M,之前默认256k | -Xss512k |
| -XX:NewRatio=n | 设置新生代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 | -XX:NewRatio=3 |
| -XX:SurvivorRatio=n | 年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:8,表示Eden:Survivor=8:1:1,一个Survivor区占整个年轻代的1/8 | -XX:SurvivorRatio=8 |
| -XX:PermSize=n | 永久代初始值,默认为物理内存的1/64 | -XX:PermSize=128M |
| -XX:MaxPermSize=n | 永久代最大值,默认为物理内存的1/4 | -XX:MaxPermSize=256M |
| -verbose:class | 在控制台打印类加载信息 | |
| -verbose:gc | 在控制台打印垃圾回收日志 | |
| -XX:+PrintGC | 打印GC日志,内容简单 | |
| -XX:+PrintGCDetails | 打印GC日志,内容详细 | |
| -XX:+PrintGCDateStamps | 在GC日志中添加时间戳 | |
| -Xloggc:filename | 指定gc日志路径 | -Xloggc:/data/jvm/gc.log |
| -XX:+UseSerialGC | 年轻代设置串行收集器Serial | |
| -XX:+UseParallelGC | 年轻代设置并行收集器Parallel Scavenge | |
| -XX:ParallelGCThreads=n | 设置Parallel Scavenge收集时使用的CPU数。并行收集线程数。 | -XX:ParallelGCThreads=4 |
| -XX:MaxGCPauseMillis=n | 设置Parallel Scavenge回收的最大时间(毫秒) | -XX:MaxGCPauseMillis=100 |
| -XX:GCTimeRatio=n | 设置Parallel Scavenge垃圾回收时间占程序运行时间的百分比。公式为1/(1+n) | -XX:GCTimeRatio=19 |
| -XX:+UseParallelOldGC | 设置老年代为并行收集器ParallelOld收集器 | |
| -XX:+UseConcMarkSweepGC | 设置老年代并发收集器CMS | |
| -XX:+CMSIncrementalMode | 设置CMS收集器为增量模式,适用于单CPU情况。 |