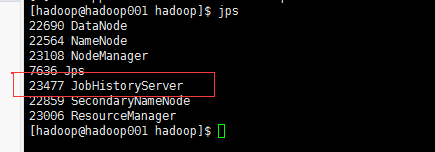
java.lang.Exception: Unknown container. Container either has not started or has already completed or doesn't belong to this node at all.
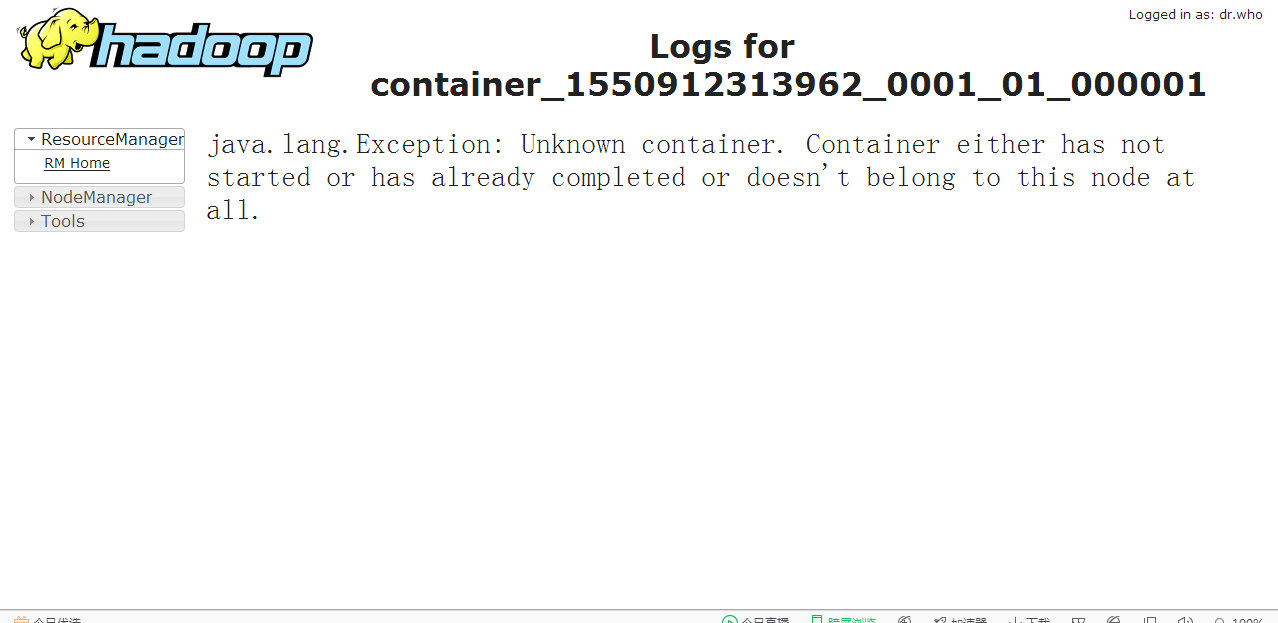
参考:https://blog.csdn.net/lisongjia123/article/details/78639058 但是这篇文章跟官网有一定的出入,我做了一定修正
解决方法
官方文档显示yarn的日志监控功能默认是处于关闭状态的,需要我们进行开启,开启步骤如下:
1.在yarn-site.xml文件中添加日志监控支持
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>

yarn.log-aggregation-enable官网中的默认值为false

2在mapred-site.xml文件中添加日志服务的配置
<property>
<!-- 表示提交到hadoop中的任务采用yarn来运行,要是已经有该配置则无需重复配置 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--日志监控服务的地址,一般填写为nodenode机器地址 -->
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
mapreduce.framework.name官网默认值是local

要让他在yarn上跑就把local改为yarn
mapreduce.jobhistory.webapp.address 和mapreduce.jobhistory.address值分别为默认0.0.0.0:19888 和0.0.0.0:10020

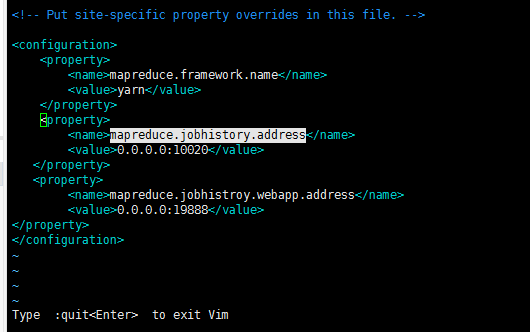
3.将修改后的配置文件拷贝到集群中的其他机器(单机版hadoop可以跳过该步骤)
快捷一点可以使用 scp 命令将配置文件拷贝覆盖到其他机器
scp yarn-site.xml skyler@slave1:/hadoopdir/etc/hadoop/
scp mapred-site.xml skyler@slave1:/hadoopdir/etc/hadoop/
…其他datanode机器同理
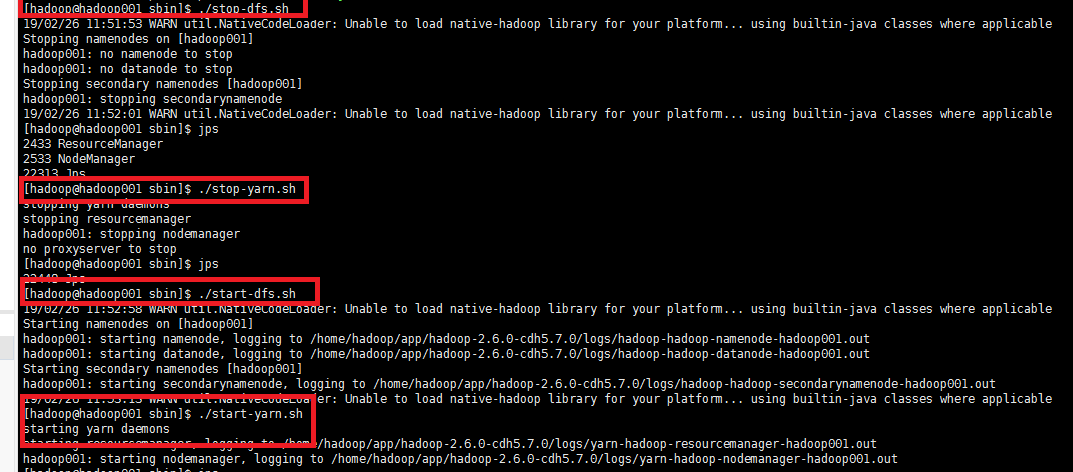
四、重新启动集群的Hdfs和Yarn服务
在namenode机器上分别对hdfs和yarn服务进行重启
bin/stop-dfs.sh
bin/start-dfs.sh
bin/stop-yarn.sh
bin/start-yarn.sh
五、 开启日志监控服务进程
在nodenode机器上执行 sbin/mr-jobhistory-daemon.sh start historyserver 命令,执行完成后使用jps命令查看是否启动成功,若启动成功则会显示出JobHistoryServer服务