同步一个表,可以参考我的上一篇 logstash-jdbc-input与mysql数据库同步
同步多个表的做法,跟一个表类似,唯一不同的是 .conf 文件中的配置
在这里我加了一个脚本文件jdbc-seckill.sql,是为了查询第二个表的数据(其实也可以不要此文件,而是直接将sql写在 .conf文件中)
SELECT seckill_id id, name, number, create_time
FROM seckill
WHERE number > :number
这里我增加了一个查询条件,传值的方式,可在下面的配置文件中看到有个parameters
接下来,我们直接看配置文件:
input { jdbc { jdbc_connection_string => "jdbc:mysql://dev.yonyouccs.com:3001/test" jdbc_user => "root" jdbc_password => "root" jdbc_driver_library => "D:/software/logstash-6.2.2/logstash-6.2.2/mysql/mysql-connector-java-5.1.40.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement_filepath => "D:/software/logstash-6.2.2/logstash-6.2.2/mysql/jdbc.sql" schedule => "* * * * *" type => "user" } jdbc { jdbc_connection_string => "jdbc:mysql://dev.yonyouccs.com:3001/test" jdbc_user => "root" jdbc_password => "root" jdbc_driver_library => "D:/software/logstash-6.2.2/logstash-6.2.2/mysql/mysql-connector-java-5.1.40.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_paging_enabled => "true" jdbc_page_size => "50000" parameters => {"number" => "200"} statement_filepath => "D:/software/logstash-6.2.2/logstash-6.2.2/mysql/jdbc-seckill.sql" schedule => "* * * * *" type => "kill" } } filter { json { source => "message" remove_field => ["message"] } } output { if[type] == "user" { elasticsearch { hosts => ["localhost:9200"] index => "index_user" document_id => "%{id}" } } if[type] == "kill" { elasticsearch { hosts => ["localhost:9200"] index => "index_kill" document_id => "%{id}" } } stdout { codec => json_lines } }
可以看到在input下,我们又新增了一个jdbc。在jdbc中,我们新增了一个属性type,用来在output中做判断
在output中,我们没有传document_type,并且还使用了两个index。这是因为在elasticsearch6.0中,一个索引下只能有一个类型,不然会报错。这里我们可
同样的,我们使用cmd执行命令:logstash -f ../mysql/mysql.conf
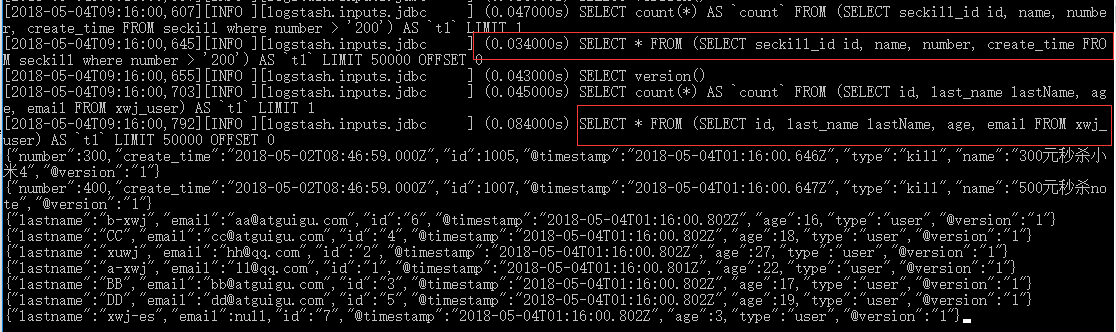
执行了两个sql脚本,其中那个带where条件的sql参数也传进去了
我们再来看elasticsearch-head中的数据:
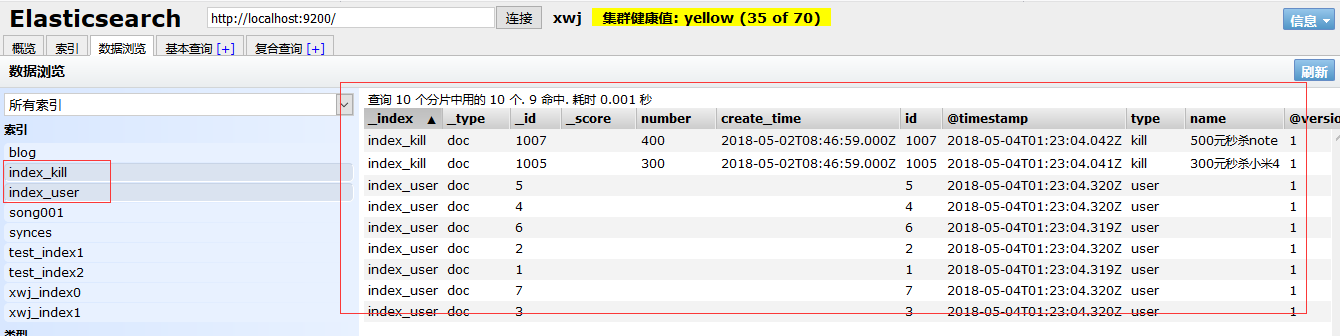
新增了两个索引index_kill、index_user。同时,每个索引下还有一个虚拟索引doc
踩过的坑
1、配置文件中,当在input的jdbc下,增加type属性时,会导致该索引下增加type字段。所以sql查询出的字段不要用type,如果有,as成其他的名字,不然的话,这里判断会有异常
2、同步多个表,elasticsearch6.0以上的版本,一定要设置多个索引