参考:
https://blog.csdn.net/nielinqi520/article/details/78455614
https://www.cnblogs.com/Dhouse/p/7839810.html
https://blog.csdn.net/aasgis6u/article/details/54928744
https://www.iteye.com/blog/iamzhongyong-1830265
https://www.iteye.com/blog/caogen81-1513345
https://blog.csdn.net/wilsonpeng3/article/details/70064336/
https://blog.csdn.net/jacin1/article/details/44837595
JVM内存溢出导致的CPU过高问题排查案例
问题背景:
近期针对某接口做压力测试的过程中发现,某接口在用户量3千左右,并且业务没有对外开放,CPU一直居高不下。
分析:初步怀疑开发人员逻辑控制不严谨, 导致死循环,因为业务量不大,用户量不大,不可能出现高并发。
1.通过jstack查找出对应执行线程是Vm Thread 线程,初步怀疑是频繁的GC导致cpu过高。
2.查看堆栈信息 jmap -heap 16190,如下图:
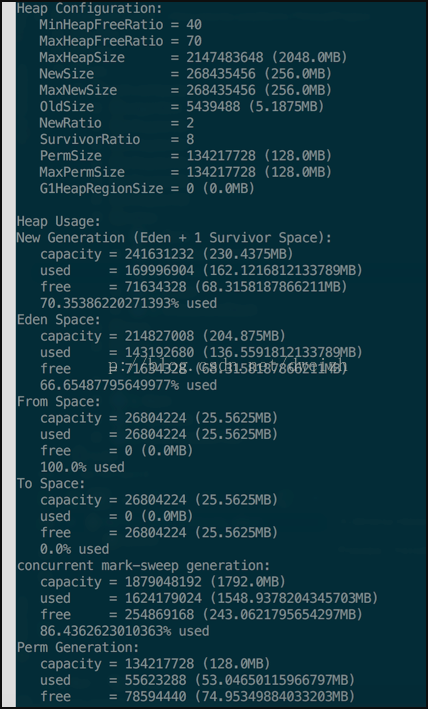
看到年老区已使用86%
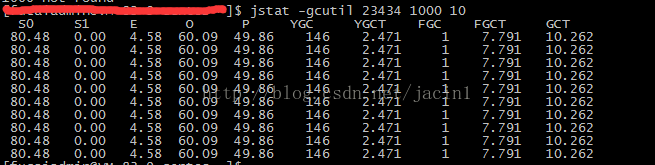
3.查看垃圾回收频率,再次确认:jstat -gcutil 16190 1000

FGC频率非常高,基本确定就是GC回收频繁,导致CPU过高。
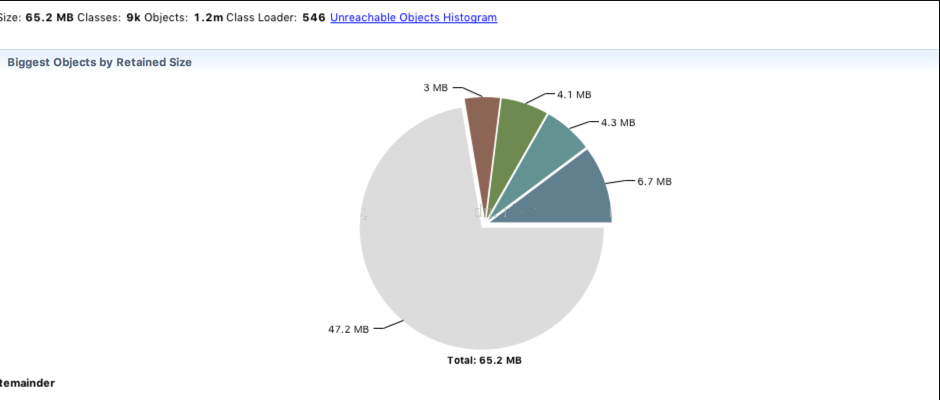
4.确认问题代码,执行jmap -dump:format=b,file=heap.bin 16190,生成堆栈文件,通过MAT进行分析,如下图:

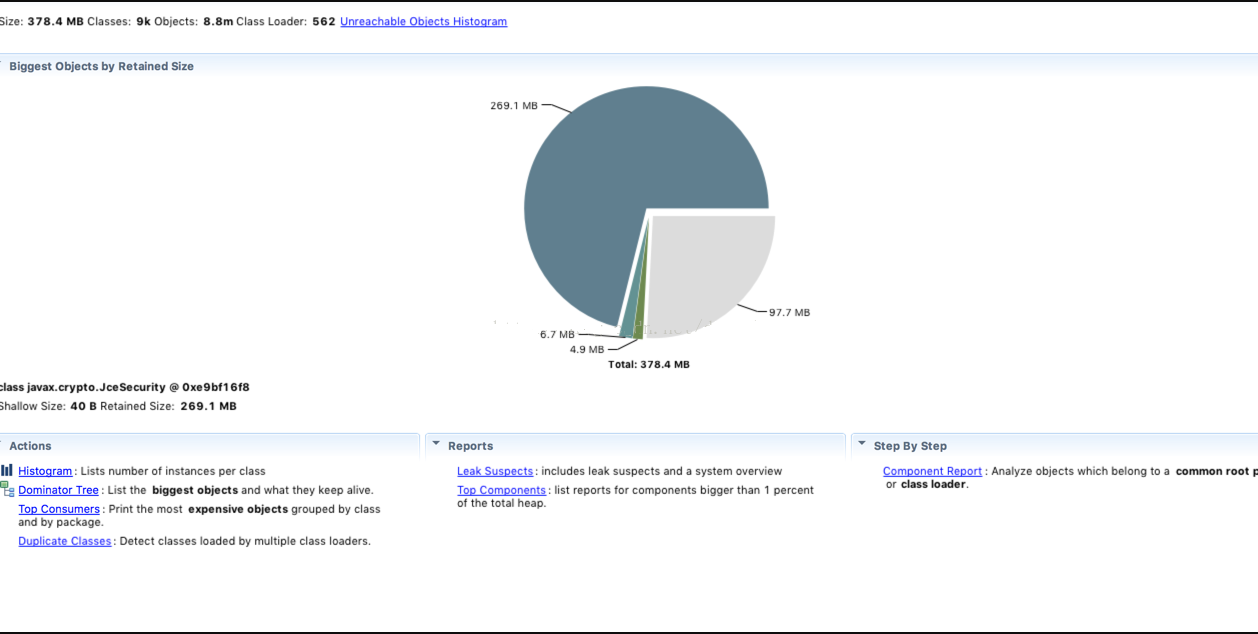
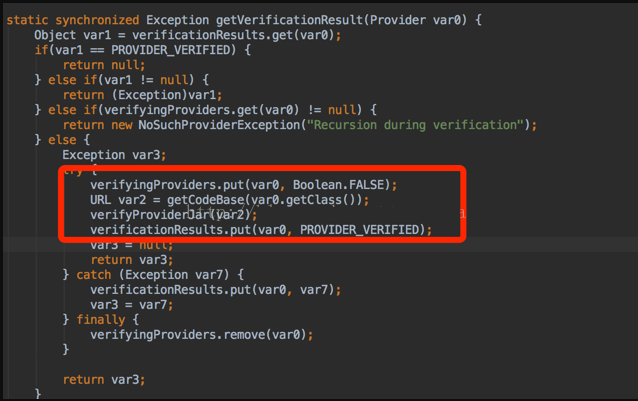
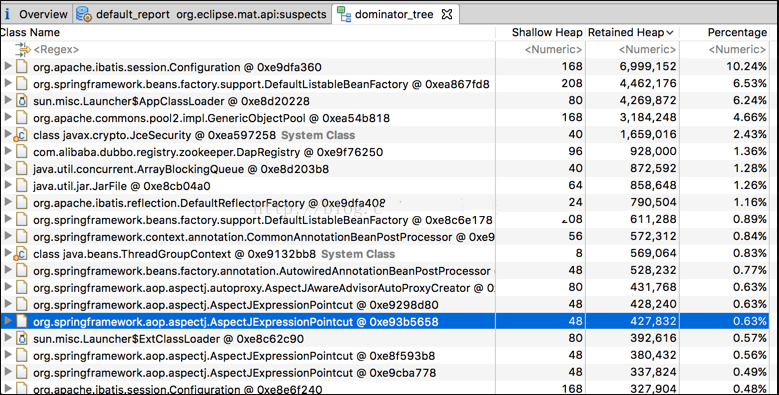
通过层层定位和分析,得出JceSecurity这个类就占用大部分内存,点击Dominator Tree进行分析,如下图:
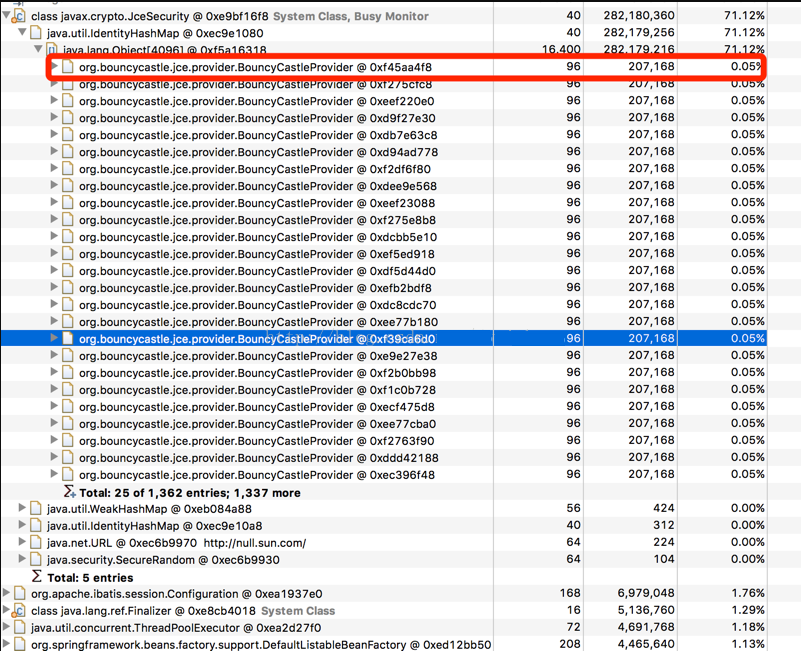
由于IdentityHashMap存放过多BouncyCastleProvider这个类,占用了大部分内存,查看JceSecurity中的IdentityHashMap,如下图:
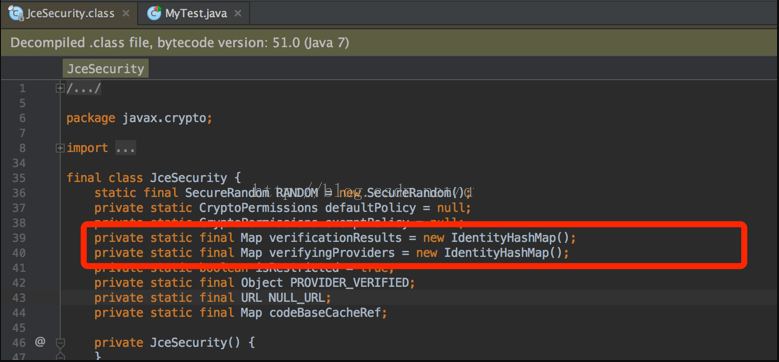
现在已经确定是由于map是static修饰导致,导致存放的类不能被jvm回收导致
5、查找程序中使用BouncyCastleProvider的代码,跟开发人员确认是解密类,如下图:

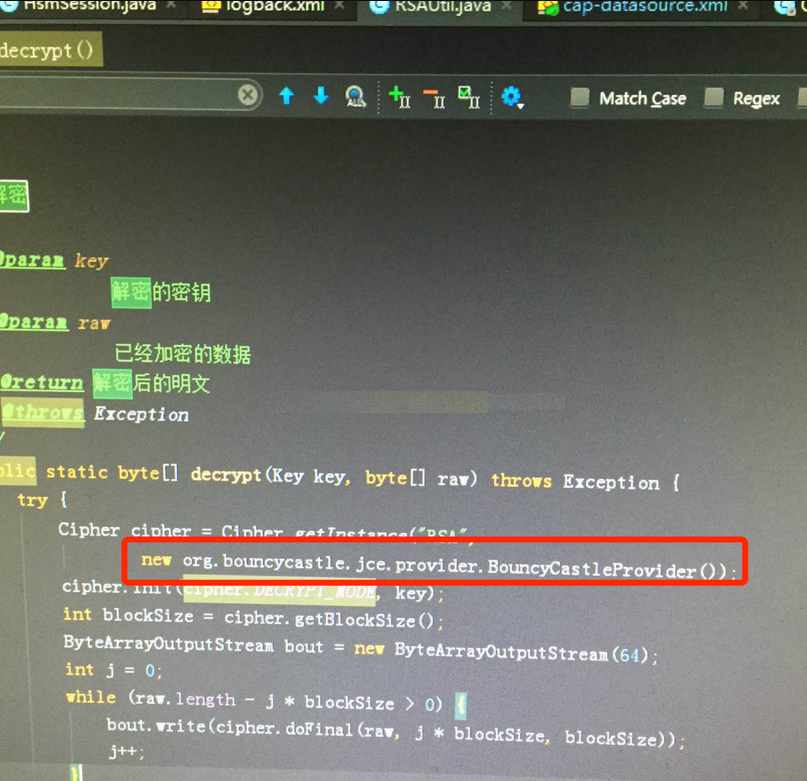

6、修改RSAUtil类中BouncyCastleProvider为单例,在此进行压测观察,如下图:
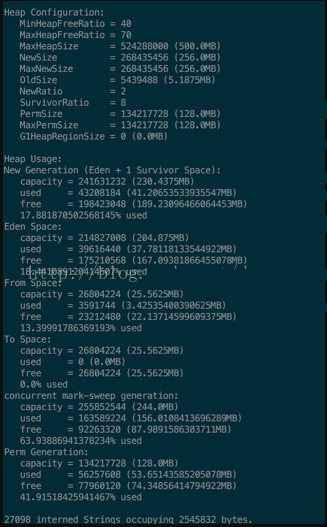
压测进行2小时,GC回收频率如下图:
内存使用情况:
至此,问题已经解决
线上应用故障排查
高CPU占用
一个应用占用CPU很高,除了确实是计算密集型应用之外,通常原因都是出现了死循环。

根据top命令,发现PID为28555的Java进程占用CPU高达200%,出现故障。
通过ps aux | grep PID命令,可以进一步确定是tomcat进程出现了问题。但是,怎么定位到具体线程或者代码呢?
首先显示线程列表:
ps -mp pid -o THREAD,tid,time

找到了耗时最高的线程28802,占用CPU时间快两个小时了!
其次将需要的线程ID转换为16进制格式:
printf "%x " tid

最后打印线程的堆栈信息:
jstack pid |grep tid -A 30

找到出现问题的代码了!
最后,总结下排查CPU故障的方法和技巧有哪些:
1、top命令:Linux命令。可以查看实时的CPU使用情况。也可以查看最近一段时间的CPU使用情况。
2、PS命令:Linux命令。强大的进程状态监控命令。可以查看进程以及进程中线程的当前CPU使用情况。属于当前状态的采样数据。
3、jstack:Java提供的命令。可以查看某个进程的当前线程栈运行情况。根据这个命令的输出可以定位某个进程的所有线程的当前运行状态、运行代码,以及是否死锁等等。
4、pstack:Linux命令。可以查看某个进程的当前线程栈运行情况。
高内存占用
搞Java开发的,经常会碰到下面两种异常:
1、java.lang.OutOfMemoryError: PermGen space
2、java.lang.OutOfMemoryError: Java heap space
要详细解释这两种异常,需要简单重提下Java内存模型。
Java内存模型是描述Java程序中各变量(实例域、静态域和数组元素)之间的关系,以及在实际计算机系统中将变量存储到内存和从内存取出变量这样的低层细节。
在Java虚拟机中,内存分为三个代:新生代(New)、老生代(Old)、永久代(Perm)。
(1)新生代New:新建的对象都存放这里
(2)老生代Old:存放从新生代New中迁移过来的生命周期较久的对象。新生代New和老生代Old共同组成了堆内存。
(3)永久代Perm:是非堆内存的组成部分。主要存放加载的Class类级对象如class本身,method,field等等。
如果出现java.lang.OutOfMemoryError: Java heap space异常,说明Java虚拟机的堆内存不够。原因有二:
(1)Java虚拟机的堆内存设置不够,可以通过参数-Xms、-Xmx来调整。
(2)代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)。
如果出现java.lang.OutOfMemoryError: PermGen space,说明是Java虚拟机对永久代Perm内存设置不够。
一般出现这种情况,都是程序启动需要加载大量的第三方jar包。例如:在一个Tomcat下部署了太多的应用。
从代码的角度,软件开发人员主要关注java.lang.OutOfMemoryError: Java heap space异常,减少不必要的对象创建,同时避免内存泄漏。
现在以一个实际的例子分析内存占用的故障排查。

通过top命令,发现PID为9004的Java进程一直占用比较高的内存不释放(24.7%),出现高内存占用的故障。
想起上一篇线上应用故障排查之一:高CPU占用介绍的PS命令,能否找到具体是哪个的线程呢?
ps -mp 9004 -o THREAD,tid,time,rss,size,%mem

遗憾的是,发现PS命令可以查到具体进程的CPU占用情况,但是不能查到一个进程下具体线程的内存占用情况。
只好寻求其他方法了,幸好Java提供了一个很好的内存监控工具:jmap命令
jmap命令有下面几种常用的用法:
•jmap [pid]
•jmap -histo:live [pid] >a.log
•jmap -dump:live,format=b,file=xxx.xxx [pid]
用得最多是后面两个。其中,jmap -histo:live [pid] 可以查看当前Java进程创建的活跃对象数目和占用内存大小。
jmap -dump:live,format=b,file=xxx.xxx [pid] 则可以将当前Java进程的内存占用情况导出来,方便用专门的内存分析工具(例如:MAT)来分析。
这个命令对于分析是否有内存泄漏很有帮助。具体怎么使用可以查看本博的另一篇文章:利用Eclipse Memory Analyzer Tool(MAT)分析内存泄漏
这里详细介绍下jmap -histo:live [pid] 命令:

从上图可以看出,int数组、constMethodKlass、methodKlass、constantPoolKlass都占用了大量的内存。
特别是占用了大量内存的int数组,需要仔细检查相关代码。
最后,总结下排查内存故障的方法和技巧有哪些:
1、top命令:Linux命令。可以查看实时的内存使用情况。
2、jmap -histo:live [pid],然后分析具体的对象数目和占用内存大小,从而定位代码。
3、jmap -dump:live,format=b,file=xxx.xxx [pid],然后利用MAT工具分析是否存在内存泄漏等等。
一个java内存泄漏的排查案例
这是个比较典型的java内存使用问题,定位过程也比较直接,但对新人还是有点参考价值的,所以就纪录了一下。
下面介绍一下在不了解系统代码的情况下,如何一步步分析和定位到具体代码的排查过程
(以便新人参考和自己回顾)
初步的现象
业务系统消费MQ中消息速度变慢,积压了200多万条消息,通过jstat观察到业务系统fullgc比较频繁,到最后干脆OOM了: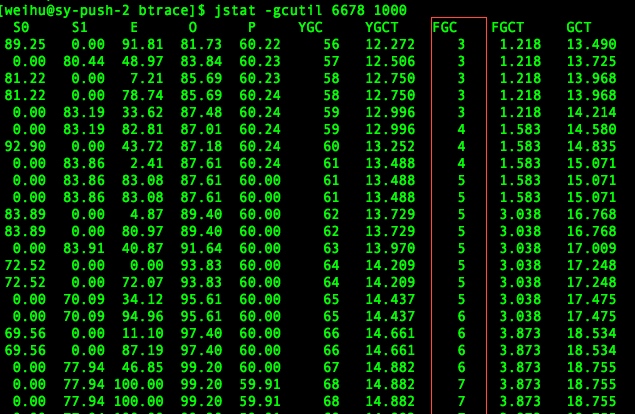 

进一步分析
既然知道了内存使用存在问题,那么就要知道是哪些对象占用了大量内存.
很多人都会想到把堆dump下来再用MAT等工具进行分析,但dump堆要花较长的时间,并且文件巨大,再从服务器上拖回本地导入工具,这个过程太折腾不到万不得已最好别这么干。
可以用更轻量级的在线分析,用jmap查看存活的对象情况(jmap -histo:live [pid]),可以看出HashTable中的元素有5000多万,占用内存大约1.5G的样子: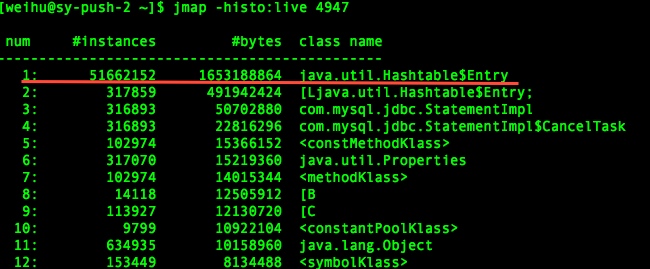 

定位到代码
现在已经知道了是HashTable的问题,那么就要定位出什么代码引起的
接下来自然要看看是什么代码往HashTable里疯狂的put数据,于是用神器btrace跟踪Hashtable.put调用的堆栈。
首先写btrace脚本TracingHashTable.java:
-
import com.sun.btrace.annotations.*;
-
import static com.sun.btrace.BTraceUtils.*;
-
-
@BTrace
-
public class TracingHashTable {
-
/*指明要查看的方法,类*/
-
@OnMethod(
-
clazz="java.util.Hashtable",
-
method="put",
-
location=@Location(Kind.RETURN))
-
public static void traceExecute(@Self java.util.Hashtable object){
-
println("调用堆栈!!");
-
jstack();
-
}
-
}
然后运行:
bin/btrace -cp build 4947 TracingHashTable.java
看到有大量类似下图的调用堆栈 

可以看出是在接收到消息后查询入库的代码造成的,业务方法调用ibatis再到mysql jdbc驱动执行statement时put了大量的属性到HashTable中。
通过以上排查已基本定位了由那块代码引起的,接下来就是打开代码工程进行白盒化改造了,对相应代码进行优化(不在本文范围内了。几个图中的pid不一致就别纠结了,有些是系统重启过再截图的).
一次JVM中FullGC问题排查过程
这个问题比较常见,我把过程中的日志记录下来了,希望后续大家遇到类似的能快速定位。
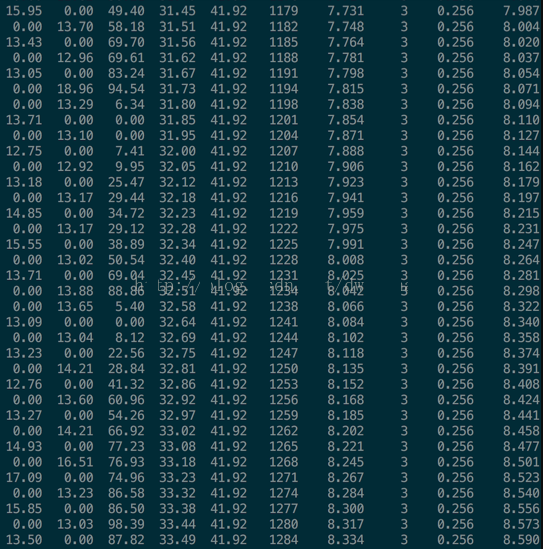
1、平均三秒一次FullFC
sudo -u admin java/bin/jstat -gcutil `pgrep java -u admin` 1000 2000
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 0.53 71.69 9.19 92.42 6183 901.265 54986 48865.327 49766.592
0.00 0.53 72.34 9.19 92.42 6183 901.265 54986 48866.617 49767.881
0.00 0.53 72.68 9.19 92.42 6183 901.265 54986 48866.617 49767.881
0.00 0.53 73.08 9.19 92.42 6183 901.265 54987 48866.617 49767.881
0.00 0.53 73.08 9.19 92.42 6183 901.265 54987 48866.617 49767.881
0.00 0.53 73.68 9.19 92.42 6183 901.265 54987 48867.875 49769.140
0.00 0.53 73.87 9.19 92.42 6183 901.265 54988 48867.875 49769.140
0.00 0.53 73.87 9.19 92.42 6183 901.265 54988 48869.260 49770.525
0.00 0.53 74.90 9.19 92.42 6183 901.265 54988 48869.260 49770.525
0.00 0.53 75.32 9.19 92.42 6183 901.265 54988 48869.260 49770.525
0.00 0.53 75.39 9.19 92.42 6183 901.265 54989 48869.260 49770.525
0.00 0.53 76.07 9.19 92.42 6183 901.265 54989 48870.539 49771.804
0.00 0.53 76.34 9.19 92.42 6183 901.265 54990 48870.539 49771.804
0.00 0.53 76.34 9.19 92.42 6183 901.265 54990 48870.539 49771.804
0.00 0.53 77.36 9.19 92.42 6183 901.265 54990 48871.973 49773.238
0.00 0.53 77.65 9.19 92.42 6183 901.265 54990 48871.973 49773.238
0.00 0.53 77.76 9.19 92.42 6183 901.265 54991 48871.973 49773.238
2、重启应用之后发现Perm区一直在上涨
sudo -u admin /java/bin/jstat -gcutil `pgrep java -u admin` 5000 200
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 71.04 14.28 0.00 71.46 5 0.467 0 0.000 0.467
0.00 71.04 16.19 0.00 71.47 5 0.467 0 0.000 0.467
0.00 71.04 18.30 0.00 71.54 5 0.467 0 0.000 0.467
0.00 71.04 20.82 0.00 71.54 5 0.467 0 0.000 0.467
0.00 71.04 22.77 0.00 71.54 5 0.467 0 0.000 0.467
0.00 71.04 24.46 0.00 71.54 5 0.467 0 0.000 0.467
0.00 71.04 26.24 0.00 71.54 5 0.467 0 0.000 0.467
0.00 71.04 29.01 0.00 72.66 5 0.467 0 0.000 0.467
0.00 71.04 30.84 0.00 72.66 5 0.467 0 0.000 0.467
0.00 71.04 32.65 0.00 72.68 5 0.467 0 0.000 0.467
0.00 71.04 34.48 0.00 72.68 5 0.467 0 0.000 0.467
0.00 71.04 36.40 0.00 72.69 5 0.467 0 0.000 0.467
0.00 71.04 38.10 0.00 72.69 5 0.467 0 0.000 0.467
0.00 71.04 39.76 0.00 72.70 5 0.467 0 0.000 0.467
3、Btrace查看后发现HSF的一个类在调用ClassLoader的defineClass方法来创建类:
sudo -u admin sh btrace -cp /home/admin/btrace/build 4955 /home/admin/btrace/BtraceAll.java
===========================================================================
java.lang.ClassLoader.defineClass
Time taken : 2
java thread method trace:---------------------------------------------------
java.lang.ClassLoader.defineClass(ClassLoader.java:615)
org.eclipse.osgi.internal.baseadaptor.DefaultClassLoader.defineClass(DefaultClassLoader.java:165)
org.eclipse.osgi.baseadaptor.loader.ClasspathManager.defineClass(ClasspathManager.java:554)
org.eclipse.osgi.baseadaptor.loader.ClasspathManager.findClassImpl(ClasspathManager.java:524)
org.eclipse.osgi.baseadaptor.loader.ClasspathManager.findLocalClassImpl(ClasspathManager.java:455)
org.eclipse.osgi.baseadaptor.loader.ClasspathManager.findLocalClass_LockClassLoader(ClasspathManager.java:443)
org.eclipse.osgi.baseadaptor.loader.ClasspathManager.findLocalClass(ClasspathManager.java:423)
org.eclipse.osgi.internal.baseadaptor.DefaultClassLoader.findLocalClass(DefaultClassLoader.java:193)
org.eclipse.osgi.framework.internal.core.BundleLoader.findLocalClass(BundleLoader.java:368)
org.eclipse.osgi.framework.internal.core.SingleSourcePackage.loadClass(SingleSourcePackage.java:33)
org.eclipse.osgi.framework.internal.core.BundleLoader.findClassInternal(BundleLoader.java:432)
org.eclipse.osgi.framework.internal.core.BundleLoader.findClass(BundleLoader.java:397)
org.eclipse.osgi.framework.internal.core.BundleLoader.findClass(BundleLoader.java:385)
org.eclipse.osgi.internal.baseadaptor.DefaultClassLoader.loadClass(DefaultClassLoader.java:87)
java.lang.ClassLoader.loadClass(ClassLoader.java:247)
com.taobao.hsf.rpc.tbremoting.provider.ProviderProcessor.handleRequest(ProviderProcessor.java:117)
com.taobao.hsf.rpc.tbremoting.provider.ProviderProcessor.handleRequest(ProviderProcessor.java:55)
com.taobao.remoting.impl.DefaultMsgListener$1.run(DefaultMsgListener.java:98)
java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
java.lang.Thread.run(Thread.java:662)
4、Perm区配置都是128M,有点小,之前占比90%的时候开始FullGC
VM Flags:
-Dprogram.name=run.sh -Xms4g -Xmx4g -XX:PermSize=128m -XX:MaxPermSize=128m -Xmn2500m -XX:SurvivorRatio=7 -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection
5、应用中war包的lib目录就有177M
在应用刚开始启动的时候,占比70% 左右,也就是90M左右的样子,之后有些类动态加载进来了,到90% 后就回收不了了。
临时解决办法:调大Perm区,增大至256m
后续考虑:优化jar包依赖,目前太多没用的被依赖进来,导致包很大。
一次让人难以忘怀的排查频繁Full GC过程
我们的Java应用因频繁FULL GC导致性能降低很多,经过多人的定位也没有结论,于是我自主请命,经过一天的研究终于搞定了,现把经验与大家共享,相关的gc日志如下:
4.758: [Full GC [PSYoungGen: 464K->0K(71936K)] [PSOldGen: 37949K->33994K(68672K)] 38413K->33994K(140608K) [PSPermGen: 33221K->33221K(66560K)], 0.1887540 secs] [Times: user=0.20 sys=0.00, real=0.19 secs]
32.324: [Full GC [PSYoungGen: 12025K->0K(176320K)] [PSOldGen: 57570K->65642K(128256K)] 69595K->65642K(304576K) [PSPermGen: 35548K->35548K(76544K)], 0.2467320 secs] [Times: user=0.22 sys=0.02, real=0.25 secs]
50.133: [Full GC [PSYoungGen: 20999K->0K(437248K)] [PSOldGen: 118647K->114524K(198528K)] 139647K->114524K(635776K) [PSPermGen: 49637K->49637K(84224K)], 0.3302180 secs] [Times: user=0.32 sys=0.00, real=0.33 secs]
149.586: [Full GC [PSYoungGen: 44223K->0K(411712K)] [PSOldGen: 190278K->185382K(296064K)] 234501K->185382K(707776K) [PSPermGen: 50674K->50208K(85248K)], 0.6151800 secs] [Times: user=0.62 sys=0.00, real=0.61 secs]
260446.223: [Full GC [PSYoungGen: 31393K->0K(436032K)] [PSOldGen: 1006486K->396428K(1021312K)] 1037880K->396428K(1457344K) [PSPermGen: 61093K->61093K(61440K)], 1.3636610 secs] [Times: user=1.36 sys=0.00, real=1.52 secs]
260630.161: [Full GC (System) [PSYoungGen: 40410K->0K(424768K)] [PSOldGen: 991397K->721859K(1021312K)] 1031808K->721859K(1446080K) [PSPermGen: 61100K->61100K(61440K)], 2.1272130 secs] [Times: user=2.14 sys=0.00, real=2.13 secs]
260720.146: [Full GC (System) [PSYoungGen: 4949K->0K(439360K)] [PSOldGen: 1004066K->833610K(1021312K)] 1009015K->833610K(1460672K) [PSPermGen: 61108K->61108K(61440K)], 2.8408660 secs] [Times: user=2.72 sys=0.10, real=2.84 secs]
260810.150: [Full GC (System) [PSYoungGen: 33459K->0K(463552K)] [PSOldGen: 949989K->245655K(1021312K)] 983448K->245655K(1484864K) [PSPermGen: 61117K->61088K(61184K)], 1.1344010 secs] [Times: user=1.12 sys=0.02, real=1.14 secs]
03430.144: [Full GC (System) [PSYoungGen: 7390K->0K(489024K)] [PSOldGen: 871871K->393481K(976704K)] 879262K->393481K(1465728K) [PSPermGen: 64306K->64295K(64640K)], 1.3848850 secs] [Times: user=1.34 sys=0.06, real=1.38 secs]
403794.982: [Full GC [PSYoungGen: 9352K->0K(454144K)] [PSOldGen: 963758K->426051K(991744K)] 973110K->426051K(1445888K) [PSPermGen: 64298K->64298K(64640K)], 1.3783510 secs] [Times: user=1.32 sys=0.06, real=1.38 secs]
404120.149: [Full GC (System) [PSYoungGen: 6846K->0K(467648K)] [PSOldGen: 943642K->440168K(991744K)] 950489K->440168K(1459392K) [PSPermGen: 64300K->64300K(64640K)], 1.1605070 secs] [Times: user=1.12 sys=0.04, real=1.16 secs]
404466.698: [Full GC [PSYoungGen: 9719K->0K(472768K)] [PSOldGen: 980355K->442899K(1021312K)] 990074K->442899K(1494080K) [PSPermGen: 64303K->64303K(64640K)], 1.1729280 secs] [Times: user=1.14 sys=0.04, real=1.18 secs]
经过日志分析,我找到两个突破点,重点关注红色字体部分的日志,分析过程如下:
1)FULL GC前后Java堆大小有变化;经研究发现是由于Java应用JVM参数XMS设置为默认值,在我们的系统环境下,Hotspot的Xms默认值为50M(-Xms默认是物理内存的1/64);每次GC时,JVM会根据各种条件调节Java堆的大小,Java堆的取值范围为[Xms, Xmx]。根据以上分析,修改Xms值与Xmx相等,这样就不会因为所使用的Java堆不够用而进行调节,经过测试后发现FULL GC次数从四位数减少至个位数。
2)关键词“System”让我想到了System.gc调用,System.gc调用只是建议JVM执行年老代GC,而年老代GC触发FULL GC,JVM会根据系统条件决定是否执行FULL GC,正因为系统条件不好判断,所以很难构造System.gc调用触发FULL GC,几经周折终于成功,当System.gc触发FULL GC时都会有关键词“(System)”,而 JVM自动触发的FULL GC却不带关键词“(System)”,可以断定是Java应用存在“System.gc”代码。经过本次测试我也发现System.gc的真正含义,通俗言之,“System.gc” 就是FULL GC触发的最后一根稻草。
从本次分析中,我们可以得出如下的经验:
1)Java应用的jvm参数Xms与Xmx保持一致,避免因所使用的Java堆内存不够导致频繁full gc以及full gc中因动态调节Java堆大小而耗费延长其周期。
2)建议不要调用System.gc或者Runtime.getRuntime().gc,否则本次调用可能会成为“压死骆驼的最后一根稻草”。当然我们可以通过设置jvm参数禁止这种调用生效,但是除非特别有把握该参数有必要添加,否则不推荐这么设置。
线上FullGC频繁排查-druid
线上FullGC频繁的排查
本应该写在文末的
这个问题我再github上提交了一个issue,具体issue的讨论见这里
问题
前段时间发现线上的一个dubbo服务Full GC比较频繁,大约每两天就会执行一次Full GC。
Full GC的原因
我们知道Full GC的触发条件大致情况有以下几种情况:
- 程序执行了System.gc() //建议jvm执行fullgc,并不一定会执行
- 执行了jmap -histo:live pid命令 //这个会立即触发fullgc
- 在执行minor gc的时候进行的一系列检查
执行Minor GC的时候,JVM会检查老年代中最大连续可用空间是否大于了当前新生代所有对象的总大小。
如果大于,则直接执行Minor GC(这个时候执行是没有风险的)。
如果小于了,JVM会检查是否开启了空间分配担保机制,如果没有开启则直接改为执行Full GC。
如果开启了,则JVM会检查老年代中最大连续可用空间是否大于了历次晋升到老年代中的平均大小,如果小于则执行改为执行Full GC。
如果大于则会执行Minor GC,如果Minor GC执行失败则会执行Full GC
- 使用了大对象 //大对象会直接进入老年代
- 在程序中长期持有了对象的引用 //对象年龄达到指定阈值也会进入老年代
对于我们的情况,可以初步排除1,2两种情况,最有可能是4和5这两种情况。为了进一步排查原因,我们在线上开启了 -XX:+HeapDumpBeforeFullGC。
注意:
JVM在执行dump操作的时候是会发生stop the word事件的,也就是说此时所有的用户线程都会暂停运行。
为了在此期间也能对外正常提供服务,建议采用分布式部署,并采用合适的负载均衡算法
JVM参数的设置:
线上这个dubbo服务是分布式部署,在其中一台机子上开启了 -XX:HeapDumpBeforeFullGC,总体JVM参数如下:
-Xmx2g
-XX:+HeapDumpBeforeFullGC
-XX:HeapDumpPath=.
-Xloggc:gc.log
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100m
-XX:HeapDumpOnOutOfMemoryError
Dump文件分析
dump下来的文件大约1.8g,用jvisualvm查看,发现用char[]类型的数据占用了41%内存,同时另外一个com.alibaba.druid.stat.JdbcSqlStat类型的数据占用了35%的内存,也就是说整个堆中几乎全是这两类数据。如下图:

查看char[]类型数据,发现几乎全是sql语句。
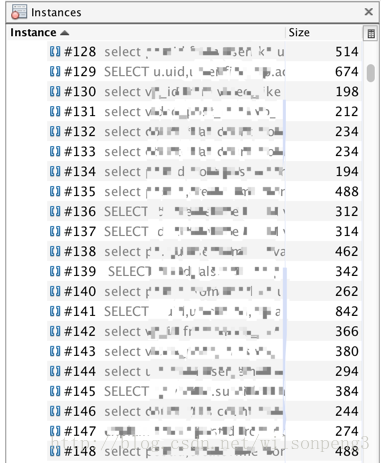
接下来查看char[]的引用情况:
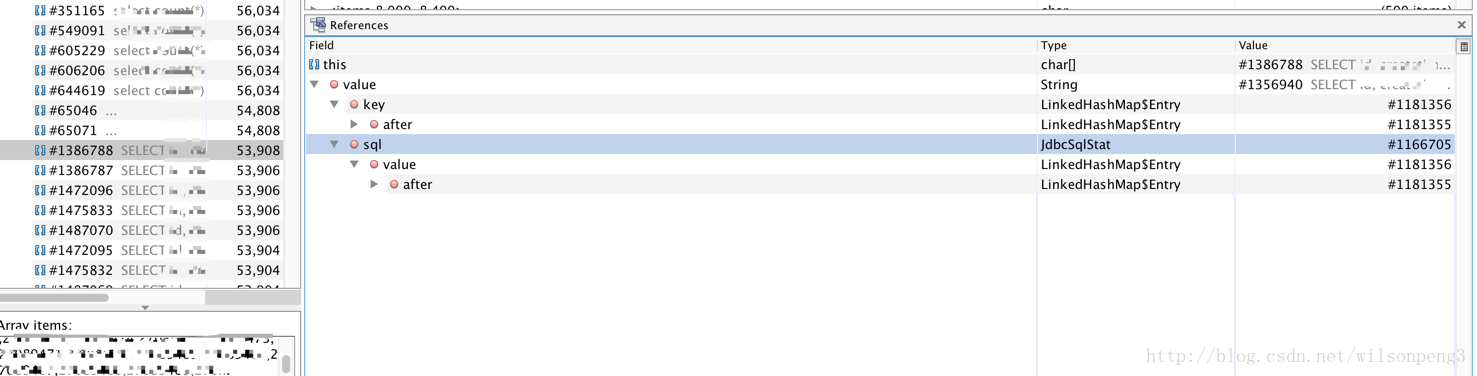
找到了JdbcSqlStat类,在代码中查看这个类的代码,关键代码如下:
//构造函数只有这一个
public JdbcSqlStat(String sql){
this.sql = sql;
this.id = DruidDriver.createSqlStatId();
}
//查看这个函数的调用情况,找到com.alibaba.druid.stat.JdbcDataSourceStat#createSqlStat方法:
public JdbcSqlStat createSqlStat(String sql) {
lock.writeLock().lock();
try {
JdbcSqlStat sqlStat = sqlStatMap.get(sql);
if (sqlStat == null) {
sqlStat = new JdbcSqlStat(sql);
sqlStat.setDbType(this.dbType);
sqlStat.setName(this.name);
sqlStatMap.put(sql, sqlStat);
}
return sqlStat;
} finally {
lock.writeLock().unlock();
}
}
//这里用了一个map来存放所有的sql语句。
其实到这里也就知道什么原因造成了这个问题,因为我们使用的数据源是阿里巴巴的druid,这个druid提供了一个sql语句监控功能,同时我们也开启了这个功能。只需要在配置文件中把这个功能关掉应该就能消除这个问题,事实也的确如此,关掉这个功能后到目前为止线上没再触发FullGC
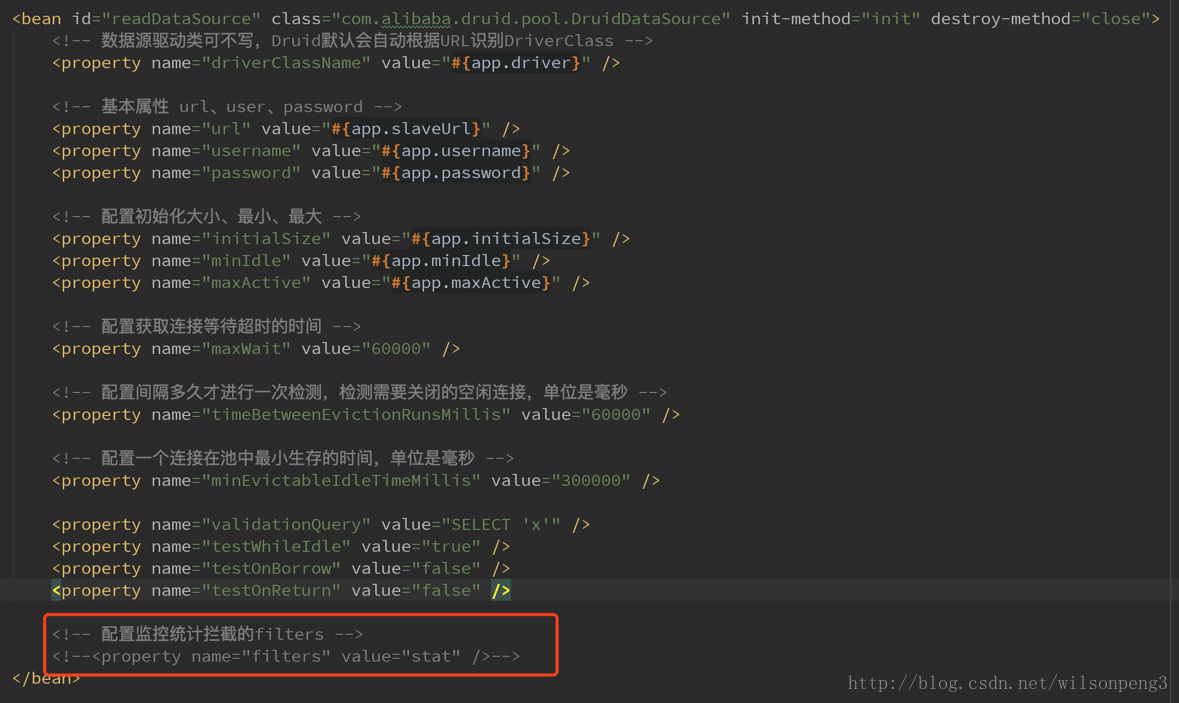
其他
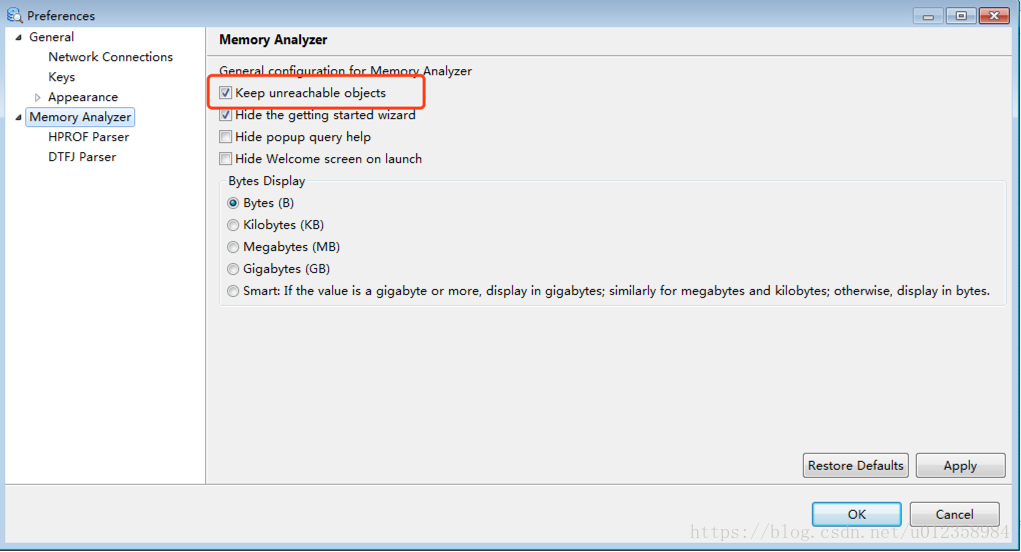
如果用mat工具查看,建议把 “Keep unreachable objects” 勾上,否则mat会把堆中不可达的对象去除掉,这样我们的分析也许会变得没有意义。如下图:Window–>References 。另外jvisualvm对ool的支持不是很好,如果需要oql建议使用mat。
扩展
本人自己建了一个jdk8和jdk7的源码阅读仓库,会在阅读源码的过程中添加一些注释。
感兴趣的朋友可以一起来添加对代码的理解。仓库地址:
jdk8:
github: https://github.com/rocky-peng/jdk8-sourcecode-read
gitlab: https://gitlab.com/rocky_peng/jdk8
jdk7:
github: https://github.com/rocky-peng/jdk7-sourcecode-read
gitlab: https://gitlab.com/rocky_peng/jdk7
github和gitlab是完全自动同步的。
jdk8和jdk7的源码来源于jdk8和jdk7的src.zip文件。 JVM服务问题排查
1. 宿主机器问题:
top -p ${pid}
#查看该进程关联线程情况
top -H -p ${pid} 2. JVM堆使用情况和GC问题:
jmap -heap ${pid}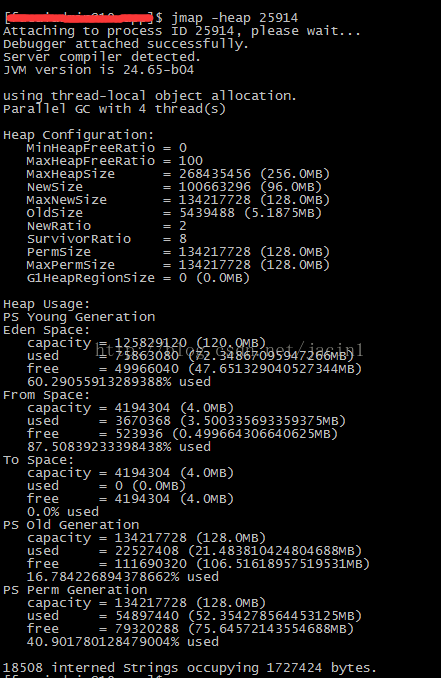
jmap -histo ${pid} 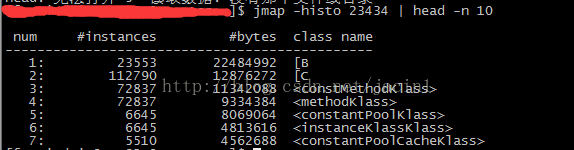
jmap -histo ${pid} | grep ${package} 
jstat -gcutil ${pid} 1000 10